DALL·E:从文本生成图像.
- 论文:Learning Transferable Visual Models From Natural Language Supervision
- 模型介绍:DALL·E: Creating Images from Text
- 方法介绍:CLIP: Connecting Text and Images
- 预训练模型:Contrastive Language-Image Pretraining (github)
⚪ DALL·E: Creating Images from Text
OpenAI提出了DALL·E模型,该模型可以从包含大量概念的文本描述中生成相关图像。其名称DALL·E致敬了艺术家Salvador Dalí和皮克斯动画角色WALL·E。
DALL·E采用了基于Transformer的预训练结构,共有$120$亿参数。该模型同时接收图像和其文本描述作为输入,输入使用$1280$个token,包括$256$个词汇量是$16384$的文本token和$1024$个词汇量是$8192$的图像token。对于文本token,使用标准的随机mask,通过GPT-3构造;对于图像token,使用稀疏注意力(只计算某行、某列或局部),训练时图像尺寸被调整为$256 \times 256$,并参考VQ-VAE模型将其压缩为$32 \times 32$的特征,使用字典对每个特征进行编码。整体模型采用极大似然算法进行自回归训练。
该模型能够从不同的文本描述中生成对应的图像:

上述结果是在生成的$512$个样本中选择的前$32$个质量最好的样本,选择过程使用了CLIP模型。值得一提的是,目前的模型对纹理、颜色等性质生成的图像质量好,但对于数量、逻辑等性质生成的图像质量较差。
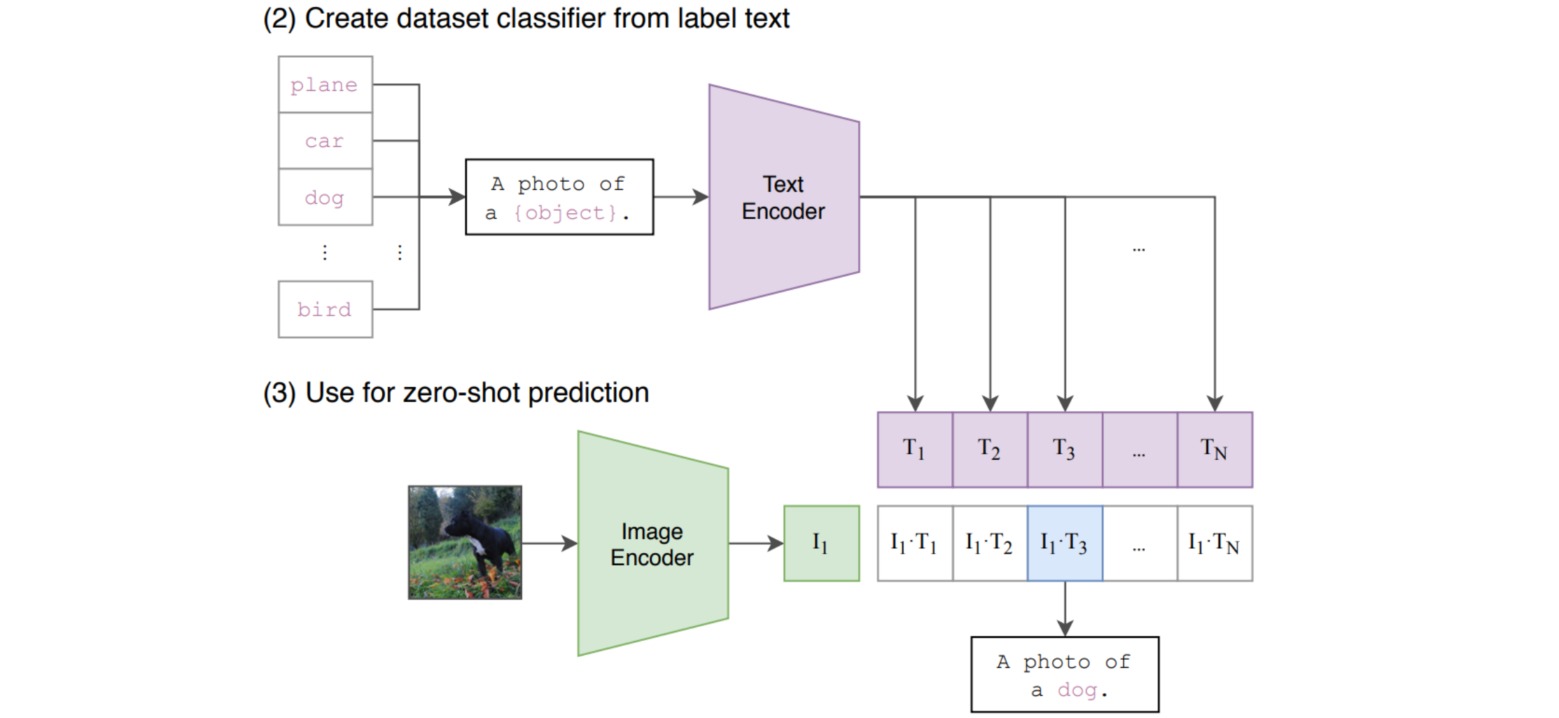
⚪ CLIP: Connecting Text and Images
Contrastive Language-Image Pre-training (CLIP)方法用于在图像和文本数据集中进行匹配。具体地,训练一个文本编码器和图像编码器,分别得到文本和图像的编码,并计算两者的匹配程度。

