Human Pose Estimation.
人体姿态估计 (Human Pose Estimation, HPE)是指从图像、视频等输入信号中估计人体的姿态信息。姿态通常以关键点(keypoint,也称为关节点 joint,比如手肘、膝盖、肩膀)组成的人体骨骼(skeleton)表示。
人体姿态估计与关键点检测的区别:人体关键点检测是指在图像中直接预测若干预定义人体关键点的空间位置,当关键点部位被遮挡时则无法直接预测;而人体姿态估计在此基础上根据人体关节的先验知识和全局关系对被遮挡的关键点位置进行估计,从而获得完整的人体姿态预测结果。
本文目录:
⭐ 扩展阅读:
- Monocular Human Pose Estimation: A Survey of Deep Learning-based Methods:(arXiv2006)单目人体姿态估计的深度学习方法综述。
1. 2D单人姿态估计 2D Single Human Pose Estimation
2D单人人体姿态估计通常是从已完成定位的人体图像中计算人体关节点的位置,并进一步生成2D人体骨架。这些方法可以进一步分为基于回归(regression-based)的方法与基于检测(detection-based)的方法。
- 基于回归的方法:直接将输入图像映射为人体关节的坐标或人体模型的参数,如DeepPose, TFPose, Poseur, PCT。
- 基于检测的方法:将输入图像映射为图像块(patch)或人体关节位置的热图(heatmap),从而将身体部位作为检测目标;如CPM, Hourglass, Chained, MCA, FPM, HRNet, TokenPose, ViTPose。
(1)基于回归的2D单人姿态估计 Regression-based 2D SHPE
基于回归的方法直接预测人体各关节点的联合坐标。这类方法可以端到端的训练,速度更快,并且没有量化误差;但由于映射是高度非线性的,学习较为困难,且缺乏鲁棒性。
⚪ DeepPose
DeepPose使用预训练卷积神经网络提取特征,直接对人体的$k$对关键点坐标进行回归预测。模型使用了级联回归器,对前一阶段的预测结果进行细化。

⚪ TFPose
TFPose通过将卷积神经网络与Transformer结构相结合,直接并行地预测所有关键点坐标序列。Transformer解码器将一定数量的关键点查询向量和编码器输出特征作为输入,并通过一个多层前馈网络预测最终的关键点坐标。

⚪ Poseur
Poseur用$K$个query token作为可学习的关键点token,Backbone使用卷积网络来回归粗略预测的关键点坐标值;Keypoint Encoder将粗略预测的关键点坐标转换为位置编码,和可训练的类别嵌入向量融合成query token;Query Decoder接收query token和Backbone提供的多尺度特征图来更新查询token。

⚪ Pose as Compositional Tokens (PCT)
PCT通过VQ-VAE学习关节点坐标的离散编码表,然后使用预训练的人体姿态编码器把人体图像编码到同一个特征空间,并通过查表的方式重构人体姿态坐标。

(2)基于检测的2D单人姿态估计 Detection-based 2D SHPE
基于检测的方法使用热图来指示关节的真实位置。如下图所示,每个关键点占据一个热图通道,表示为以目标关节位置为中心的二维高斯分布。

把关节点坐标转换成热图的过程如下:
class Coord2Heatmap:
"""
Generate target heatmaps from given coords
"""
def __init__(self, hm_size=[64,64], sigma=2):
"""
Args:
hm_size: [int, int]. Width and height of Target heatmap
sigma: int. Variance of Target heatmap
"""
super(Coord2Heatmap, self).__init__()
self.hm_size = hm_size
self.sigma = sigma
def generate(self, coords):
"""
Args:
coords: numpy.array, shape: [N, 2]. Coordinates of keypoints
Return:
targets: numpy.array, shape: [N, hm_size[1], hm_size[0]]. Generated target heatmaps
"""
num_joints = coords.shape[0]
W, H = self.hm_size
x = np.linspace(0, W-1, W)[np.newaxis, :]
x = np.repeat(x, num_joints, axis=0)
y = np.linspace(0, H-1, H)[np.newaxis, :]
y = np.repeat(y, num_joints, axis=0)
heatmap = np.exp(-((x-coords[:, 0])[:, :, np.newaxis]**2 + (y-coords[:, 1])[:, np.newaxis, :]**2) / self.sigma ** 2)
return heatmap
if __name__ == "__main__":
generator = Coord2Heatmap(hm_size=[8,8])
test_coords = np.array([
[8, 8],
])
test_targets = generator.generate(test_coords)
基于热图的方法通过显式地渲染高斯热图,让模型学习输出的目标分布,也可以看成模型单纯地在学习一种滤波方式,将输入图像滤波为最终希望得到的高斯热图,这极大地简化了模型的学习难度,且非常契合卷积网络的特性(卷积本身就可以看成一种滤波器);并且这种方式规定了学习的分布,能够保存空间位置信息,对于各种情况(遮挡、动态模糊、截断等)要鲁棒得多。
这类方法从中估计关节点坐标的准确性较差(热图大小往往是原图的等比例缩放,通过在输出热图上按通道找最大的响应位置,精度是pixel级别),并且阻碍了端到端的训练。同时基于热图的方法需要网络始终保留热图尺寸的中间层特征图,会使网络整体具有较大的参数量,不适合移动端部署。
⚪ Convolutional Pose Machine (CPM)
卷积姿态机使用顺序化的卷积网络来进行图像特征提取,以置信度热图的形式表示预测结果,在全卷积的结构下使用中间监督进行端到端的训练。
顺序化的卷积架构表现在网络分为多个阶段,每一个阶段都有监督训练的部分。前面的阶段使用原始图片作为输入,后面阶段使用之前阶段的特征图作为输入。

