Vision Transformer.
Transformer是基于自注意力机制(self-attention mechanism)的深度神经网络,该模型在$2017$年$6$月被提出,并逐渐在自然语言处理任务上取得最好的性能。

Transformer最近被扩展到计算机视觉任务上。由于Transformer缺少CNN的inductive biases如平移等变性 (Translation equivariance),通常认为Transformer在图像领域需要大量的数据或较强的数据增强才能完成训练。随着结构设计不断精细,也有一些视觉Transformer只依赖小数据集就能取得较好的表现。
本文主要介绍视觉Transformer在基础视觉任务(即图像分类)上的应用,这些模型训练完成后正如图像识别的CNN模型一样,可以作为backbone迁移到不同的下游视觉任务上,如目标检测、图像分割或low-level视觉任务。
1. 视觉Transformer的基本架构
ViT是最早把Transformer引入图像分类任务的工作之一。在ViT中,输入图像被划分为一系列图像块(patch);使用嵌入层把每个图像块编码为序列向量;再使用Transformer编码器进行特征提取;在输入序列中额外引入一个分类token,则对应的输出特征用于分类任务。
(1) Patch Tokenization
把输入图像划分成若干图像块,对每个图像块通过线性映射转换为嵌入向量,并在起始位置增加一个类别嵌入;最后加入可学习的位置编码。
from torch import nn
from einops.layers.torch import Rearrange
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
(2) Transformer Encoder
为了充分利用Transformer在自然语言处理领域的优化技巧,ViT最大程度地保留了Transformer编码器的原始结构。
Transformer编码器采用pre-norm的形式,即layer norm放置在自注意力机制或MLP之前。

import torch
from einops import rearrange
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
attn = self.dropout(attn)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
2. 改进视觉Transformer
(1)改进训练策略
⚪ SimpleViT
SimpleViT对ViT模型结构进行如下改动:位置编码采用sincos2d;分类特征采用全局平均池化;分类头采用单层线性层;移除了Dropout。在训练方面采用RandAug和MixUP数据增强,训练batch size采用$1024$。
⚪ DeiT (Data-efficient Image Transformer)
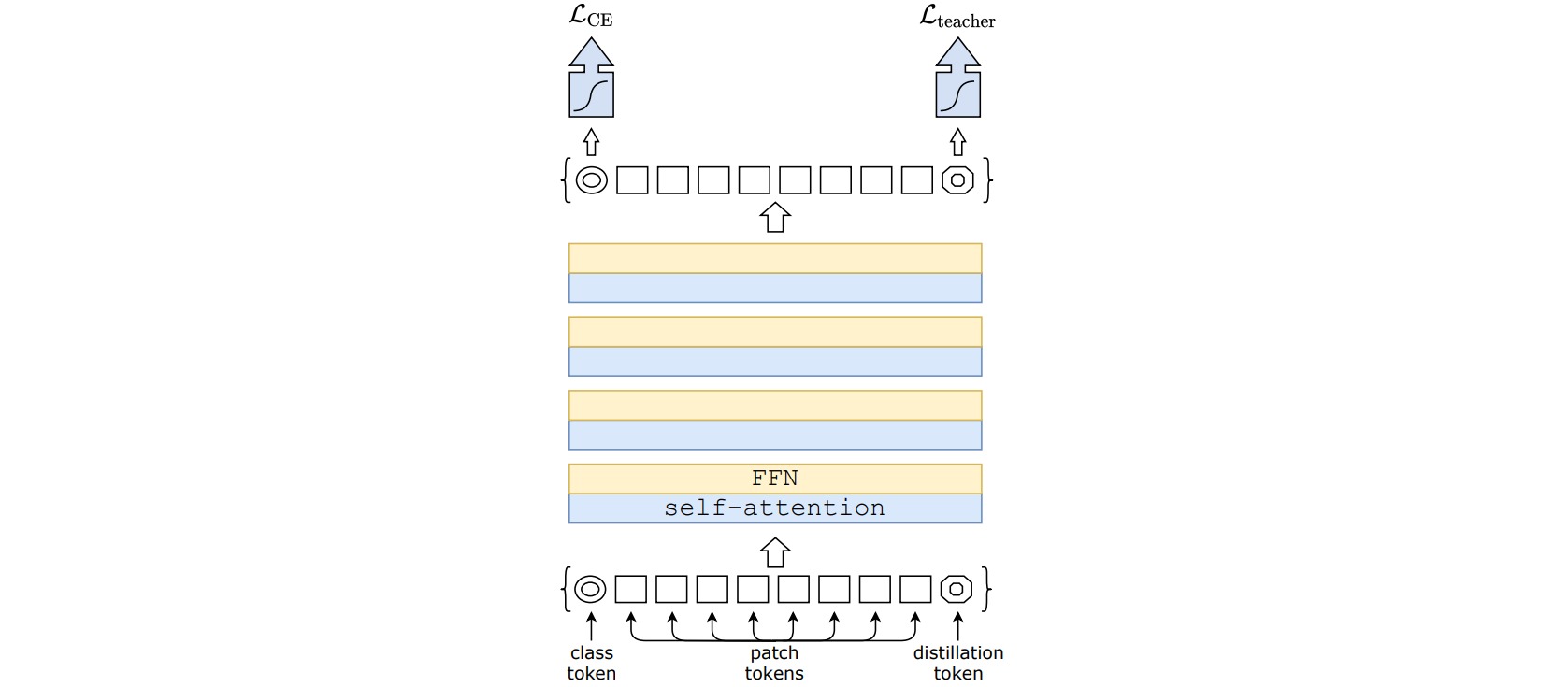
DeiT在输入图像块序列尾部添加了一个蒸馏token,以教师网络输出作为目标进行学习。蒸馏方式包括硬蒸馏(通过交叉熵学习教师网络决策结果)和软蒸馏(通过KL散度学习教师网络预测概率)。
⚪ Token Labeling
Token Labeling是指使用预训练的强分类模型为每个patch token分配一个软标签,作为额外的训练目标。本文还设计了MixToken,在Patch embedding后对两个样本的token序列进行混合。

