Self-Supervised Learning.
自监督学习(Self-Supervised Learning)是一种无监督表示学习方法,旨在根据无标签数据集中的一部分信息预测剩余的信息,并以有监督的方式来训练该数据集。
自监督学习的优势包括:
- 能够充分利用大型无标签数据集,利用数据集本身以较低成本构造大量伪标签;
- 能够学习携带语义或结构信息的数据特征表示,从而有益于下游任务。
自监督学习已被广泛应用在自然语言处理任务中,比如语言模型默认的预训练任务就是根据过去的序列预测下一个单词。本文主要关注计算机视觉领域的自监督学习方法,即如何构造适用于图像数据集的自监督任务,包括:
- 前置任务(pretext task):通过从数据集中自动构造伪标签而设计的对目标任务有帮助的辅助任务,如Exemplar-CNN, Context Prediction, Jigsaw Puzzle, Image Colorization, Learning to Count, Image Rotation, Jigsaw Clustering, Evolving Loss, PIC, MP3。
- 对比学习(contrastive learning):学习一个特征嵌入空间使得正样本对彼此靠近、负样本对相互远离。(对比损失函数) NCE, CPC, CPC v2, Alignment and Uniformity, Debiased Contrastive Loss, Hard Negative Samples, FlatNCE; (并行数据增强) InvaSpread, SimCLR, SimCLRv2, BYOL, SimSiam, DINO, SwAV, PixContrast, Barlow Twins; (存储体) InstDisc, MoCo, MoCo v2, MoCo v3; (多模态) CMC, CLIP; (应用) CURL, CUT, Background Augmentation, FD。
- 掩码图像建模(masked image modeling):随机遮挡图像中的部分patch,并以自编码器的形式重构这部分patch,如BEiT, MAE, SimMIM, iBOT, ConvMAE, QB-Heat, LocalMIM, DeepMIM。
⭐扩展阅读:
- A critical analysis of self-supervision, or what we can learn from a single image:(arXiv1904)使用单张图像进行自监督学习。
1. 基于前置任务的自监督学习方法
前置任务(pretext task)也叫代理任务(surrogate task),是指通过从数据集中自动构造伪标签而设计的对目标任务有帮助的辅助任务。
⚪ Exemplar-CNN
Exemplar-CNN从图像数据集的梯度较大区域(通常覆盖边缘并包含目标的一部分)中采样$32 \times 32$大小的图像块;对每一个图像块应用不同的随机图像增强,同一个图像块的增强样本属于同一个代理类别;自监督学习的前置任务旨在对不同的代理类别进行分类。

⚪ Context Prediction
随机在图像中选取一个图像块;然后考虑以该图像块为中心的$3\times 3$网格,随机选择其$8$个邻域图像块中的一个;则自监督学习的前置任务是预测后者属于哪个邻域的八分类任务。

