MoCo:无监督视觉表示学习的矩对比.
矩对比(Momentum Contrast, MoCo)把无监督视觉表示学习看作动态字典查询(dynamic dictionary look-up)问题,其中字典是用数据样本的编码表示构造的先入先出队列(FIFO queue)。
给定查询样本$x_q$,通过编码器$f_q(\cdot)$构造查询表示$q=f_q(x_q)$;字典中的键表示\(\{k_1,k_2,...\}\)通过矩编码器$f_k(\cdot)$构造$k_i=f_k(x_k^i)$。假设字典中存在匹配$q$的一个正样本$k^+$(通过对$x_q$进行数据增强构造),则可以通过$1$个正样本和$N-1$个负样本构造对比损失:
\[\mathcal{L}_{\text{MoCo}} = -\log \frac{\exp(q \cdot k^+/\tau)}{\sum_{i=0}^{N}\exp(q \cdot k_i/\tau)}\]
下面是三种不同形式的对比学习方法对比。图a是并行数据增强的对比学习方法,计算查询和键的编码器以端到端的形式更新,这种方法要求样本批量足够大,以提供充足的负样本数量;图b是基于存储体的对比学习方法,其中键特征存储在memory bank中,每次更新时采样,这种方法要求构建一个足够大的字典;图c是MoCo方法,在每次更新时通过矩编码器构造新的键,并维持一个存储样本特征的队列。
由于键队列是不可微的,因此矩编码器$f_k(\cdot)$无法通过反向传播更新参数。在实践中采用基于矩的更新方法,矩编码器$f_k(\cdot)$的参数$\theta_k$通过编码器$f_q(\cdot)$的参数$\theta_q$更新:
\[\theta_k \leftarrow m \theta_k + (1-m) \theta_q\]
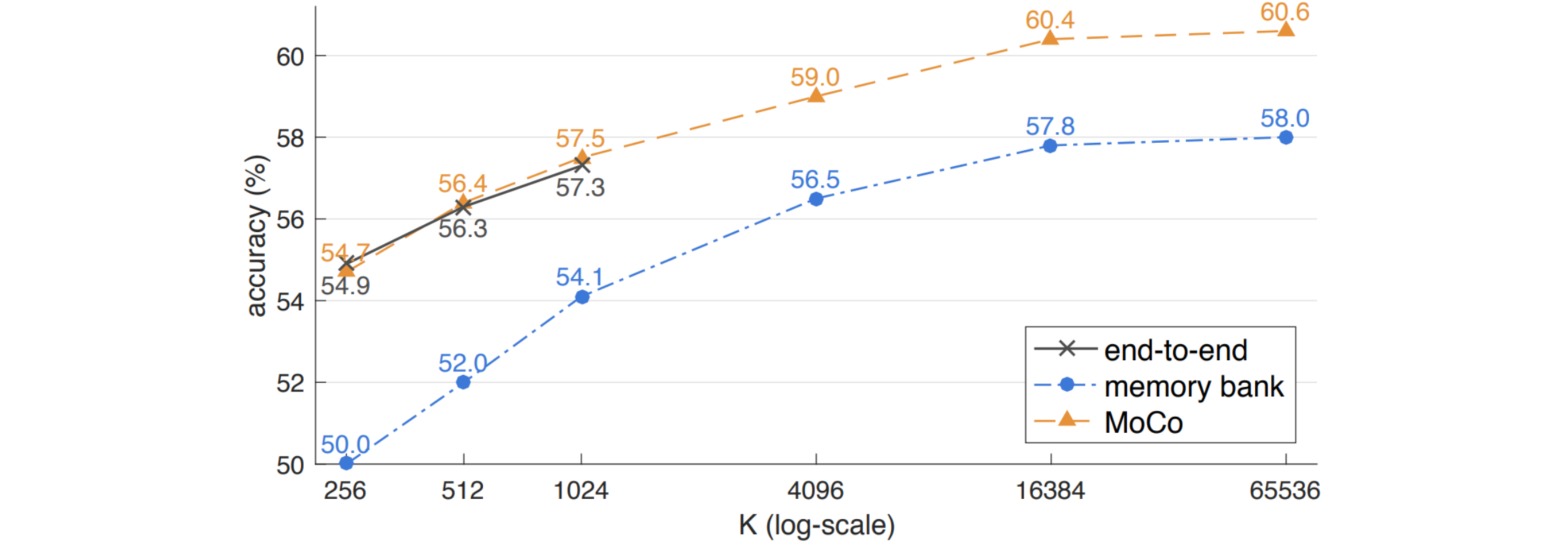
实验结果表明,当增大队列长度(等价于批量大小)时,模型的性能逐渐提升;而端到端的对比学习方法受限于内存大小,无法应用较大的批量大小。