⚪ Suppressing Over-smoothing
作者把视觉Transformer训练不稳定的原因归结为Over-smoothing问题,即不同token之间的相似性随着模型的加深而增加。基于此提出了三种提高训练稳定性的损失函数:相似度惩罚项减小输出token之间的相似度、Patch Contrastive Loss使得深层token与浅层对应token更加接近、Patch Mixing Loss给每个Patch提供一个监督信息。

(2)改进Patch Tokenization
⚪ Visual Transformer
Visual Transformer把卷积backbone提取的特征图通过空间注意力转换为一组视觉语义tokens,再通过Transformer处理高级概念和语义信息。

⚪ CCT (Compact Convolutional Transformer)
CCT引入了序列池化,对输出的序列特征进行加权平均用于后续的分类任务;并且使用卷积层编码图像patch。

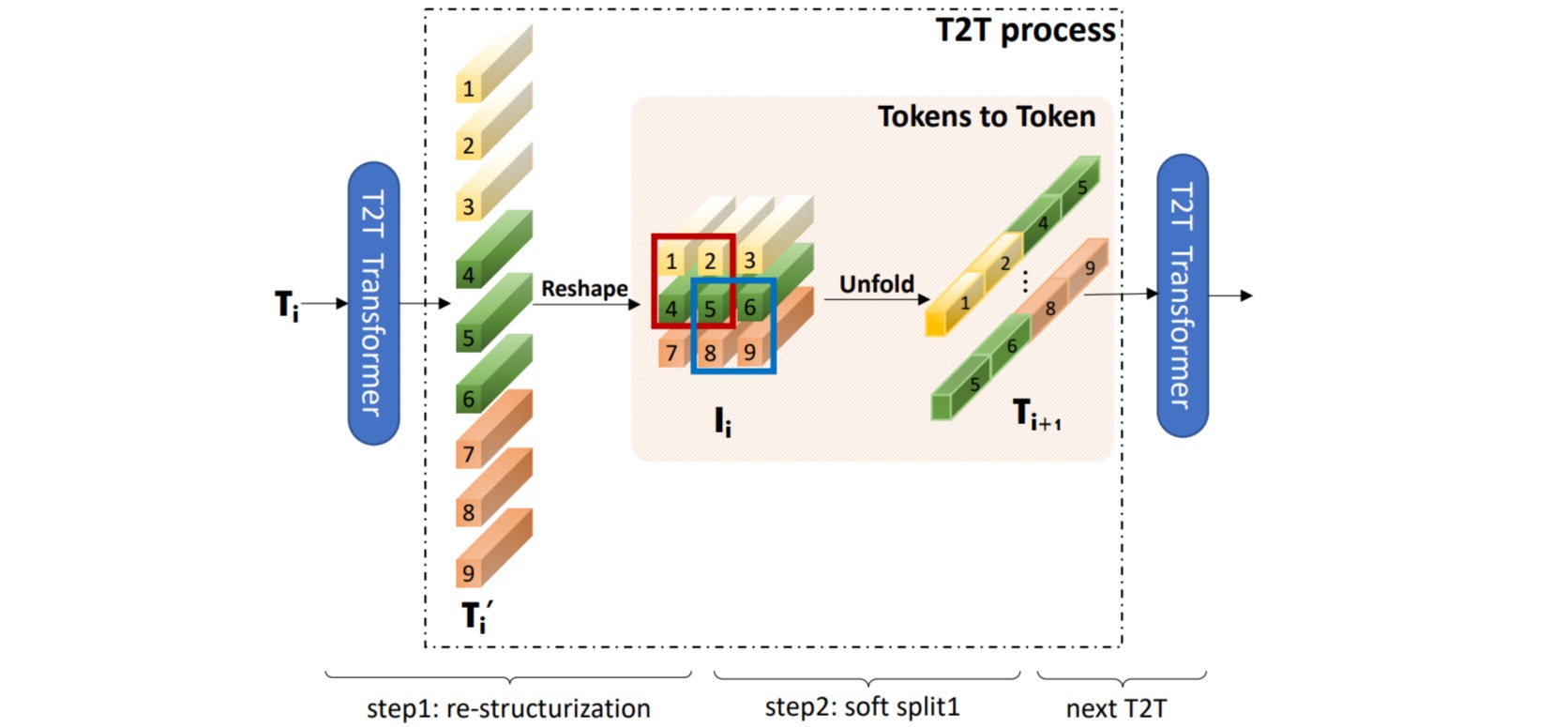
⚪ T2T-ViT (Tokens-to-Token ViT)
T2T-ViT通过 Tokens-to-Token module 来建模一张图片的局部信息,和更高效的 Transformer Backbone 架构设计来提升中间特征的丰富程度减少冗余以提升性能。
⚪ CPVT (Conditional Position encoding Vision Transformer)
CPVT提出了Positional Encoding Generator (PEG)代替位置编码,通过带零填充的深度卷积为tokens引入灵活的位置表示和更高效的位置信息编码。

⚪ PiT (Pooling-based Vision Transformer)
