SimCLR:一种视觉对比表示学习的简单框架.
SimCLR是一种视觉对比表示学习的简单框架,它通过最大化同一个样本的不同数据增强版本的一致性(即最小化特征隐空间中的对比损失)从视觉输入中学习特征表示。

SimCLR的实现过程如下。首先随机采样$N$个数据样本,对每个样本应用两次同一类的不同数据增强,构造$2N$个增强样本:
\[\tilde{x}_i = t(x),\tilde{x}_j = t'(x),\quad t,t' \text{~} \mathcal{T}\]数据增强选用随机裁剪、随机翻转和缩放、颜色变形和高斯模糊。对于任意样本\(\tilde{x}_i\),\(\tilde{x}_j\)为正样本,其余$2(N-1)$个样本为负样本。通过编码网络$f(\cdot)$提取特征表示:
\[h_i = f(\tilde{x}_i),h_j=f(\tilde{x}_j)\]进一步通过一个映射层$g(\cdot)$构造特征:
\[z_i = g(h_i),z_j=g(h_j)\]其中特征$h$用于下游任务;特征$z$用于对比学习。对比损失通过余弦相似度\(\text{sim}(u,v)=u^Tv/\|u\|\|v\|\)定义,样本\(\tilde{x}_i\)的对比损失构造为:
\[\mathcal{L}^{(i,j)}_{\text{SimCLR}} =- \log \frac{\exp(\text{sim}(z_i,z_j)/\tau)}{\sum_{k=1,...,2N;k\neq i}\exp(\text{sim}(z_i,z_k)/\tau)}\]
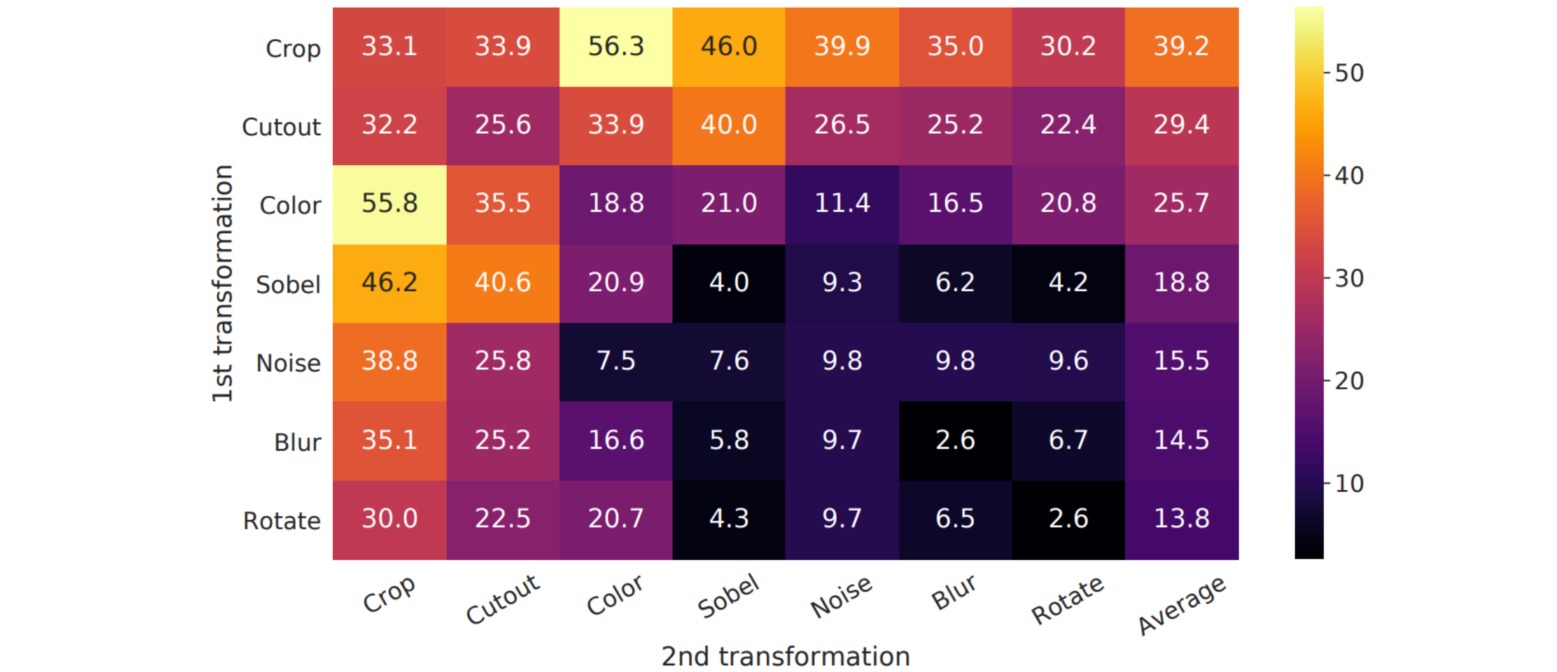
SimCLR的实验表明,数据增强策略对于对比学习任务非常重要。为此作者研究了大量常见的图像增强方法,包括裁剪、颜色变换、旋转、Cutout、高斯噪声和平滑、Sobel边缘检测算子等。