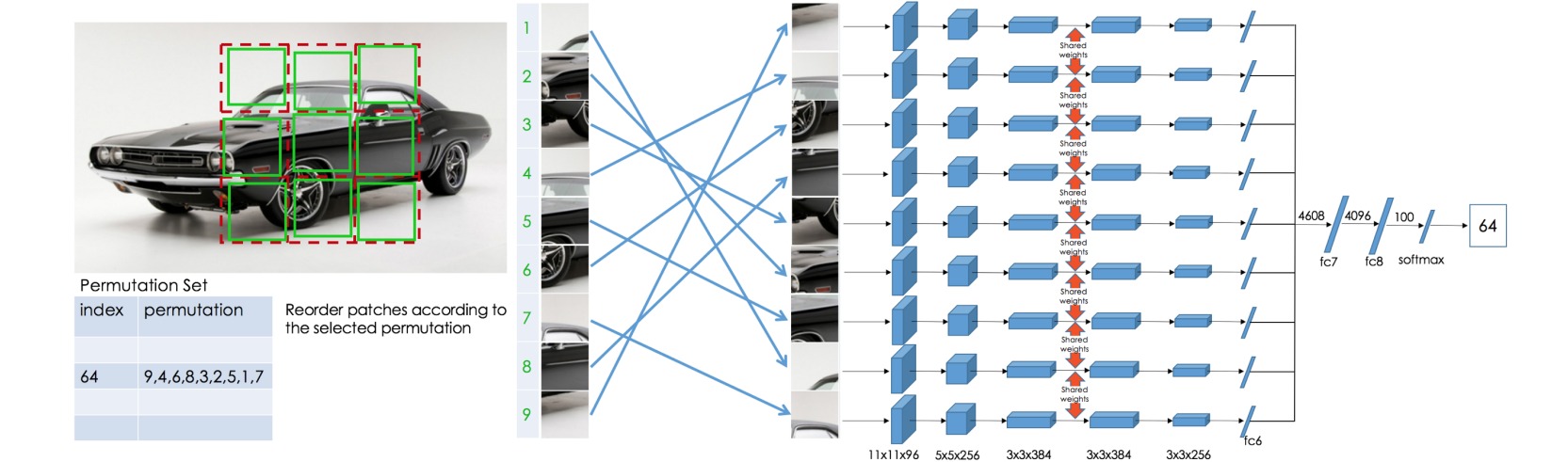
⚪ Jigsaw Puzzle
随机打乱图像中的九个图像块,通过共享权重的模型分别处理每一个图像块,并根据预定义的排列集合输出图像块排列的索引概率,则自监督学习的前置任务是一种多分类任务。
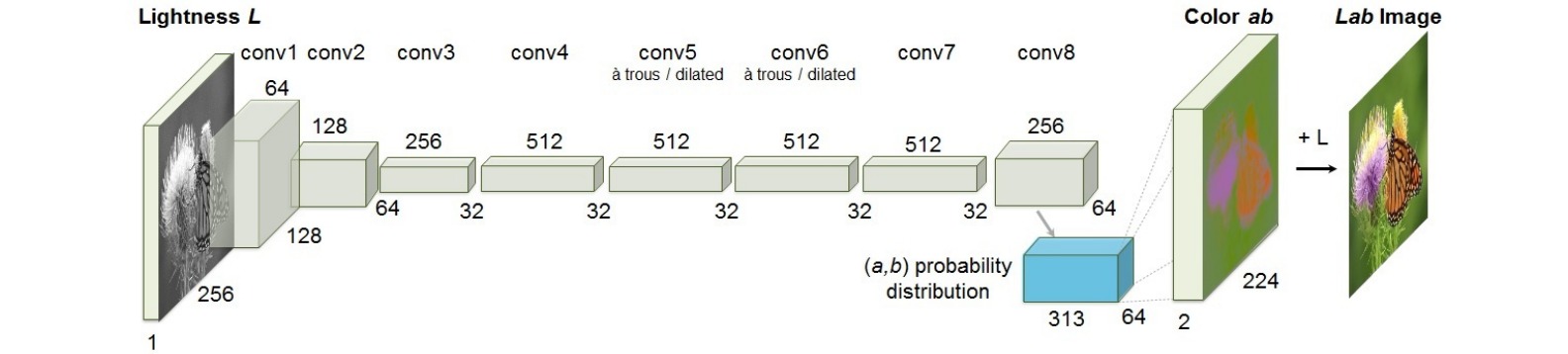
⚪ Image Colorization
着色是指把输入灰度图像转化为彩色图像,即将灰度图像映射到量化颜色值输出的分布上。彩色图像设置在Lab*颜色空间,其中取值$0$-$100$的整数值L匹配人眼对亮度的感知,ab值控制不同的颜色取值,量化为$313$种颜色对。则自监督学习的前置任务构造为在量化颜色值上预测概率分布的交叉熵损失。
⚪ Learning to Count
把图像的特征看作一种标量属性,如果把一幅图像划分成$2\times 2$的图像块,则四个图像块中特征的数量之和应该与原始图像的特征数量相同。把模型看作特征计数器$\phi(\cdot)$,对于输入图像$x$定义$2\times$下采样操作$D(\cdot)$和$2\times 2$图像块划分操作$T_i(\cdot),i=1,2,3,4$,则自监督学习的前置任务定义为如下目标函数:
\[\mathcal{L} = ||\phi(D \circ x) - \sum_{i=1}^4 \phi(T_i \circ x)||_2^2 + \max(0,c-||\phi(D \circ y) - \sum_{i=1}^4 \phi(T_i \circ x)||_2^2)\]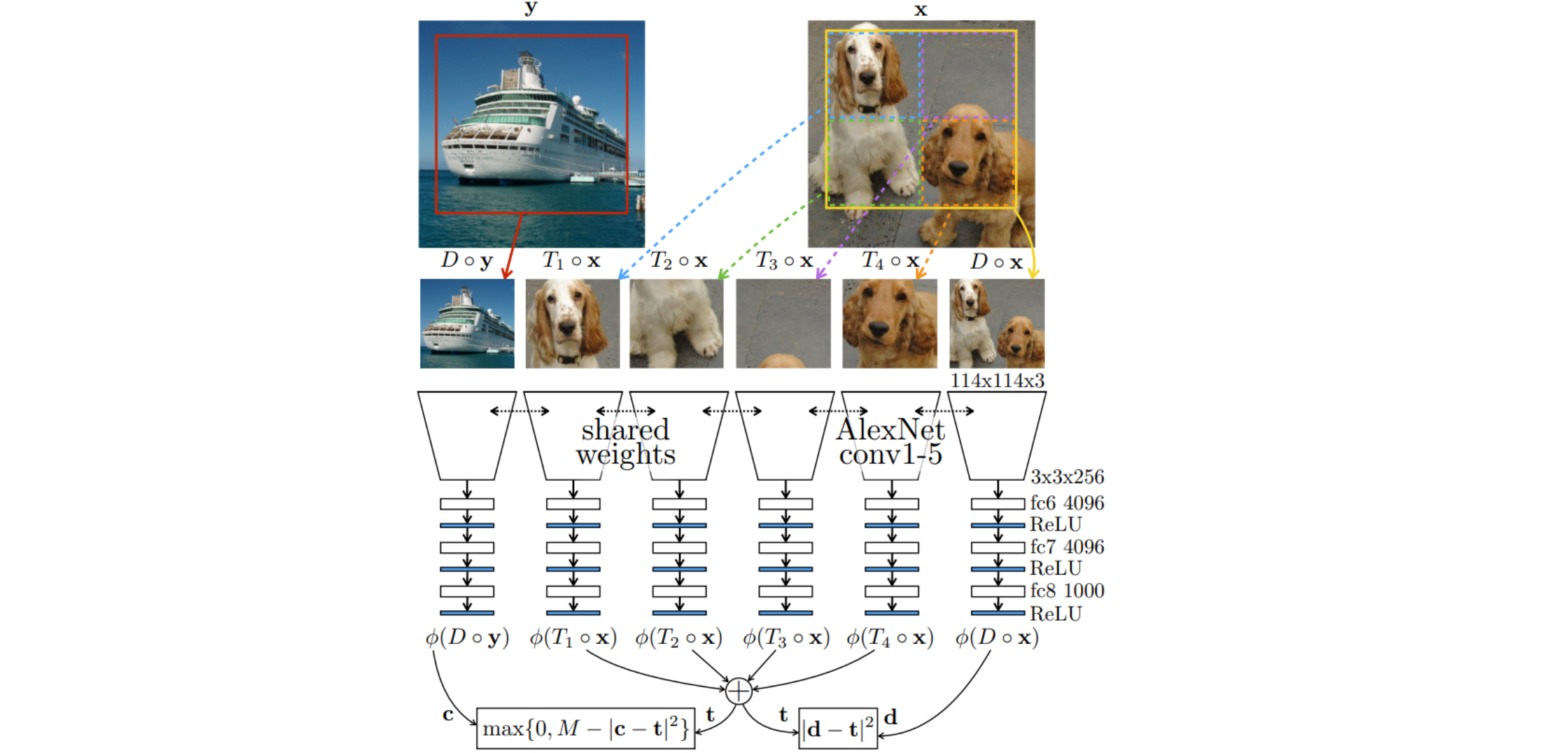
⚪ Image Rotation
对输入图像随机地旋转四种不同的角度:\([0^{\circ},90^{\circ},180^{\circ},270^{\circ}]\),则自监督学习的前置任务是预测图像旋转哪种角度的四分类任务。