PiT在视觉Transformer体系结构中引入了池化层。池化层将patch token重塑为具有空间结构的3D张量,通过深度卷积来执行空间大小的减小和通道的增加。

(3)改进Self-Attention
⚪ DeepViT
DeepViT设计了Re-attention模块,采用一个可学习的变换矩阵$\Theta$把不同head的信息结合起来重新构造attention map,以此缓解不同层的注意力坍塌。
\[\operatorname{Re-}\operatorname{Attention}(Q, K, V)=\operatorname{Norm}\left(\Theta^{\top}\left(\operatorname{Softmax}\left(\frac{Q K^{\top}}{\sqrt{d}}\right)\right)\right) V\]
⚪ CaiT (Class-Attention in Image Transformer)
CaiT引入LayerScale使得深层ViT更易于训练;并提出Class-Attention Layer,在网络前半部分,Patch Token相互交互计算注意力;而在网络最后几层,Patch Token不再改变,Class Token与其交互计算注意力。

⚪ Twins-SVT
Twins-SVT设计了Spatially Separable Self-Attention(SSSA)。SSSA由两个部分组成:Locally-Grouped Self-Attention(LSA)和Global Sub-Sampled Attention(GSA)。LSA将2D feature map划分为多个Sub-Windows,并仅在Window内部进行Self-Attention计算;GSA将每个Window提取一个维度较低的特征作为各个window的表征,然后基于这个表征再去与各个window进行交互。