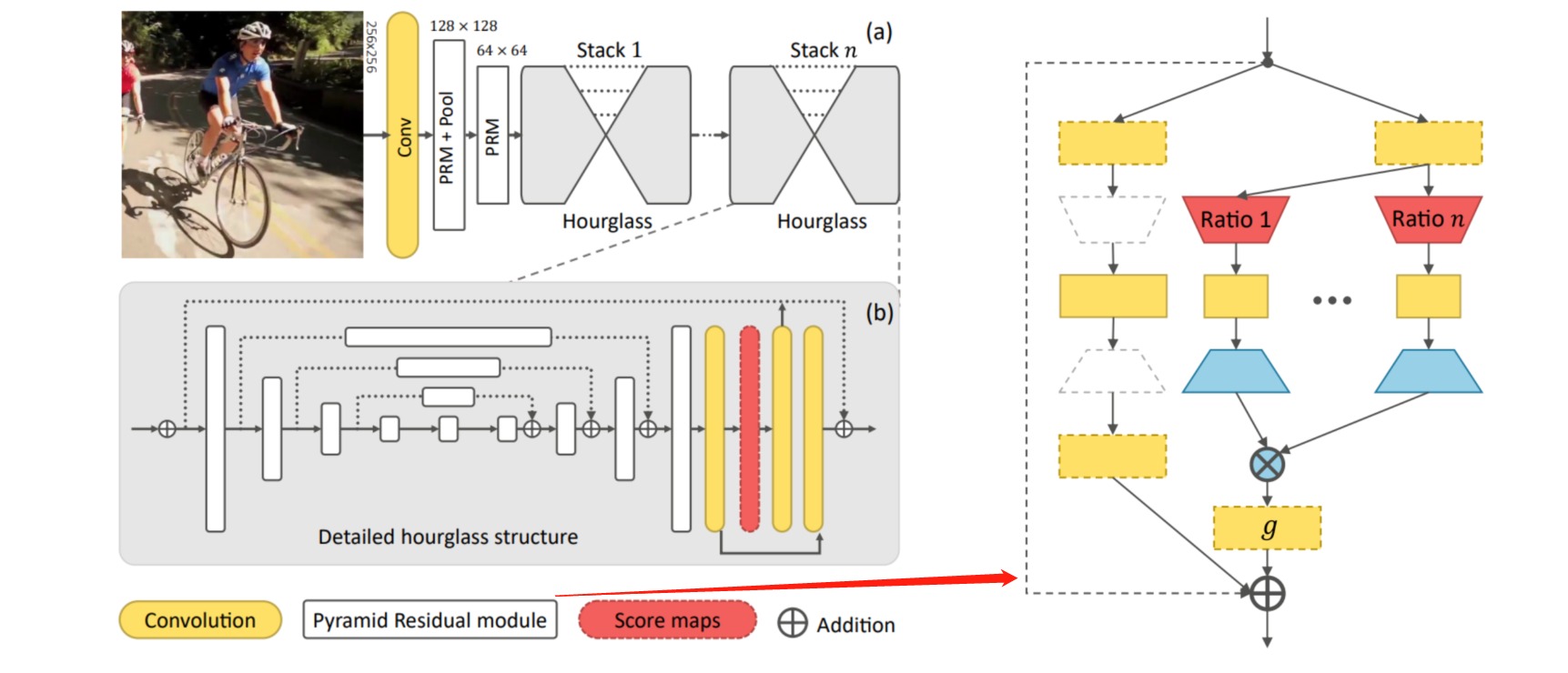
⚪ Stacked Hourglass Network
堆叠沙漏网络是由若干个Hourglass模块堆叠而成,Hourglass模块是由若干次下采样+上采样和残差连接组成。此外还在每个Hourglass模块中引入了中间监督。

⚪ Chained Prediction
Chained Prediction是指按照关节链模型的顺序输出关节热图,每一步的输出取决于输入图像和先前预测的热图。
⚪ Multi-Context Attention (MCA)
本文为堆叠沙漏网络引入了沙漏残差单元(HRUs)以学习不同尺度的特征,并在浅层引入多分辨率注意力,在深层引入由粗到细的部位注意力。

⚪ Feature Pyramid Module (FPM)
特征金字塔模块能够提取不同尺度的特征,可以替换Hourglass中的残差模块。
⚪ HRNet
HRNet不断地去融合不同尺度上的信息,其整体结构分成多个层级,但是始终保留着最精细的空间层级信息,通过融合下采样然后做上采样的层,来获得更多的上下文以及语义层面的信息。

⚪ TokenPose
TokenPose通过CNN网络提取特征图,将特征图拆分为patch后拉平为visual tokens,然后随机初始化一些可学习的keypoint tokens一起送入transformer进行学习,并将输出的keypoint tokens通过一个MLP映射到heatmap。

⚪ ViTPose
ViTPose使用ViT结构作为Backbone,结合一个轻量级的Decoder解码关节点热图。

2. 2D多人姿态估计 2D Multiple Human Pose Estimation
与单人姿态估计相比,多人姿态估计需要同时完成检测和估计任务。根据完成任务的顺序不同,多人姿态估计方法分为自上而下(top-down)的方法和自下而上(bottom-up)的方法。
- 自上而下的方法先做检测再做估计。即先通过目标检测的方法在输入图像中检测出不同的人体,再使用单人姿态估计方法对每个人进行姿态估计;如RMPE, CPN, MSPN, RTMPose。
- 自下而上的方法先做估计再做检测。即先在图像中估计出所有人体关节点,再将属于不同人的关节点进行关联和组合;如DeepCut, DeeperCut, Associative Embedding, OpenPose。

(1)自上而下的2D多人姿态估计 Top-down 2D MHPE
自上而下的方法中两个最重要的组成部分是人体区域检测器和单人姿态估计器。大多数研究基于现有的人体目标检测器进行估计,如Faster R-CNN、Mask R-CNN和FPN。
通过将现有的人体检测网络和单人姿态估计网络结合起来,可以轻松实现自上而下的多人姿态估计。这类方法检测人体目标的召回率较高,关节点的定位精度较高,几乎在所有Benchmarks上取得了最先进的表现,但这种方法的处理速度受到检测人数的限制,当检测人数增加时运行时间成倍地增加。
⚪ RMPE
RMPE框架包含三部分:对称空间变换网络SSTN用于在不准确的人体检测框中提取准确的单人区域;参数化姿态的非极大值抑制p-pose NMS用于解决人体检测框冗余问题;姿态引导区域框生成器PGPG用于数据增强。