⚪ Jigsaw Clustering
Jigsaw Clustering把一批图像拆分成$m\times m$的图像块,打乱后构成一批新的图像,并通过卷积网络提取每个图像块的特征。则自监督学习的前置任务包括:聚类损失:对于每一个图像块特征$z_i$,属于同一个原始图像的特征$z_j$为正样本,其余特征为负样本;定位损失:每个图像块的位置可以构造一个$mm$分类问题。

⚪ Evolving Loss
本文提出了一种用于视频表示学习的多模态多任务框架。该方法处理四种数据模态:RGB、光流图像、灰度图像和音频;对每种模态设置七种自监督学习任务;并且构建其他模态网络对处理RGB网络的数据蒸馏。

⚪ Parametric Instance Classification (PIC)
参数化实例分类PIC框架把每张输入图像作为一个类别,通过预测类别来进行特征学习。使用适当的策略如余弦Softmax损失、更强的数据增强与两层映射头网络之后,预训练性能有显著提高。

⚪ Masked Patch Position Prediction (MP3)
视觉Transformer接收一组图像patch,但不提供它们的位置信息;通过随机选择一个patch子集来计算注意力层的键矩阵和值矩阵。前置任务是预测每个输入位置的分类问题。

2. 基于对比学习的自监督学习方法
对比学习(Contrastive Learning)旨在学习一个特征嵌入空间,使得相似的样本对(正样本对)彼此靠近,不相似的样本对(负样本对)相互远离。在无监督形式的对比学习中,可以通过数据增强等方法构造样本对,从而实现有意义的特征表示学习。
(1)对比损失函数
对比学习中的损失函数可以追溯到监督学习中的深度度量学习,通过给定类别标签构造正负样本对,最小化正样本对$(x,x^+)$的嵌入距离,最大化负样本对$(x,x^-)$的嵌入距离。
⚪ Noise Contrastive Estimation (NCE)
噪声对比估计是一种统计模型的参数估计方法,其想法是运行逻辑回归来区分目标样本$x$和噪声\(\tilde{x}\)。逻辑回归模型$f(\cdot)$通过Sigmoid激活建模属于目标而不是噪声的概率,进而建立二元交叉熵损失:
\[\mathcal{L}_{NCE} = - \Bbb{E}_{x \text{~} p_{\text{data}}} [\log f(x)] - \Bbb{E}_{\tilde{x} \text{~} p_{\text{noise}}} [\log(1-f(\tilde{x}))]\]⚪ Contrastive Predictive Coding (CPC)
对比预测编码把二元NCE损失扩展为多元InfoNCE损失。给定上下文向量$c$,正样本通过$p(x|c)$构造,$N-1$个负样本通过$p(x)$构造;使用类别交叉熵损失区分正样本和噪声样本:
\[\begin{aligned} \mathcal{L}_{InfoNCE} &= - \Bbb{E}_{x \text{~} p_{\text{data}}} [\log\frac{f(x,c)}{\sum_{x' \text{~} p_{\text{data}}} f(x',c)}] \\ &= - \Bbb{E}_{x,x^+,\{x^-_i\}_{i=1}^N} [\log\frac{e^{f(x)^Tf(x^+)}}{e^{f(x)^Tf(x^+)}+\sum_{i=1}^N e^{f(x)^Tf(x^-_i)}}] \end{aligned}\]⚪ CPC v2
把InfoNCE应用到图像数据集中,把输入图像$x$的每个图像块压缩为潜在表示$z_{i,j}$,从中构造上下文特征$c_{i,j}=g_{\phi}(z_{\leq i,\leq j})$,并进一步预测潜在表示\(\hat{z}_{i+k,j} = W_kc_{i,j}\)。
\[\begin{aligned} \mathcal{L}_N = - \sum_{i,j,k} \log\frac{\exp(\hat{z}_{i+k,j}^Tz_{i+k,j})}{\exp(\hat{z}_{i+k,j}^Tz_{i+k,j}) + \sum_l \exp(\hat{z}_{i+k,j}^Tz_{l})} \end{aligned}\]⚪ Alignment and Uniformity
对比学习的损失函数具有两种性质:对齐性(Alignment)和一致性(Uniformity)。对齐性用于衡量正样本对之间的相似程度;一致性用于衡量归一化的特征在超球面上分布的均匀性。