⚪ Refiner
Refiner首先通过 Linear Expansion 来对 attention map 的head数量进行扩展;再进行 Head-wise 的卷积操作,以建模tokens 之间的 local relationship。

(4)多尺度输入
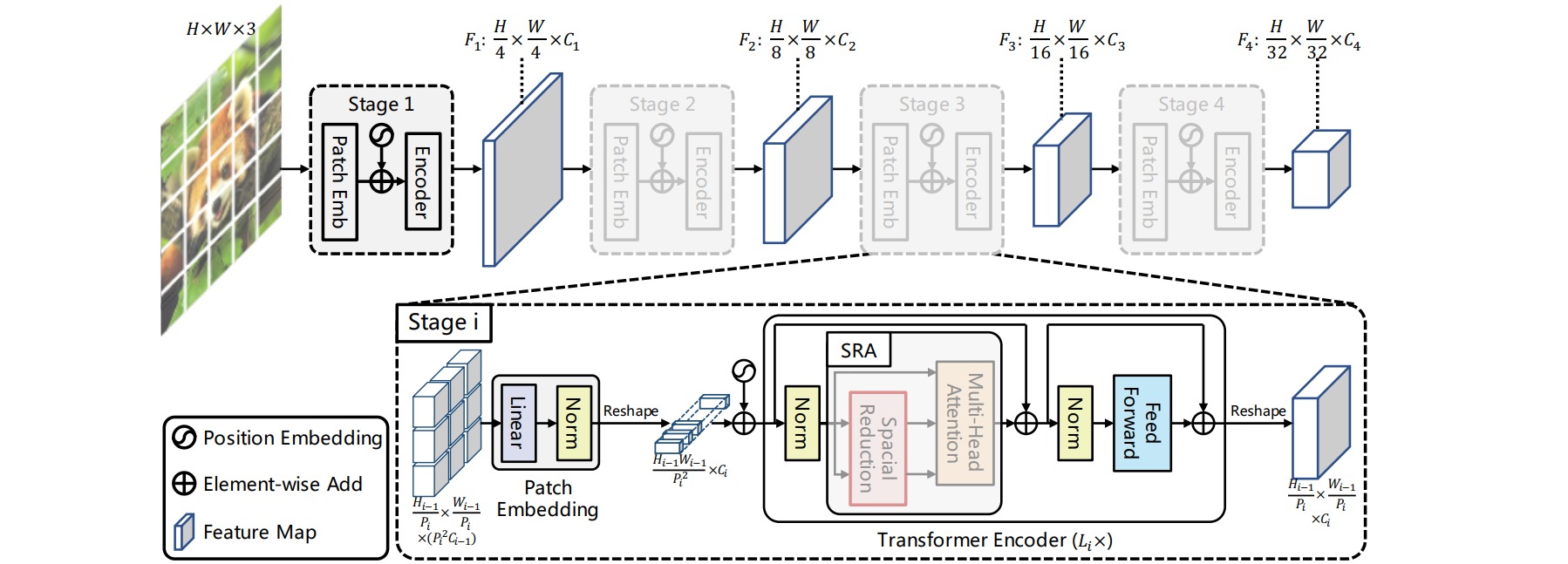
⚪ PVT
PVT在每个阶段进行patch embedding时划分2x2大小(第一阶段为4x4),以提取不同尺度的特征。为进一步减少计算量,设计了spatial-reduction attention (SRA),将K和V的空间分辨率都降低了R倍。
⚪ TNT
TNT使用outer transformer处理patch embedding,使用inner transformer处理每个patch的pixel embedding,从而融合了Patch内部信息与不同Patch之间的信息。