给定$N$个图像-文本对,首先计算任意一个图像和文本之间的余弦相似度矩阵,尺寸为$N \times N$;通过交叉熵损失使得匹配的$N$个图像-文本对的相似度最大,其余$N(N-1)$个相似度最小。
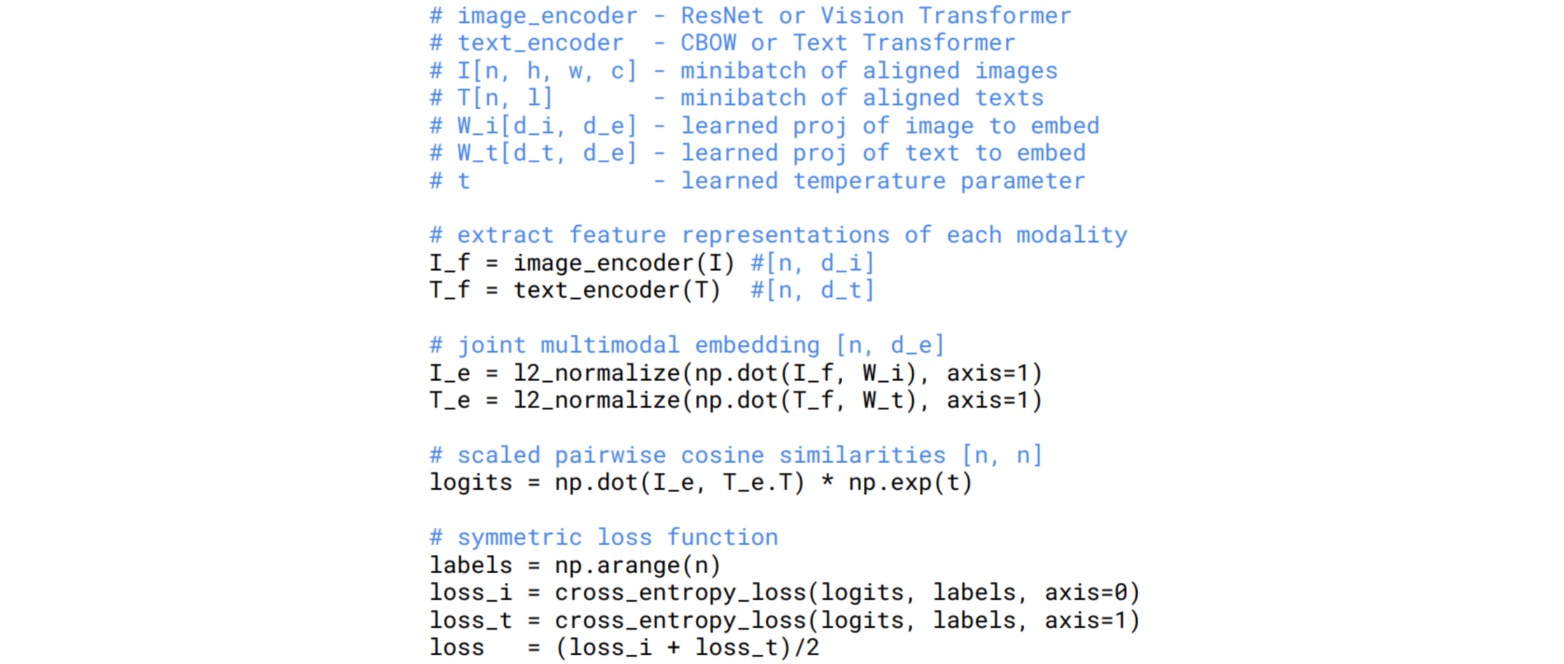
CLIP在训练时使用了$4$亿张从互联网收集的图像-文本对(WebImageText, WIT),文本字典存储了在Wikipedia中出现超过100次的所有单词。实验结果表明,对于文本编码器,采用bag-of-words (BoW)模型比Transformer的效率能提高3倍;采用对比损失比直接预测图像对应的文本效率能提高4倍。

CLIP训练完成后可以实现zero-shot的推理,即不经过微调的迁移学习,该过程是通过prompt templete实现的。以ImageNet数据集的分类任务为例,对于一千个类别标签,分别生成一千个对应的文本(如A photo of a #Class);通过CLIP匹配相似度最高的图像和文本,即可确定图像中出现目标的类别。