⚪ CPN
CPN使用FPN进行人体目标检测,在关节点检测时采用GlobalNet和RefineNet。GlobalNet对关键点进行粗提取,RefineNet对不同层信息进行融合,更好地综合特征定位关键点。

⚪ MSPN
MSPN使用CPN的GlobalNet进行多阶段的堆叠,并引入了跨阶段的特征聚合(融合不同阶段同一层的特征)与由粗到细的监督(中间监督热图随着阶段的增加越来越精细)。

⚪ RTMPose
RTMPose 使用一个骨干网络、一个卷积层、一个全连接层和一个门控注意力单元(Gated Attention Unit, GAU)提取$K$个关键点的特征。然后采用SimCC把二维姿态估计任务看作两个分类任务,分别预测关键点的水平和垂直坐标。

(2)自下而上的2D多人姿态估计 Bottom-up 2D MHPE
自下而上的人体姿态估计方法的主要组成部分包括人体关节检测和候选关节分组。大多数算法分别处理这两个组件,也可以在单阶段进行预测。
这类方法的关键在于正确组合关节点,速度不受图像中人数变化影响,实时性好;但是性能会受到复杂背景和人为遮挡的影响,精度相对低,当不同人体之间有较大遮挡时,估计效果会进一步下降。
⚪ DeepCut
DeepCut首先从图像中提取关节点候选集合$D$,并将其划分到$C$个关节类别中。定义三元组$(x,y,z)$:
\[x \in \{0,1\}^{D\times C},y \in \{0,1\}^{\begin{pmatrix}D \\ 2\end{pmatrix}},z \in \{0,1\}^{\begin{pmatrix}D \\ 2\end{pmatrix}\times C^2}\]其中$x_{dc} = 1$表示关节点$d$属于类别$c$,$y_{dd’}=1$表示关节点$d$和$d’$属于同一个人,$z_{dd’cc’}=x_{dc}x_{d’c’}y_{dd’}$是一个辅助变量。进一步建立$(x,y,z)$的线性方程,构造整数线性规划问题。

⚪ DeeperCut
DeeperCut相比于DeepCut有三点改进:
- 使用ResNet提高关节点检测的准确率;
- 改进优化策略更有效地搜索空间,获得更好的性能和显著速度提升;
- 通过图像条件成对项(image-conditioned pairwise terms)进行关节点的非极大值抑制,即通过候选关节点之间的距离来判断是否为不同的重要关节点。

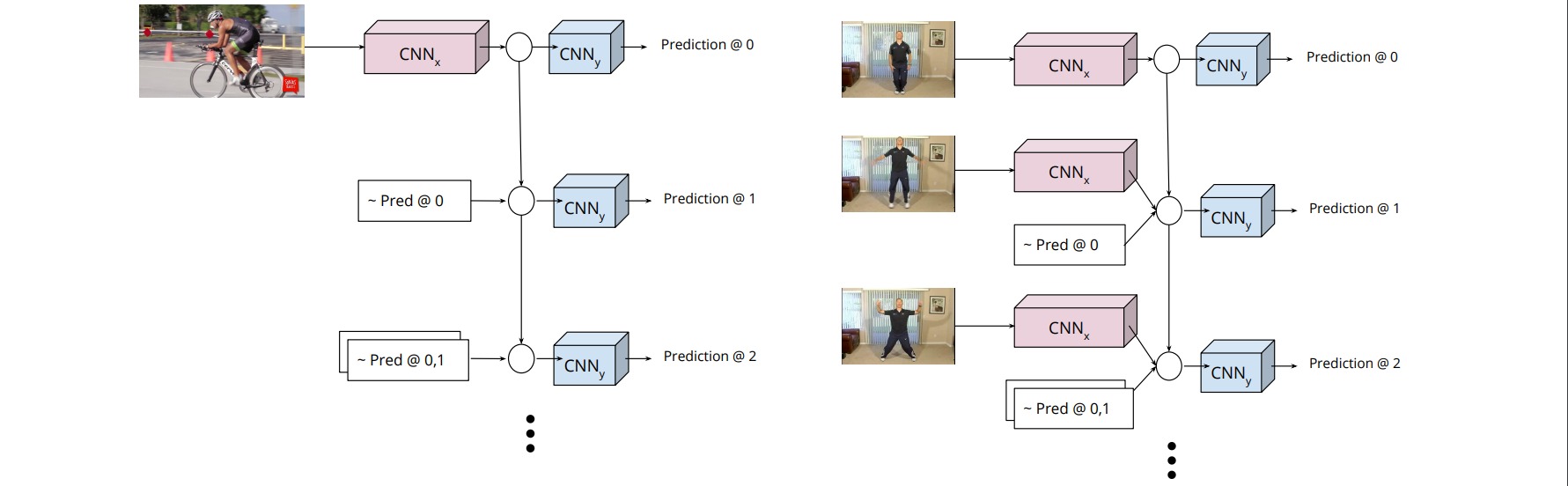
⚪ Associative Embedding
Associative Embedding为每个关节点输出一个embedding,使得同一个人的embedding尽可能相近,不同人的embedding尽可能不一样。
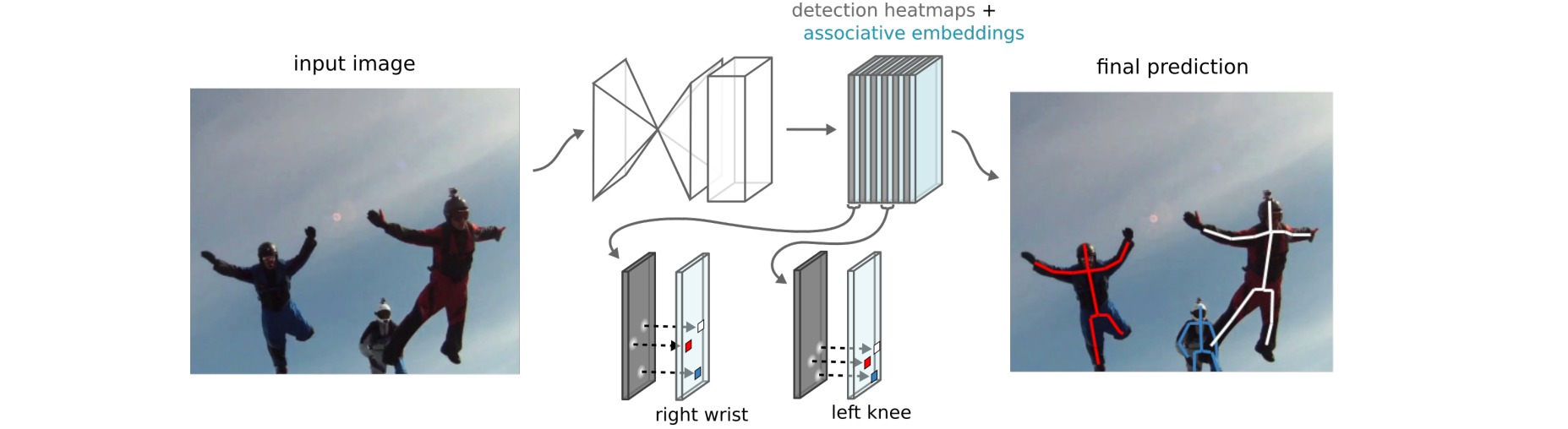
⚪ OpenPose
OpenPose使用卷积神经网络从输入图像中提取部位置信图(PCM)与部位亲和场(PAF):部位置信图是指人体关节点的热力图,用于表征人体关节点的位置;部位亲和场是用于编码肢体支撑区域的位置和方向信息的2D向量场。然后通过二分匹配(边权基于PAF计算)进行关节分组。