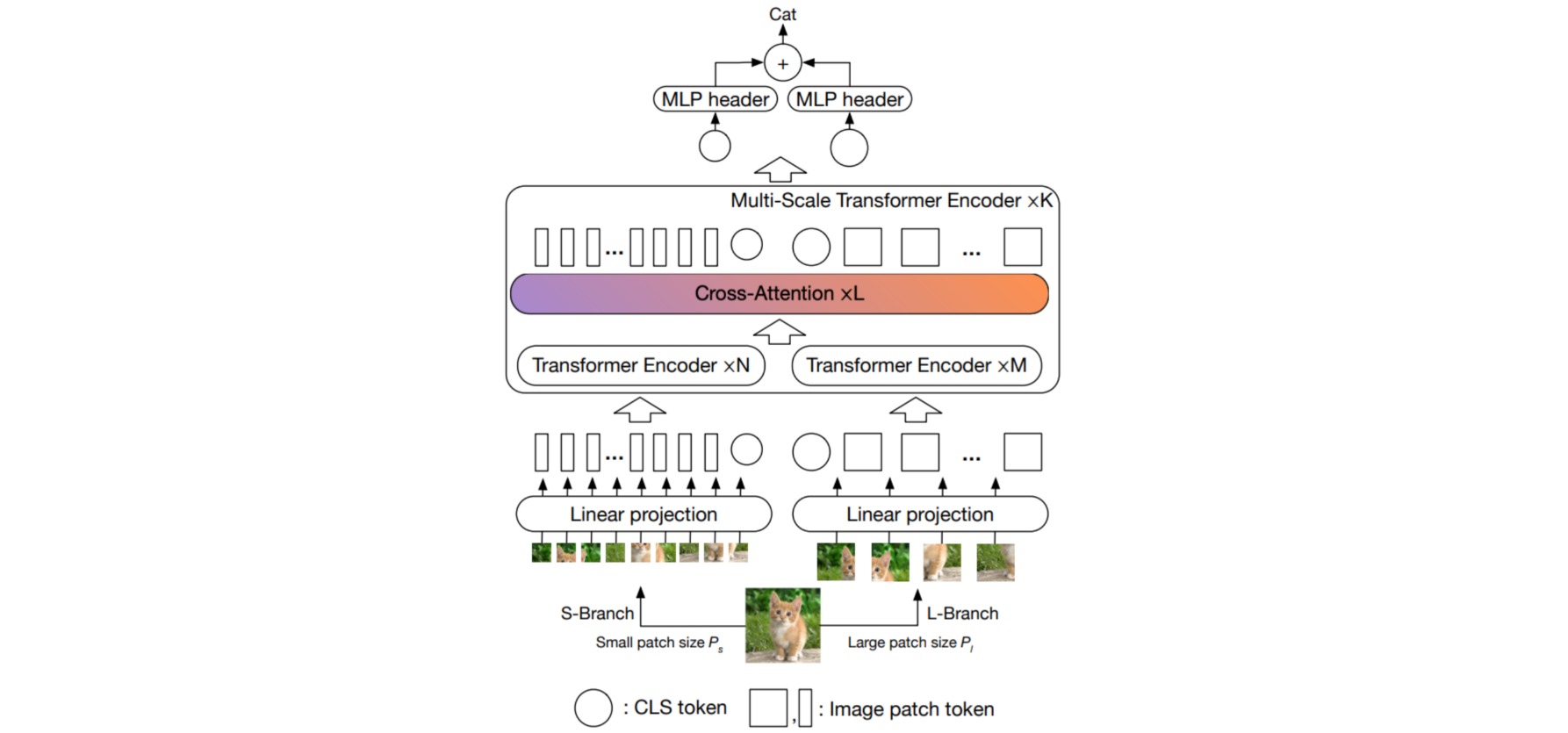
⚪ CrossViT
CrossViT采用双分支结构来处理不同大小的图像patch,以提取多尺度特征表示;不同分支之间通过基于交叉注意的token融合模块交换信息,该模块使用一个分支的CLS token作为一个查询与另一个分支的patch token进行交互。
(5)引入卷积层
⚪ BotNet (Bottleneck Transformer)
BotNet把ResNet中的$3×3$卷积替换为自注意力层。

⚪ CvT (Convolutional vision Transformer)
CvT使用三个阶段的卷积层对图像和特征进行嵌入和下采样,并使用深度可分离卷积构造$Q,K,V$。