\[\begin{aligned} \mathcal{L}_{align}(f;\alpha) &= \Bbb{E}_{(x,y)\text{~}p_{pos}} [||f(x)-f(y)||_2^{\alpha}] \\ \mathcal{L}_{uniform}(f;t) &= \log \Bbb{E}_{(x,y)\text{~}p_{data}} [e^{-t||f(x)-f(y)||_2^2}] \end{aligned}\]⚪ Debiased Contrastive Loss
由于样本的真实标签是未知的,因此负样本可能采样到假阴性样本。在构造对比损失时,对负样本项进行偏差修正:
\[g(x,\{u_i\}_{i=1}^N,\{v_i\}_{i=1}^M) = \max(\frac{1}{\eta^-}(\frac{1}{N}\sum_{i=1}^N \exp(f(x)^Tf(u_i))-\frac{\eta^+}{M}\sum_{i=1}^M \exp(f(x)^Tf(v_i))),\exp(-1/\tau)) \\ \mathcal{L}_{unbiased} = \Bbb{E}_{x,\{u_i\}_{i=1}^N\text{~}p;x^+,\{v_i\}_{i=1}^M\text{~}p_x^+} [-\log \frac{\exp(f(x)^Tf(x^+))}{\exp(f(x)^Tf(x^+))+Ng(x,\{u_i\}_{i=1}^N,\{v_i\}_{i=1}^M)}]\]⚪ Hard Negative Samples
对对比损失中的负样本对项\(\exp(f(x)^Tf(x^-))\)进行加权,权重正比于负样本与anchor样本的相似度,设置为:
\[\frac{\beta \exp(f(x)^Tf(x^-))}{\sum_{x^-} \exp(f(x)^Tf(x^-))}\]⚪ FlatNCE
对比学习损失在批量较小时效果较差的原因之一是损失和梯度计算的浮点误差。把对比损失修改为:
\[\begin{aligned} \mathcal{L}_{FlatNCE} &= - \Bbb{E}_{x,x^+,\{x^-_i\}_{i=1}^N} [\log\frac{e^{f(x)^Tf(x^+)}}{\sum_{i=1}^N e^{f(x)^Tf(x^-_i)}}] \end{aligned}\](2)并行数据增强 Parallel Augmentation
基于并行数据增强的对比学习方法为anchor样本同时生成两个数据增强样本,并使得它们共享相同的特征表示。
⚪ Invariant and Spreading Instance Feature (InvaSpread)
InvaSpread对于一批样本进行数据增强,把样本$x$的增强样本\(\hat{x}\)视为正样本,其余所有样本视为负样本;正样本特征应具有不变性,负样本特征应尽可能地分开。
\[\mathcal{L}_{\text{InvaSpread}} = -\sum_i \log \frac{\exp(f_i^T\hat{f}_i/\tau)}{\sum_{k=1}^N\exp(f_k^T\hat{f}_i/\tau)}-\sum_i \sum_{j\neq i} \log(1- \frac{\exp(f_i^Tf_j/\tau)}{\sum_{k=1}^N\exp(f_k^Tf_j/\tau)})\]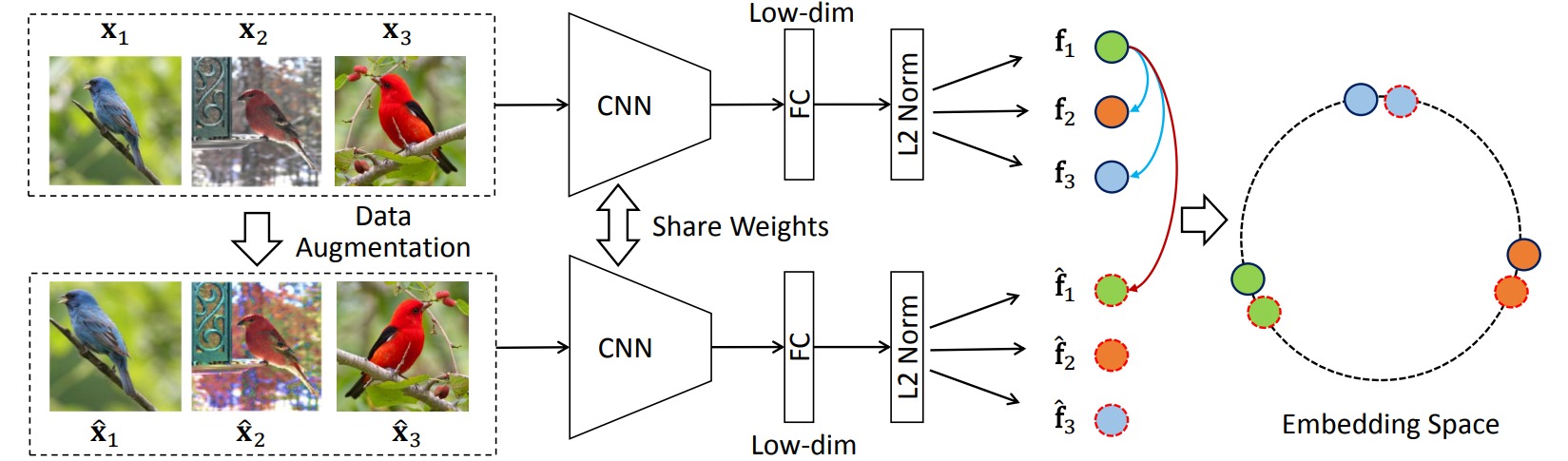
⚪ Simple Framework for Contrastive Learning of Visual Representation (SimCLR)
SimCLR随机采样$N$个数据样本,对每个样本应用两次同一类的不同数据增强,构造$2N$个增强样本;对于任意样本\(\tilde{x}_i\),\(\tilde{x}_j\)为正样本,其余$2(N-1)$个样本为负样本。通过编码网络$f(\cdot)$和映射层$g(\cdot)$提取特征表示,并构造对比损失:
\[\mathcal{L}^{(i,j)}_{\text{SimCLR}} = -\log \frac{\exp(\text{sim}(z_i,z_j)/\tau)}{\sum_{k=1,...,2N;k\neq i}\exp(\text{sim}(z_i,z_k)/\tau)}\]
⚪ SimCLRv2
SimCLRv2在SimCLR的基础上采用更大的卷积网络和更深的映射头,并通过微调和数据蒸馏实现半监督学习:

⚪ Bootstrap your own latent (BYOL)
BYOL没有构建负样本对,而是使用参数为$\theta$的在线网络和参数为$\xi$的目标网络分别从图像$x$的两个增强版本中提取特征$z,z’$,根据$z$预测$z’$(或交换顺序后根据$z’$预测$z$)。损失函数设置为归一化特征的均方误差损失,更新参数$\theta$,参数$\xi$是参数$\theta$的滑动平均:\(\xi \leftarrow \tau \xi + (1-\tau)\theta\)。
\[\begin{aligned} \mathcal{L}_{\text{BYOL}} \propto -2(\frac{<q_{\theta}(z_{\theta}),z'_{\xi}>}{||q_{\theta}(z_{\theta})||_2 \cdot ||z'_{\xi}||_2}+\frac{<q_{\theta}(z'_{\theta}),z_{\xi}>}{||q_{\theta}(z'_{\theta})||_2 \cdot ||z_{\xi}||_2}) \end{aligned}\]
⚪ Simple Siamese Representation Learning (SimSiam)
SimSiam使用孪生网络$f$从图像$x$的两个增强版本$x_1,x_2$中提取特征$z_1,z_2$,并使用预测头$h$根据一个特征预测另一个特征。损失函数设置为负余弦相似度:
\[\begin{aligned} \mathcal{L}_{\text{SimSiam}} = -\frac{1}{2} \frac{h(z_1)}{||h(z_1)||_2} \cdot \frac{sg(z_2)}{||sg(z_2)||_2} -\frac{1}{2} \frac{h(z_2)}{||h(z_2)||_2} \cdot \frac{sg(z_1)}{||sg(z_1)||_2} \end{aligned}\]
⚪ Self-distillation with no labels (DINO)
DINO使用学生网络$f_s$和滑动平均更新的教师网络$f_t$从图像$x$的两个增强版本$x_1,x_2$中提取特征$f_s(x_1),f_t(x_2)$。为教师网络的预测特征引入centering操作,然后把特征$f_s(x_1),f_t(x_2)$通过softmax函数映射为概率分布。则损失函数构建为两个概率分布的交叉熵:
\[\mathcal{L}_{\text{DINO}} = -p_t(x_2) \log p_s(x_1) -p_t(x_1) \log p_s(x_2)\]
⚪ Swapping Assignments between multiple Views (SwAV)
SwAV使用样本特征和预定义的$K$个原型向量(聚类中心) \(C=\{c_1,...,c_K\}\)进行对比学习。给定两个数据样本$x_t,x_s$,构造特征向量$z_t,z_s$,并进一步构造编码$q_t,q_s$。则损失函数定义为聚类预测和编码之间的交叉熵:
\[\mathcal{L}_{\text{SwAV}} = -\sum_k q_s^{(k)} \log \frac{\exp(z_t^Tc_k/ \tau)}{\sum_{k'} \exp(z_t^Tc_{k'}/ \tau)} -\sum_k q_t^{(k)} \log \frac{\exp(z_s^Tc_k/ \tau)}{\sum_{k'} \exp(z_s^Tc_{k'}/ \tau)}\]
⚪ Pixel-level Contrastive Learning (PixContrast)
PixContrast是一种像素级的对比学习方法。对于一幅图像中的目标,分别选取两个子图像,则两个图像中对应同一个目标位置的像素可以看作正样本对。