3. 3D人体姿态估计 3D Human Pose Estimation
3D人体姿态估计是从图片或视频中估计出关节点的三维坐标$(x, y, z)$,本质上是一个回归问题。与2D人体姿态估计相比,3D人体姿态估计需要估计深度(depth)信息。3D人体姿态估计的主要挑战:
- 单视角下2D到3D映射中固有的深度模糊性与不适定性:因为一个2D骨架可以对应多个3D骨架。
- 缺少大型的室外数据集和特殊姿态数据集:3D姿态数据集是依靠适合室内环境的动作捕捉(MOCAP)系统构建的,而MOCAP系统需要佩戴有多个传感器的复杂装置,在室外环境使用是不切实际的。因此数据集大多是在实验室环境下建立的,模型的泛化能力也比较差。
3D人体姿态估计方法可以分为:
- 直接回归的方法:直接把图像映射为3D关节点,如DconvMP, VNect, ORPM, Volumetric Prediction, 3DMPPE。
- 2D→3D的方法:从2D姿态估计结果中估计深度信息,如2D+Matching, SimpleBasline-3D。
- 基于模型的方法:引入人体模型,如SMPLify, SMPLify-X。
(1)直接回归的3D人体姿态估计 Regression-based 3D HPE
直接回归的3D人体姿态估计直接把图像映射成3D关节点,这通常是严重的欠定问题,因此需要引入额外的约束条件。
⚪ DconvMP
把3D人体姿态估计任务建模为关节点回归任务+关节点检测任务。关节点回归任务估计关节点相对于根关节点的位置;关节点检测任务检测每个局部窗口中是否存在关节点。

⚪ VNect
VNect预测一个热图及位置图。位置图存储关节点相对于根关节的三维坐标。找到关键点的过程为从热图中寻找关节的最大值,在对应的$X, Y, Z$位置图中找到对应位置的点组成相对根节点的3D坐标。

⚪ ORPM
遮挡鲁棒的姿态图ORPM将场景中所有人的3D关节位置编码为固定数量的位置图,并使用身体部位关联推断任意数量的人体目标。

⚪ Volumetric Prediction
本文提出了一种端到端的单图像3D姿态估计方法,从2D图像中直接得到体素(Volumetric)表示,并取最大值的位置作为每个关节点的输出。

⚪ 3DMPPE
- paper:Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image
本文提出了一种自顶向下的多人3D姿态估计方法:边界框检测网络DetectNet检测每个目标的边界框;根节点定位网络RootNet定位根节点位置;相对根节点的3D单人姿态估计网络PoseNet估计相对根节点的3D姿态。

(2)2D→3D的3D人体姿态估计 2D→3D 3D HPE
2D→3D的3D人体姿态估计从2D姿态估计的结果中估计深度信息,再生成3D姿态估计,这类方法可以很容易地利用2D姿态数据集,并且具有2D姿态估计的优点。
⚪ 2D + Matching
给定2D图像,通过CPM预测2D姿态,并从大型的2D-3D姿态对库中通过kNN搜索最相似的2D-3D姿态对,配对的3D姿态被选为3D姿态估计结果。

⚪ SimpleBasline-3D
将 3D 姿态估计解耦为2D 姿态估计和从2D 到 3D 姿态估计(即3D姿态估计 = 2D姿态估计 + (2D->3D))。(2D->3D)通过全连接网络直接回归坐标。