⚪ CeiT (Convolution-enhanced image Transformer)
CeiT使用卷积层对图像进行嵌入,并使用深度卷积替换Transformer模块中的FFN层。

⚪ LeViT
LeViT把视觉Transformer中的所有线性变换替换为卷积操作,并采用卷积+下采样结构。

⚪ 视觉Transformer
-
Image Transformer:(arXiv1802)基于Transformer的图像生成自回归模型。
-
On the Relationship between Self-Attention and Convolutional Layers:(arXiv1911)理解自注意力和卷积层的关系。
-
Generative Pretraining from Pixels:(ICML2020)iGPT:像素级的图像预训练模型。
-
DETR:End-to-End Object Detection with Transformers:(arXiv2005)DETR:使用Transformer进行目标检测。
-
Deformable DETR: Deformable Transformers for End-to-End Object Detection:(arXiv2010)Deformable DETR:使用多尺度可变形的注意力模块进行目标检测。
-
Pre-Trained Image Processing Transformer:(arXiv2012)IPT:使用Transformer解决超分辨率、去噪和去雨等底层视觉任务。
-
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows:(arXiv2103)Swin Transformer: 基于移动窗口的分层视觉Transformer。
⚪ 参考文献
- Vision Transformer:(知乎) 通用 Vision Backbone 超详细解读 (原理分析+代码解读)。
- vit-pytorch:(github) Implementation of Vision Transformer in Pytorch。
- A Survey on Visual Transformer:(arXiv2012)一篇关于视觉Transformer的综述。
- Visual Transformers: Token-based Image Representation and Processing for Computer Vision:(arXiv2006)VT:基于Token的图像表示和处理。
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale:(arXiv2010)ViT:使用图像块序列的Transformer进行图像分类。
- Training data-efficient image transformers & distillation through attention:(arXiv2012)DeiT:通过注意力蒸馏训练数据高效的视觉Transformer。
- Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet:(arXiv2101)T2T-ViT:在ImageNet上从头开始训练视觉Transformer。
- Bottleneck Transformers for Visual Recognition:(arXiv2101)BotNet:CNN与Transformer结合的backbone。
- Do We Really Need Explicit Position Encodings for Vision Transformers?:(arXiv2102)视觉Transformer真的需要显式位置编码吗?
- Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions:(arXiv2102)PVT:一种无卷积密集预测的通用骨干。
- Transformer in Transformer:(arXiv2103)TNT:对图像块与图像像素同时建模的Transformer。
- DeepViT: Towards Deeper Vision Transformer:(arXiv2103)DeepViT:构建更深的视觉Transformer。
- Going deeper with Image Transformers:(arXiv2103)CaiT:更深的视觉Transformer。
- CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification:(arXiv2103)CrossViT:图像分类的交叉注意力多尺度视觉Transformer。
- Rethinking Spatial Dimensions of Vision Transformers:(arXiv2103)PiT:重新思考视觉Transformer的空间维度。
- CvT: Introducing Convolutions to Vision Transformers:(arXiv2103)CvT:向视觉Transformer中引入卷积。
- Incorporating Convolution Designs into Visual Transformers:(arXiv2103)CeiT:将卷积设计整合到视觉Transformers中。
- Escaping the Big Data Paradigm with Compact Transformers:(arXiv2104)CCT:使用紧凑的Transformer避免大数据依赖。
- LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference:(arXiv2104)LeViT:以卷积网络的形式进行快速推理的视觉Transformer。
- Twins: Revisiting the Design of Spatial Attention in Vision Transformers:(arXiv2104)Twins:重新思考视觉Transformer中的空间注意力设计。
- All Tokens Matter: Token Labeling for Training Better Vision Transformers:(arXiv2104)LV-ViT:使用标志标签更好地训练视觉Transformers。
- Improve Vision Transformers Training by Suppressing Over-smoothing:(arXiv2104)通过抑制过度平滑改进视觉Transformer。
- Refiner: Refining Self-attention for Vision Transformers:(arXiv2106)Refiner:精炼视觉Transformer中的自注意力机制。
- Better plain ViT baselines for ImageNet-1k:(arXiv2205)在ImageNet-1k数据集上更好地训练视觉Transformer。