⚪ Barlow Twins
Barlow Twins把数据样本$x$的两个增强版本$x^A,x^B$喂入同一个神经网络以提取特征表示$z^A,z^B$,并使得两组输出特征的互相关矩阵\(\mathcal{C}\)接近单位矩阵。
\[\mathcal{L}_{\text{BT}} = \sum_i (1-\mathcal{C}_{ii})^2 + \lambda \sum_i \sum_{j\neq i} \mathcal{C}_{ij}^2 , \quad \mathcal{C}_{ij} = \frac{\sum_bz^A_{b,i}z^B_{b,j}}{\sqrt{\sum_b(z_{b,i}^A)^2}\sqrt{\sum_b(z^B_{b,j})^2}}\]
(3)存储体 Memory Bank
基于存储体(Memory Bank)的对比学习方法把所有样本的特征向量存储在内存中,以减小计算开销。
⚪ Instance-level Discrimination (InstDisc)
InstDisc把每一个数据样本看作一个类别,把样本的特征向量\(V=\{v_i\}\)存储在Memory Bank中。每次更新时从Memory Bank中采样负样本,采用NCE的形式区分不同样本类别:
\[\begin{aligned} \mathcal{L}_{InstDisc} = &- \Bbb{E}_{p_{\text{data}}} [\log h(i,v_i^{(t-1)})-\lambda ||v_i^{(t)}-v_i^{(t-1)}||_2^2] \\ & - M \cdot \Bbb{E}_{P_N} [\log(1-h(i,v'^{(t-1)}))] \end{aligned}\]
⚪ Momentum Contrast (MoCo)
MoCo通过编码器$f_q(\cdot)$构造查询样本$x_q$的查询表示$q=f_q(x_q)$,通过滑动平均更新的矩编码器$f_k(\cdot)$构造键表示$k_i=f_k(x_k^i)$,并维持一个存储键表示的先入先出队列。
\[\mathcal{L}_{\text{MoCo}} = -\log \frac{\exp(q \cdot k^+/\tau)}{\sum_{i=0}^{N}\exp(q \cdot k_i/\tau)}\]
⚪ MoCo v2
MoCo v2在MoCo的基础上引入了映射头、采用更多数据增强、余弦学习率策略和更长的训练轮数。
⚪ MoCo v3
MoCo v3把矩对比方法应用到视觉Transformer的自监督训练中,没有采取MoCo中的队列设计,而是根据每批样本构造正负样本对,并在编码器后引入预测头。
给定一批样本$x$,分别做两次数据增强得到$x_1,x_2$,通过编码器构造$q_1,q_2$,通过矩编码器构造$k_1,k_2$。则对比损失对称地构造为:
\[\mathcal{L}_{\text{MoCov3}} = -\log \frac{\exp(q_1 \cdot k_2^+/\tau)}{\sum_{i=0}^{N}\exp(q_1 \cdot k_2^i/\tau)}-\log \frac{\exp(q_2 \cdot k_1^+/\tau)}{\sum_{i=0}^{N}\exp(q_2 \cdot k_1^i/\tau)}\](4)多模态 Multi-Modality
⚪ Contrastive Multiview Coding (CMC)
CMC把来自不同传感器的多模态数据之间视为正样本,对于样本$x$的$M$种不同的模态,可构造任意两种模态之间的对比损失:
\[\mathcal{L}^{(i,j)}_{\text{CMC}} = -\log \frac{\exp(f(v_i)^Tf(v_j)/\tau)}{\sum_{k}\exp(f(v_i)^Tf(v_j^k)/\tau)} -\log \frac{\exp(f(v_j)^Tf(v_i)/\tau)}{\sum_{k}\exp(f(v_j)^Tf(v_i^k)/\tau)}\]
⚪ Contrastive Language-Image Pre-training (CLIP)
CLIP方法用于在图像和文本数据集中进行匹配。给定$N$个图像-文本对,首先计算任意一个图像和文本之间的余弦相似度矩阵,尺寸为$N \times N$;通过交叉熵损失使得匹配的$N$个图像-文本对的相似度最大,其余$N(N-1)$个相似度最小。