(3)基于模型的3D人体姿态估计 Model-based 3D HPE
基于模型的方法通常采用人体参数模型 (human body model)或运动学模型(kinematic model)从图像中估计人体的姿态和形状。
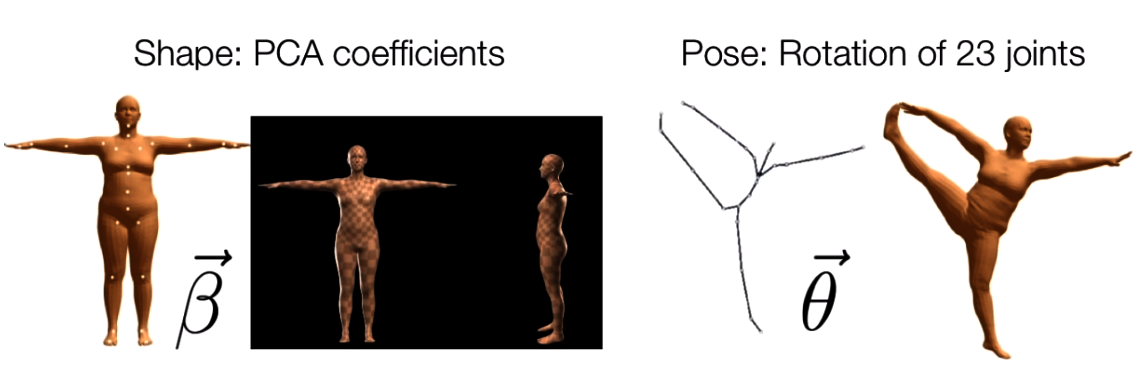
SMPL(Skinned Multi-Person Linear Model)是最常用的参数控制的三维人体统计模型之一,它将人体编码为两类参数:Pose参数$\theta$和Shape参数$\beta$。
- Pose参数$\theta$:具有$24 \times 3$个标量值的姿态向量(定义$K=24$个关节点,并建立一组关节点树),该参数代表每个关节点相对于其父节点的局部旋转向量的轴角式表达,用于控制人体姿态变化;
- Shape参数$\beta$:具有$10$个标量值的形状向量,其每一维度都可看做人体形状的某个指标,用于控制人体形状变化。
⚪ SMPLify
给定一个图像,使用基于 CNN 的方法来预测 2D 关节位置。然后将 3D 身体模型SMPL拟合到此,以估计 3D 身体形状和姿势。

⚪ SMPLify-X
本文提出了SMPL三维人体模型的改进版本:SMPL-X (eXpressive),在原有人体姿态的基础上增加了手部姿势和面部表情。为从单张图像中学习三维人体姿态,作者提出了SMPLify模型的改进版本:SMPLify-X;后者具有更好的姿态先验、更多细节的碰撞惩罚、性别检测和更快的PyTorch实现。
4. 人体姿态估计的技巧 Bag of Tricks
(1)数据处理
⚪ Augmentation by Information Dropping (AID)
模型在定位图像中的人体关键点时通常会使用两种信息:外观信息和约束信息。外观信息是定位关键点的基础,而约束信息主要包含人体关键点之间固有的相互约束关系以及人体和环境交互形成的约束关系。
本文引入信息丢弃的正则化手段,通过在训练过程中以一定的概率丢弃关键点的外观信息,以此避免训练过程过拟合外观信息而忽视约束信息。

⚪ PoseAug
本文针对2D坐标到3D坐标成对标注信息的姿态估计任务,对3D数据进行增强。对数据进行三个方面的变换:骨骼角度、骨骼长度、旋转和变形;并用判别器来评估生成的数据的合理性。

⚪ Unbiased Data Processing (UDP)
对于离散像素点进行翻转和下采样等变换后可能会引入位置误差,通过将像素点定义到连续图像空间来消除这种误差。

⚪ SmoothNet
SmoothNet 是一个专门用于姿态估计抖动缓解的时序细化网络。它通过学习人体运动的自然平滑特性,利用长时序关系对每个关节进行建模,从而显著降低姿态估计中的抖动误差。为了进一步提升性能,SmoothNet 引入了运动信息,显式地建模速度和加速度。

(2)量化误差消除
在Heatmap-based方法中,对预测热图解码时是把模型输出的高斯概率分布图用Argmax得到最大相应点坐标。由于Argmax操作最的结果只能是整数,这就导致了经过下采样的特征图永远不可能得到输入图片尺度的坐标精度,因此产生了量化误差(quantization error)。
⚪ Distribution-Aware coordinate Representation of Keypoint (DARK)
DARK方法利用高斯分布的泰勒展开来缓解热图回归的量化误差,适用于热图概率分布函数的对数多项式需不高于二次。通常模型的预测热图并不是良好的高斯形式,因此可以首先对输出热图应用高斯模糊。
\[\mu = m-(\mathcal{H}''(m))^{-1} \mathcal{H}'(m)\]
⚪ Pixel-in-Pixel Net (PIP-Net)
PIP-Net是对Heatmap和Regression两种形式的统一,对特征图上的每个特征预测关键点的存在性得分和关键点相对于左上角的坐标偏移,并预测周围最近关键点的坐标偏移。

⚪ Simple Coordinate Classification (SimCC)
SimCC将关键点坐标$(x, y)$用两个独立的一维向量进行表征,通过缩放因子$k(\geq1)$将定位精度增强到比单个像素更小的级别。

⚪ Differentiable Spatial to Numerical Transform (DSNT)
DSNT通过构造坐标矩阵,并与归一化的热图计算$F$范数,从而把热图转换为关节点坐标。
\[DSTN(\hat{Z}) = \left[ \langle \hat{Z},X\rangle_F, \langle\hat{Z},Y\rangle_F\right]\]
⚪ Integral Pose Regression (IPR)
IPR把从预测热图中取最大值操作修改为取期望操作:关节被估计为热图中所有位置的积分,由它们的归一化概率加权。
\[\boldsymbol{J}_k = \int_{\boldsymbol{p} \in \Omega} \boldsymbol{p} \cdot \tilde{\boldsymbol{H}}_k(\boldsymbol{p}) = \int_{\boldsymbol{p} \in \Omega} \boldsymbol{p} \cdot \frac{e^{\boldsymbol{H}_k(\boldsymbol{p})}}{\int_{\boldsymbol{q} \in \Omega}e^{\boldsymbol{H}_k(\boldsymbol{q})}}\]⚪ Debiased IPR
IPR用Soft-Argmax近似Argmax的结果,只有在响应值足够大时近似才比较精确。这是因为Softmax倾向于让每一项的值都非零,导致原本多余的长尾也参与了期望值的计算。可以把这部分从期望结果中减去:
\[\begin{aligned} \begin{bmatrix} x_0 \\ y_0 \end{bmatrix}= \begin{bmatrix} \frac{C}{C-hw}x_J-\frac{h^2w}{2(C-hw)} \\ \frac{C}{C-hw}y_J-\frac{hw^2}{2(C-hw)} \end{bmatrix} \end{aligned}\]
⚪ Sampling-Argmax
Soft-Argmax 仅约束概率图的期望值,而不约束其形状,导致模型在训练时缺乏像素级监督,影响性能。Sampling-Argmax提出了一种新的训练目标:最小化定位误差的期望值,而不是最小化期望值的误差,来隐式约束概率图的形状,从而提高定位精度。
\[L=d(y_t,E[y]) \to L=E_y[d(y_t,y)]\]⚪ Confidence-Aware Learning (CAL)
CAL采用偏移量学习方法,同时预测粗略位置和偏移量。通过在粗略位置上添加偏移量来获得最终预测,从而缓解量化误差问题。
- CAL引入了高斯加权的热图,通过将二值热图与高斯分布相乘,为靠近真实关节位置的像素赋予更高的权重,从而提高粗略位置预测的准确性。
- CAL提出了高斯偏移量加权方法。通过收集预测热图中粗略位置与真实位置之间的相对偏移量,并使用高斯混合模型(GMM)对其进行建模,生成混合高斯掩码(MGM)来加权偏移量损失。

