DINO:自监督视觉Transformer的新特性.
Self-distillation with no labels (DINO)是一种为视觉Transformer设计的对比学习方法。该方法没有使用负样本,而是采用一种自蒸馏策略。

使用学生网络$f_s$和教师网络$f_t$从图像$x$的两个增强版本$x_1,x_2$中提取特征$f_s(x_1),f_t(x_2)$,教师网络$f_t$的参数$\theta_t$为学生网络参数$\theta_s$的滑动平均值$\theta_t \leftarrow m \theta_t + (1-m)\theta_s$。
为防止训练过程的模式崩溃(即学生网络和教师网络预测完全一致的结果),为教师网络的预测特征引入centering操作,即特征减去历史特征的滑动平均值:
\[\begin{aligned} c &\leftarrow m c + (1-m)f_t(x_2) \\ f_t(x_2) &\leftarrow f_t(x_2)-c \end{aligned}\]把特征$f_s(x_1),f_t(x_2)$通过softmax函数映射为概率分布:
\[\begin{aligned} p_s(x_1)^{i} = \frac{\exp(f_s(x_1)^i/\tau_s)}{\sum_k \exp(f_s(x_1)^k/\tau_s)} \\ p_t(x_2)^{i} = \frac{\exp(f_t(x_2)^i/\tau_t)}{\sum_k \exp(f_t(x_2)^k/\tau_t)} \end{aligned}\]则损失函数构建为两个概率分布的交叉熵(设计为对称形式):
\[\mathcal{L}_{\text{DINO}} = -p_t(x_2) \log p_s(x_1) -p_t(x_1) \log p_s(x_2)\]DINO的完整流程如下:

DINO中的映射头结构设计如下:
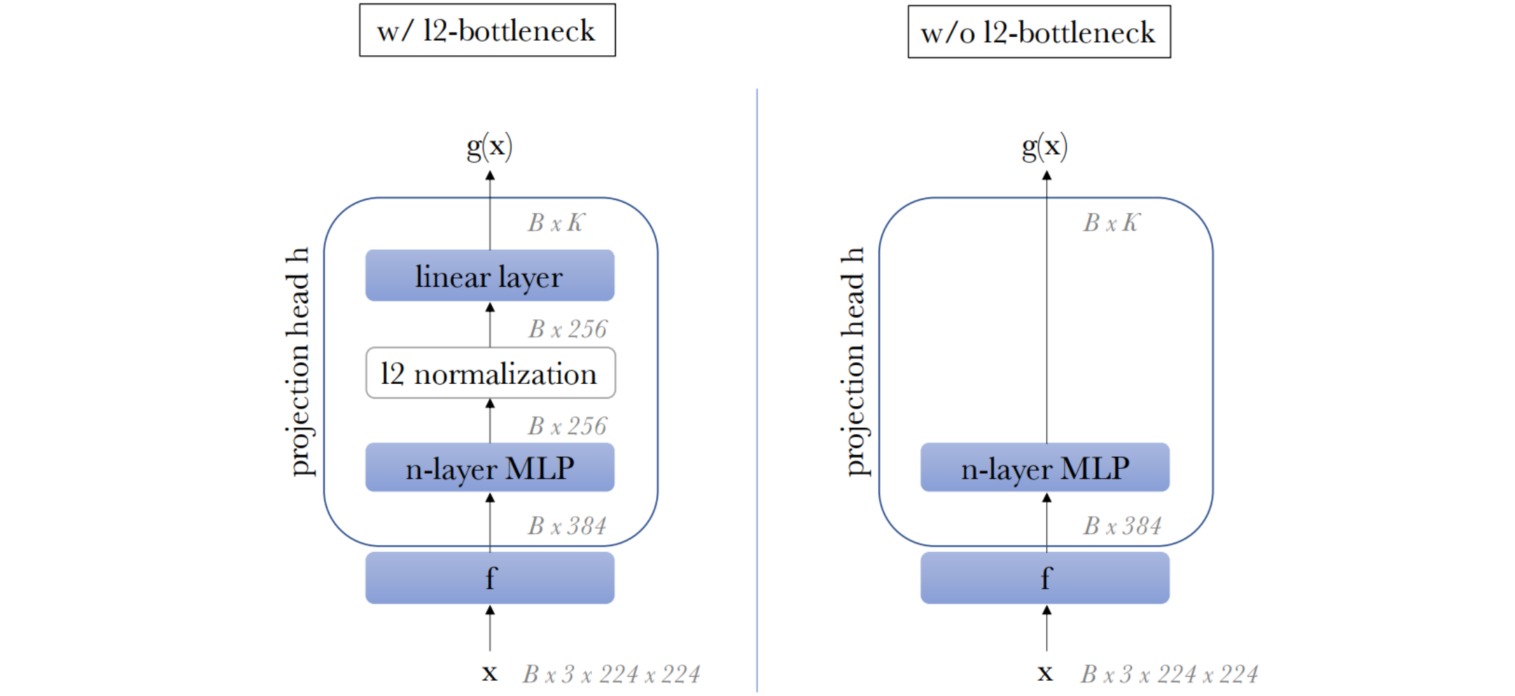
作者汇报了DINO方法的消融实验:

实验结果表明,对教师网络的特征同时应用centering操作和较小的$\tau_t$(对应锐化操作)能够有效地防止模型崩溃。