(5)应用 Applications
⚪ Contrastive Unsupervised Representations for Reinforcement Learning (CURL)
CURL把对比学习应用到强化学习领域。它采用MoCo方法学习强化学习任务的视觉表示,通过随机裁剪构造观测$o$的两个数据增强版本$o_q,o_k$。

⚪ Contrastive Unpaired Translation (CUT)
CUT是一种基于对比学习的图像到图像翻译方法。它构造输入图像$x$和生成图像$\hat{y}$特征的PatchNCE损失:特征的每个像素位置对应原始图像的一个图像块;则两个相同位置的特征向量为正样本对,其余位置的特征向量为负样本。

⚪ Background Augmentation
Background Augmentation是一种增强对比学习的性能表现的数据增强策略。使用显著性图生成方法提取图像的前景区域,并调整图像的背景区域。

⚪ Feature Distillation (FD)
对于任意基于对比的自监督预训练模型,FD使用特征作为蒸馏的目标,已经学习到的特征会再被蒸馏成为全新的特征。通过引入白化蒸馏目标 ,共享相对位置编码以及非对称的 Drop Path 率,基于对比的自监督预训练方法的微调性能达到与掩码图像建模方法相当的表现。

3. 基于掩码图像建模的自监督学习方法
随着计算机视觉的主流架构从卷积神经网络过度到视觉Transformer,图像可以被表示为一系列patch token,因此自然地引入token-level的自监督方法,即掩码图像建模(masked image modeling, MIM)。掩码图像建模是指随机遮挡图像中的部分patch,并以自编码器的形式重构这部分patch。
⭐扩展阅读:
- Revealing the Dark Secrets of Masked Image Modeling:揭露掩码图像建模方法的有效性。
- On Data Scaling in Masked Image Modeling:探究掩码图像建模中的数据可扩展性。
⚪ BEiT
BEiT使用dVAE将图像Patch编码成视觉Token,使用BERT预测图像掩码部分对应的视觉Token。

⚪ Masked Autoencoder (MAE)
MAE采用非对称的编码器-解码器结构。编码器只对未遮挡的图像块进行操作;解码器从编码特征和遮挡token中重建整个图像。

⚪ SimMIM
SimMIM随机mask图像的一部分patches,并直接回归预测这部分patches的原始像素 RGB 值。

⚪ iBOT
iBOT通过参数滑动平均构造在线 tokenizer,通过构造mask与unmask版本输出token的自蒸馏损失捕捉高层语义的特性。

⚪ ConvMAE
ConvMAE把模型架构设置为多尺度的金字塔式架构,对于编码器使用卷积+Transformer结合的模型。

⚪ QB-Heat
QB-Heat每次只输入一小部分图像,经过编码器后得到对应的特征,通过下列方程组来预测完整图像的特征,然后将特征传入一个较小的解码器来重建完整图像。
\[z(x+\Delta x, y) \approx z(x,y) + \Delta x A z(x,y) = (I+\Delta x A) z(x,y)\\ z(x, y+\Delta y) \approx z(x,y) + \Delta y B z(x,y) = (I+\Delta y B) z(x,y)\]
⚪ LocalMIM
LocalMIM将重构任务引入多个选择的局部层,并提出多尺度重构:较低层重构细尺度信息,较高层重构粗尺度信息。

⚪ DeepMIM
DeepMIM在 Masked Image Modeling 训练过程中加上 Deep Supervision,可以促进浅层学习更有意义的表示。