⚪ Symmetric Integral Keypoints Regression (SIKR)
IPR通过L1损失在反向传播时梯度形式是不对称的,梯度计算会对每个热图像素乘上它的坐标值,因此坐标值较大的像素梯度变化幅度更大。SIKR直接对反向传播时的梯度进行修改,调整为坐标对称的形式:
\[\frac{\partial L_{reg}}{\partial p_x} = A_{grad} \cdot sign(x-\hat{\mu}) \cdot sign(\hat{\mu} - \mu)\](3)轻量化
⚪ Lite-HRNet
Lite-HRNet首先在HRNet中通过Shuffle Block替换残差模块;进一步发现Shuffle Block中的1x1卷积成为了计算瓶颈,于是采用SENet模块替换1x1卷积进行特征聚合。

⚪ HR-NAS
- paper:HR-NAS: Searching Efficient High-Resolution Neural Architectures with Lightweight Transformers
本文设计了一个简单的轻量级视觉Transformer模块,然后在HRNet结构基础上进行神经结构搜索,将原本的3x3卷积模块扩展成了3x3,5x5,7x7,轻量级视觉Transformer模块等四种模块拼接的模块,然后搜索这四种模块的比例和通道数。

⚪ Lite Pose
对于轻量级姿态估计模型而言,多分支高分辨率的结构是比较冗余的。Lite Pose采用带有残差连接的单分支网络:

⚪ MoveNet
MoveNet整体的结构如图所示。Backbone部分是带三层deconv的MobileNetv2。Neck部分使用了FPN来做不同尺度的特征学习和融合。Head部分有四个预测头,分别是:
- Center Heatmap $[B, 1, H, W]$:预测每个人的几何中心,主要用于存在性检测;
- Keypoint Regression $[B, 2K, H, W]$:基于中心点来回归17个关节点坐标值;
- Keypoint Heatmap $[B, K, H, W]$:每种类型的关键点使用一张Heatmap进行检测;
- Offset Regression $[B, 2K, H, W]$:回归Keypoint Heatmap中各高斯核中心跟真实坐标的偏移值。

(4)训练技巧
⚪ Online Knowledge Distillation (OKDHP)
OKDHP训练了一个多分支网络,其中每个分支都被当做独立的学生模型;教师模型是通过加权集成多个分支的heatmap结果后形成的。通过优化Pixel-wise KL Divergence损失来优化每个学生分支模型。

⚪ Bone Loss
Bone Loss计算了姿态骨骼长度比例的损失:
\[\mathcal{L}_{\text{bone}}(J, Y) = \sum_{(i,j) \in \epsilon} \left| ||J_{2D_i}-J_{2D_j}|| - ||Y_{2D_i}-Y_{2D_j}|| \right|\]其中$J_{2D}$是模型预测的关键点,$Y_{2D}$是Ground Truth,该公式约束了每个关键点之间的空间关系,能帮助学习到骨骼长度关系,避免预测出一些诡异的不存在的姿态。
⚪ Heatmap Distribution Matching (HDM)
HDM把人工渲染高斯热图的监督信息替换为更简单的监督信号,通过插值的方式直接将连续空间上的坐标用相邻的离散像素计算表示。损失函数直接优化预测热图与监督热图的Wasserstein距离。

⚪ Pose Equivariant Contrastive Learning (PeCLR)
PeCLR是一个适用于姿态估计任务的具有几何变换等变性的对比学习目标函数,该目标不直接作用于正样本对的特征$z_i,z_j$,而是这两个特征做几何变换的逆变换。
\[L_{i,j} = - \log \frac{\exp(sim(t_i^{-1}(z_i),t_i^{-1}(z_j))/\tau)} {\sum_{k=1:2N,k\neq i} \exp(sim(t_i^{-1}(z_i),t_i^{-1}(z_k))/\tau)}\]
⚪ Residual Log-likelihood Estimation (RLE)
给定输入图像$I$,回归模型预测一个分布$P_Θ(x\mid I)$,其中$x$表示关键点的坐标。本文提出了残差对数似然估计(RLE)。假设存在一个简单的分布$Q(\overline{x})$,通过引入归一化流学习$P_{opt}(\overline{x})-Q(\overline{x})$的残差来优化目标分布,从而减少对复杂分布的直接建模难度。

⚪ Self-Correctable and Adaptable Inference (SCAI)
SCAI是一种自监督的推理方法,能在完全没有标注的测试样本上进行训练,逐步修正预测结果,带来显著的性能提升。SCAI方法的输入是姿态模型预测的Heatmap,通过近端关节点热图预测远端关节点热图,学习预测结果的误差并进行反馈。

⚪ DWPose
DWPose是一种两阶段姿态蒸馏方法,用于提升全身姿态估计的效率和精度。在第一阶段利用教师模型的中间特征和最终输出对轻量级学生模型进行蒸馏,并采用权重衰减策略逐步减少蒸馏的权重。第二阶段蒸馏是一种自蒸馏方法,学生模型通过自身的输出对头部进行Logit 蒸馏。