作者对上述数据增强的两两组合分别进行实验,结果表明随机裁剪和随机颜色变换的组合对于学习较好的图像视觉表示至关重要,其他图像增强方法算是锦上添花。
SimCLR需要较大的批量大小以涵盖足够的负样本才能获得良好的性能,大批量的训练采用LARS优化器。

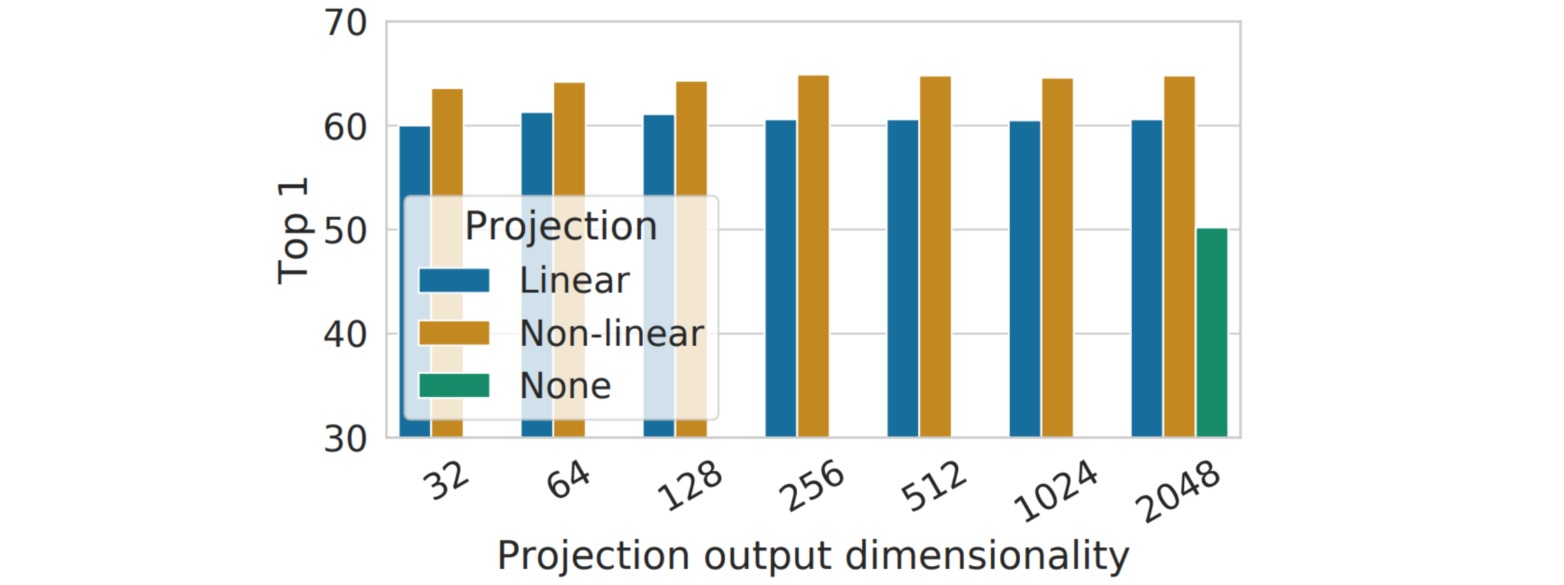
SimCLR使用的特征提取网络为ResNet50,因此构造的特征维度是$2048$;引入非线性映射头(单层MLP+ReLU)后把特征维度调整为$128$;实验结果表明加入非线性映射头后性能有比较明显的提升,并且模型对映射头的特征维度设置并不敏感。