⭐ 参考文献
- Self-Supervised Representation Learning(Lil’Log)一篇介绍自监督学习的博客。
- Awesome Self-Supervised Learning:(github) A curated list of awesome self-supervised methods.
- An Overview of Deep Semi-Supervised Learning:(arXiv2006)一篇深度半监督学习的综述。
- Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks:(arXiv1406)通过Exemplar-CNN实现判别无监督特征学习。
- Unsupervised Visual Representation Learning by Context Prediction:(arXiv1505)通过上下文预测实现无监督视觉表示学习。
- Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles:(arXiv1603)通过解决拼图问题实现无监督视觉表示学习。
- Colorful Image Colorization:(arXiv1603)通过彩色图像着色实现无监督特征学习。
- Representation Learning by Learning to Count:(arXiv1708)通过学习计数实现无监督表示学习。
- Unsupervised Representation Learning by Predicting Image Rotations:(arXiv1803)通过预测图像旋转角度实现无监督表示学习。
- Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination:(arXiv1805)通过非参数化实例级判别实现无监督特征学习。
- Representation Learning with Contrastive Predictive Coding:(arXiv1807)通过对比预测编码进行表示学习。
- Unsupervised Embedding Learning via Invariant and Spreading Instance Feature:(arXiv1904)通过不变和扩散的实例特征实现无监督嵌入学习。
- Data-Efficient Image Recognition with Contrastive Predictive Coding:(arXiv1905)通过对比预测编码实现数据高效的图像识别。
- Contrastive Multiview Coding:(arXiv1906)对比多视角编码。
- Momentum Contrast for Unsupervised Visual Representation Learning:(arXiv1911)MoCo:无监督视觉表示学习的矩对比。
- Evolving Losses for Unsupervised Video Representation Learning:(arXiv2002)无监督视频表示学习的进化损失。
- A Simple Framework for Contrastive Learning of Visual Representations:(arXiv2002)SimCLR:一种视觉对比表示学习的简单框架。
- Improved Baselines with Momentum Contrastive Learning:(arXiv2003)MoCo v2:改进矩对比学习。
- CURL: Contrastive Unsupervised Representations for Reinforcement Learning:(arXiv2004)CURL:强化学习的对比无监督表示。
- Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere:(arXiv2005)通过超球面上的对齐和一致性理解对比表示学习。
- Parametric Instance Classification for Unsupervised Visual Feature Learning:(arXiv2006)无监督视觉特征学习的参数化实例分类。
- Big Self-Supervised Models are Strong Semi-Supervised Learners:(arXiv2006)SimCLRv2:自监督大模型是强半监督学习器。
- Bootstrap your own latent: A new approach to self-supervised Learning:(arXiv2006)BYOL:通过在隐空间应用自举法实现自监督学习。
- Unsupervised Learning of Visual Features by Contrasting Cluster Assignments:(arXiv2006)SwAV:通过对比聚类指派实现无监督视觉特征学习。
- Exploring Simple Siamese Representation Learning:(arXiv2006)SimSiam:探索简单的孪生表示学习。
- Debiased Contrastive Learning:(arXiv2007)偏差修正的对比学习。
- Contrastive Learning for Unpaired Image-to-Image Translation:(arXiv2007)无配对数据图像到图像翻译中的对比学习。
- Contrastive Learning with Hard Negative Samples:(arXiv2010)使用难例负样本进行对比学习。
- Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning:(arXiv2011)探索无监督视觉表示学习中的像素级一致性。
- Barlow Twins: Self-Supervised Learning via Redundancy Reduction:(arXiv2103)Barlow Twins:通过冗余度消除实现自监督学习。
- Learning Transferable Visual Models From Natural Language Supervision:(arXiv2103)CLIP: 对比语言图像预训练。
- Characterizing and Improving the Robustness of Self-Supervised Learning through Background Augmentations:(arXiv2103)通过背景增强改进自监督学习的鲁棒性。
- An Empirical Study of Training Self-Supervised Vision Transformers:(arXiv2104)MoCo v3:训练自监督视觉Transformer的经验性研究。
- Emerging Properties in Self-Supervised Vision Transformers:(arXiv2104)DINO:自监督视觉Transformer的新特性。
- Jigsaw Clustering for Unsupervised Visual Representation Learning:(arXiv2104)无监督视觉表示学习的拼图聚类方法。
- BEiT: BERT Pre-Training of Image Transformers:(arXiv2107)BEiT:图像Transformer中的BERT预训练。
- Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE:(arXiv2107)FlatNCE: 避免浮点数误差的小批量对比学习损失函数。
- Masked Autoencoders Are Scalable Vision Learners:(arXiv2111)MAE: 掩码自编码器是可扩展的视觉学习者。
- SimMIM: A Simple Framework for Masked Image Modeling:(arXiv2111)SimMIM:一种掩码图像建模的简单框架。
- iBOT: Image BERT Pre-Training with Online Tokenizer:(arXiv2111)iBOT:使用在线标志进行图像BERT预训练。
- ConvMAE: Masked Convolution Meets Masked Autoencoders:(arXiv2205)ConvMAE:结合掩码卷积与掩码自编码器。
- Revealing the Dark Secrets of Masked Image Modeling:(arXiv2205)揭露掩码图像建模方法的有效性。
- Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation:(arXiv2205)特征蒸馏使对比学习在微调时击败了掩码图像建模。
- On Data Scaling in Masked Image Modeling:(arXiv2206)探究掩码图像建模中的数据可扩展性。
- Position Prediction as an Effective Pretraining Strategy:(arXiv2207)位置预测作为高效的预训练策略。
- Self-Supervised Learning based on Heat Equation:(arXiv2211)基于热传导方程的自监督学习。
- Masked Image Modeling with Local Multi-Scale Reconstruction:(arXiv2305)通过局部多尺度重构进行掩码图像建模。
- DeepMIM: Deep Supervision for Masked Image Modeling:(arXiv2305)DeepMIM:掩码图像建模中的深度监督。