⚪ POse Matching Network (POMNet)
本文提出了一个名为 Category-Agnostic Pose Estimation (CAPE) 的新任务,目标是开发一种能够处理任意类别物体姿态估计的模型,仅需少量标注样本即可检测新类别的关键点。
作者设计了一个名为 POse Matching Network (POMNet) 的框架,将姿态估计问题转化为关键点匹配问题,POMNet由三个部分组成:
- 特征提取器:提取查询图像和支持图像的特征;
- 关键点交互模块:通过高效的注意力机制增强支持关键点特征;
- 匹配头:在查询图像中找到与增强后的关键点特征最匹配的位置,并以热图形式输出预测结果。

5. 人体姿态估计的评估指标 Pose Estimation Evaluation
二维人体姿态估计中常用的评估指标包括PCP, PCK, OKS, AP, mAP。三维人体姿态估计中常用的评估指标包括MPJPE。
⚪ PCP:Percentage of Correct Parts
PCP指标以肢体的检出率作为评估指标。考虑每个人的左右大臂、小臂、大腿、小腿共计$4$个肢体(对应$8$个关节点)。如果两个预测关节位置和真实肢体关节位置之间的距离不超过肢体长度的一半,则认为肢体已经被正确地检测到。

对于某个特定部位,完整数据集上的PCP指标计算为:
\[\text{PCP} = \frac{\text{整个数据集中正确检出此部位数量}}{\text{整个数据集中此部位总数}}\]⚪ PCK:Percentage of Correct Keypoints
PCK指标衡量正确估计出的关键点比例,这是比较老的人体姿态估计指标,在$2017$年比较广泛使用,现在基本不再使用。但是在工程项目中,使用该指标评价训练模型的好坏还是蛮方便的。
如果预测关节点和真实关节点之间的距离在某个阈值范围内,则认为检测到的关节点是正确的;其中阈值通常是根据目标的比例设置的。第$i$个关键点的PCK指标计算如下:
\[PCK_{i}@T_k = \frac{\sum_{p}^{} {\delta (d_{pi} ≤ T_k*d_{p}^{def})}}{\sum_{p}^{} {1}}\]其中:
- $p$表示第$p$个人
- $T_k$表示人工设定的阈值,$T_k \in [0:0.01:0.1]$
- $d_{pi}$表示第$p$个人的第$i$个关键点预测值与人工标注值之间的欧氏距离
- $d_{p}^{def}$表示第$p$个人的尺度因子,不同数据集中此因子的计算方法不一样。FLIC数据集是以当前人的躯干直径作为尺度因子,即左肩到右臀的欧式距离或者右肩到左臀的欧式距离;MPII数据集是以当前人的头部直径作为尺度因子,即头部左上点与右下点的欧式距离,使用此尺度因子的姿态估计指标也称PCKh。
- $\delta$表示如果条件成立则为$1$,否则为$0$
算法的PCK指标是对所有关键点计算取平均:
\[PCK@T_k = \frac{\sum_{p}^{} \sum_{i}^{} \delta (d_{pi} ≤ T_k*d_{p}^{def})}{\sum_{p} \sum_{i}^{} {1}}\]例如,$PCK@0.2$是指阈值设置为躯干直径的$20\%$,$PCKh@0.5$是指阈值设置为头部直径的$50\%$。
PCK指标计算参考代码:
def compute_pck_pckh(dt_kpts,gt_kpts,refer_kpts):
"""
:param dt_kpts:算法检测输出的估计结果,shape=[n,h,k]=[行人数,2,关键点个数]
:param gt_kpts: groundtruth人工标记结果,shape=[n,h,k]
:param refer_kpts: 计算尺度因子的关键点,用于预测点与groundtruth的欧式距离的scale。
pck指标:躯干直径,左肩点-右臀点的欧式距离;
pckh指标:头部长度,头部对角线的欧式距离;
:return: 相关指标
"""
dt=np.array(dt_kpts)
gt=np.array(gt_kpts)
assert(len(refer_kpts)==2)
assert(dt.shape[0]==gt.shape[0])
ranges=np.arange(0.0,0.1,0.01)
kpts_num=gt.shape[2]
ped_num=gt.shape[0]
# compute dist
scale=np.sqrt(np.sum(np.square(gt[:,:,refer_kpts[0]]-gt[:,:,refer_kpts[1]]),1))
dist=np.sqrt(np.sum(np.square(dt-gt),1))/np.tile(scale,(gt.shape[2],1)).T
# compute pck
pck = np.zeros([ranges.shape[0], gt.shape[2]+1])
for idh,trh in enumerate(list(ranges)):
for kpt_idx in range(kpts_num):
pck[idh,kpt_idx] = 100*np.mean(dist[:,kpt_idx] <= trh)
# compute average pck
pck[idh,-1] = 100*np.mean(dist <= trh)
return pck
⚪ OKS:Object Keypoint Similarity
OKS是目前常用的人体骨骼关键点检测算法的评估指标,该指标受目标检测中的IoU指标启发,目的是计算关键点预测值和标注真值的相似度。
第$p$个人的OKS指标计算如下:
\[OKS_p = \frac{\sum_{i}^{} {\exp\{-d_{pi}^{2}/2S_{p}^{2} \sigma_{i}^{2}\} \delta (v_{pi} > 0)}}{\sum_{i}^{} {\delta (v_{pi} > 0)}}\]其中:
- $i$表示第$i$个关键点
- $d_{pi}$表示第$p$个人的第$i$个关键点预测值与人工标注值之间的欧氏距离
- $S_{p}$表示第$p$个人的尺度因子,其值为行人检测框面积的平方根$S_{p}=\sqrt{wh}$,$w$、$h$为检测框的宽和高
- $\sigma_{i}$表示第$i$个关键点的归一化因子,该因子是通过对所有的样本集中关键点由人工标注与真实值存在的标准差,$\sigma$越大表示此类型的关键点越难标注。对COCO数据集中的$5000$个样本统计出$17$类关键点的归一化因子,取值为:{鼻子:0.026,眼睛:0.025,耳朵:0.035,肩膀:0.079,手肘:0.072,手腕:0.062,臀部:0.107,膝盖:0.087,脚踝:0.089},此值可以看作常数,如果使用的关键点类型不在此当中,则需要统计方法计算
