通过解决拼图问题实现无监督视觉表示学习.
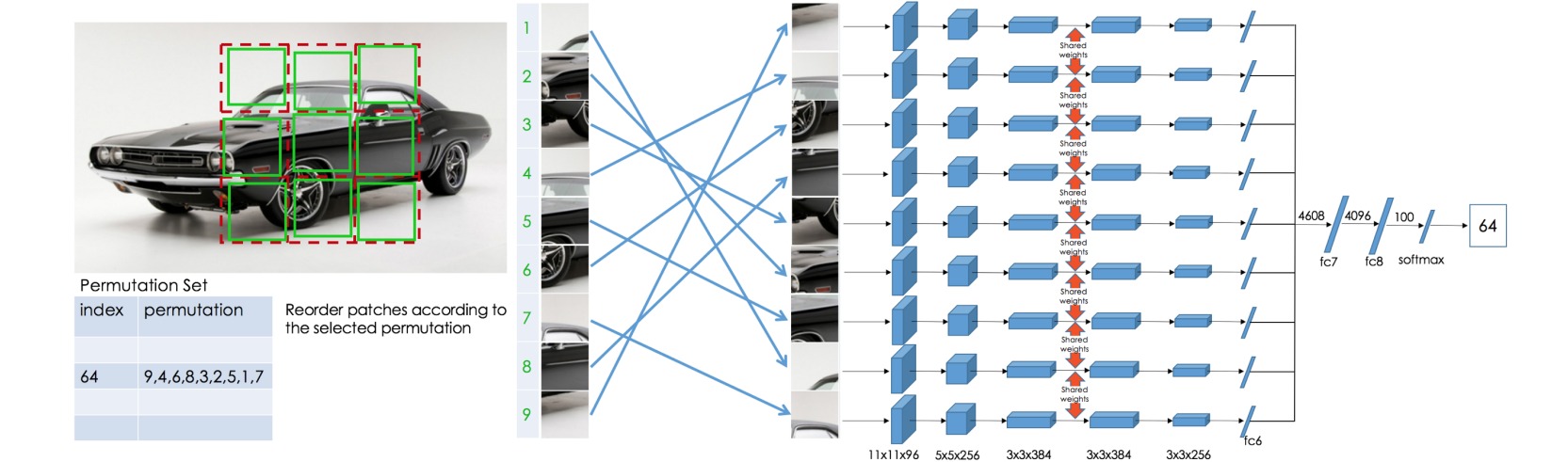
本文设计了一种通过拼图问题(jigsaw puzzle)实现无监督视觉表示学习的方法,让模型把九个打乱的图像块恢复到初始位置。

卷积网络通过共享权重分别处理每一个图像块,并根据预定义的排列集合输出图像块排列的索引概率,则自监督学习的前置任务是一种多分类任务。
通过简单的打乱输入图像块,模型可能会学习到局部纹理信息等捷径导致分类精度偏高,实际上没有学习到较好的结构特征。因此将图像块之间边缘并不紧密贴合。
在构造图像块时,将图像尺寸调整为$255 \times 255$,然后切成$9 \times 75 \times 75$的图像块,从$75 \times 75$的图像块中随机选择$64 \times 64$的图像块。
由于$3\times 3$的切片排列顺序有$9!=362880$种,为了减少网络参数、控制拼图问题的难度,本文从中选出$1000$种预定义的排列集合打乱图像块,以确保模型预测的索引在集合中是存在的。预定义的排列集合是通过选择汉明距离最高的排序序列实现的。

由于输入图像块的打乱方式不会改变正确的预测顺序,因此加快训练速度的改进是使用具有置换不变性的图卷积网络(GCN),这样就不必对同一组图像块进行多次打乱。


