SimCLRv2:自监督大模型是强半监督学习器.
本文提出了一种融合自监督预训练(self-supervised pretraining)、监督微调(supervised fine-tuning)和半监督自训练(self-training)技术的流程:
- 首先通过自监督或者无监督方法预训练一个大模型,使用大型(深度和宽度)神经网络非常重要;
- 使用一些标记样本对模型进行监督微调,更大的模型能够使用更少的标记样本获得更好的性能;
- 通过自训练技术中的伪标签方法使用未标记样本进行蒸馏。

自监督模型选用SimCLR,在此基础上设置更大的卷积网络和更深的映射头,并构造对比损失:
\[\mathcal{L}^{(i,j)}_{\text{SimCLR}} = \log \frac{\exp(\text{sim}(z_i,z_j)/\tau)}{\exp(\sum_{k=1,...,2N;k\neq i}\text{sim}(z_i,z_k)/\tau)}\]在蒸馏过程中需要把知识从一个大模型迁移到一个小模型,因为针对特定任务不需要网络具有额外的学习表示能力。记教师网络权重\(\hat{\theta}_T\),学生网络权重$\theta_S$,则总损失包括有标签数据的监督损失和使用自监督预训练模型的蒸馏损失:

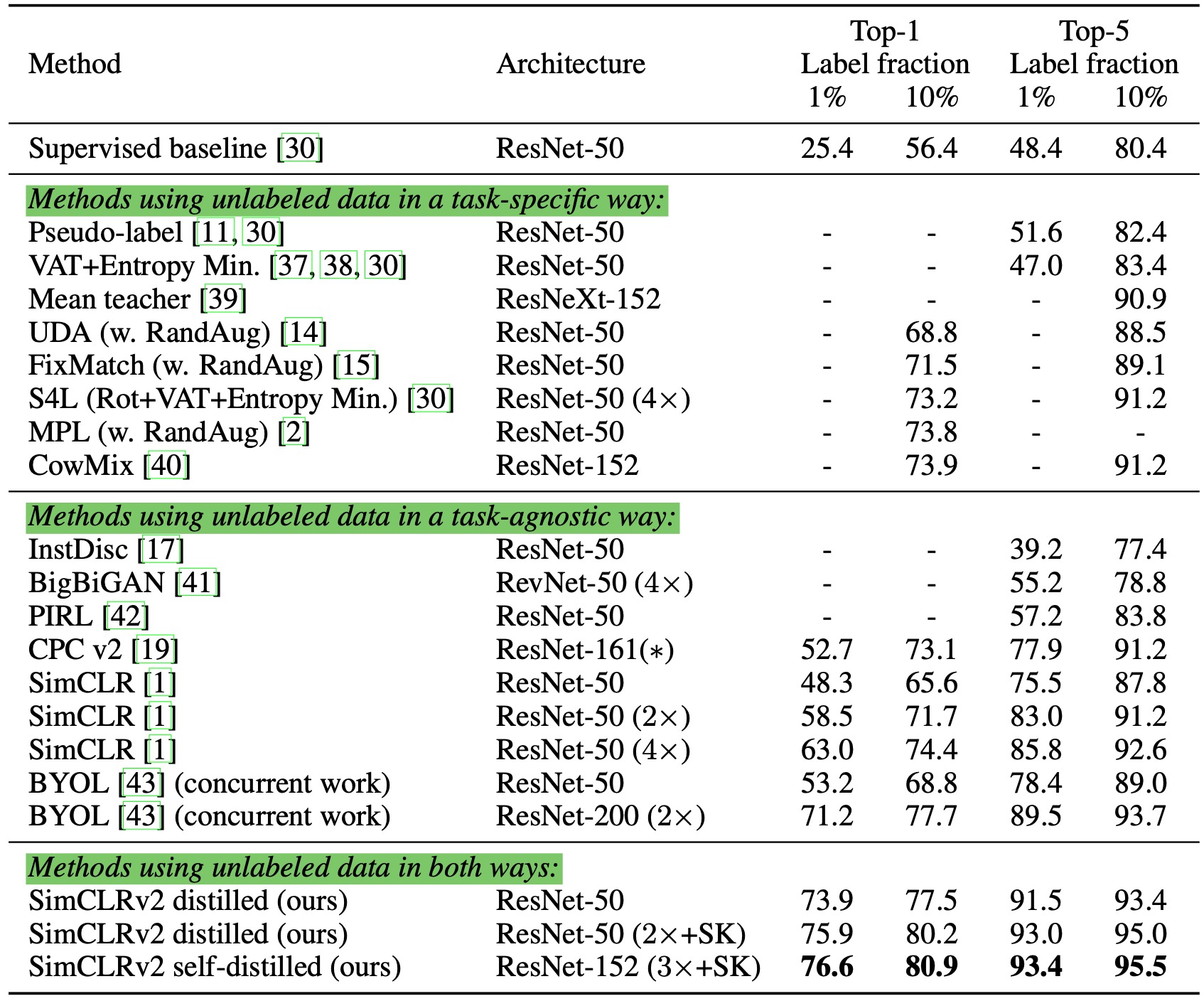
实验结果表明,采用更大的预训练模型进行自监督预训练,能够提高后续监督微调的表现。作者选用$152$层的ResNet,并且在网络中引入了SKNet注意力机制:

并且大模型通常更加标签高效(label-efficient):

当有标签数据较少时,采用更深的映射头能够提高表现;此外当有标签数据比例不同时,从映射头的不同层级进行微调模型的表现也具有差异。作者选用两层映射头(MLP+ReLU+MLP+ReLU)。

作者在ImageNet分类任务上进行实验,实验结果表明使用未标记数据进行蒸馏能够提高半监督学习。