- $v_{pi}$表示第$p$个人的第$i$个关键点的可见性,对于人工标注值,$v_{pi}=0$表示关键点未标记(图中不存在或不确定在哪里),$v_{pi}=1$表示关键点无遮挡且已标注,$v_{pi}=2$关键点有遮挡但已标注。对于预测关键点,$v_{pi}’=0$表示没有预测出,$v_{pi}’=1$表示预测出
- $\delta$表示如果条件成立则为$1$,否则为$0$
OKS指标计算参考代码:
sigmas = np.array([.26, .25, .25, .35, .35, .79, .79, .72, .72, .62,.62, 1.07, 1.07, .87, .87, .89, .89])/10.0
variances = (sigmas * 2)**2
def compute_kpts_oks(dt_kpts, gt_kpts, area):
"""
:param dt_kpts: 关键点检测结果 dt_kpts.shape=[3,k],dt_kpts[0]表示横坐标值,dt_kpts[1]表示纵坐标值,dt_kpts[2]表示可见性,
:param gt_kpts: 关键点标记结果 gt_kpts.shape=[3,k],gt_kpts[0]表示横坐标值,gt_kpts[1]表示纵坐标值,gt_kpts[2]表示可见性,
:param area: groundtruth中当前一组关键点所在人检测框的面积
:return: 两组关键点的相似度oks
"""
g = np.array(gt_kpts)
xg = g[0::3]
yg = g[1::3]
vg = g[2::3]
assert(np.count_nonzero(vg > 0) > 0)
d = np.array(dt_kpts)
xd = d[0::3]
yd = d[1::3]
dx = xd - xg
dy = yd - yg
e = (dx**2 + dy**2) /variances/ (area+np.spacing(1)) / 2 #加入np.spacing()防止面积为零
e=e[vg > 0]
return np.sum(np.exp(-e)) / e.shape[0]
⚪ AP:Average Precision
对于单人姿态估计,首先计算OKS指标,然后人为给定一个阈值$T$,通过所有图像计算AP指标:
\[AP = \frac{\sum_{p}^{} {\delta (OKS_p) > T}}{\sum_{p}^{} {1}}\]对于多人姿态估计,如果采用的检测方法是自顶向下,先把所有的人找出来再检测关键点,那么其AP计算方法同上;
如果采用的检测方法是自底向上,先把所有的关键点找出来再组成人,假设一张图片中共有$M$个人,预测出$N$个人,由于不知道预测出的$N$个人与标记的$M$个人之间的对应关系,因此需要计算标记的每个人与预测的$N$个人的OKS指标,得到一个大小为${M}\times{N}$的矩阵,矩阵的每一行为标记的一个人与预测结果的$N$个人的OKS指标,然后找出每一行中OKS指标最大的值作为当前标记人的OKS指标。最后每一个标记人都有一个OKS指标,然后人为给定一个阈值$T$,通过所有图像计算AP指标:
\[AP = \frac{\sum_{m}^{} \sum_{p}^{} {\delta (OKS_p) > T}}{\sum_{m}^{} \sum_{p}^{} {1}}\]⚪ mAP:mean Average Precision
mAP是给AP指标中的人工阈值$T$设定不同的值,对这些阈值下得到的AP求平均得到的结果。
\[T \in [0.5:0.05:0.95]\]⚪ MPJPE:Mean Per Joint Position Error
MPJPE衡量各个关节位置误差的平均值。关节位置误差是指真实关节点与预测关节点之间的欧几里得距离。MPJPE的计算公式为:
\[MPJPE = \frac{1}{N_J} \sum_{j=l}^{N_J}\sqrt{\sum_i (p_{i,j}-\hat{p}_{i,j})^2}\]其中,$N_J$是关节数,$p_{i,j}$是第$j$个关节的真实位置的第$i$个维度,$\hat{p}_{i,j}$是第$j$个关节的预测位置的第$i$个维度。
6. 姿态估计数据集
(1)2D姿态估计数据集
常用的二维人体姿态估计数据集包括:
⚪ MPII
MPII人体姿态数据集是用于评估关节式人体姿态估计的常用基准之一。该数据集包括大约25000张图像,其中包含超过40000名带有关节注释的人体目标,涵盖410种人类活动,并且每个图像都提供有活动标签。每个图像都是从YouTube视频中提取的,并提供了前面和后面的未注释帧。此外,测试集提供了更丰富的注释,包括身体部位遮挡以及3D躯干和头部方向。

MPII原始的标注数据是matlab格式的,也可以下载json格式。MPII的标注文件是一个列表,每一项代表一个人体以及该人体的标注,以下是每一项人体标注的内容解析:
[{
"joints_vis": [1, ···], # 关节点是否可见,长度16
"joints": [[x1,y1], ···], # 关节点坐标
"image": "000003072.jpg", # 对应的图像名称
"scale": 1.946961, # scale*200为人体边界框的边长(正方形框)
"center": [754.0, 335.0] # 人体边界框的中心
}, ···]
MPII格式中关节点的对应关系为:
0 - r ankle, 1 - r knee, 2 - r hip, 3 - l hip
4 - l knee, 5 - l ankle, 6 - pelvis, 7 - thorax
8 - upper neck, 9 - head top, 10 - r wrist, 11 - r elbow
12 - r shoulder, 13 - l shoulder, 14 - l elbow, 15 - l wrist
⚪ MS COCO
COCO数据集的样本数$300000$,$100000$人。关节点个数$18$,关节点对应关系如下:

COCO的标注中包含 4 个部分/字段,”info” 描述数据集,”licenses” 描述图片来源,”images” 和 “annotations” 是主体部分。
“images” 部分是一个列表,每一项是一张图片的基本信息与图片 ID,ID是为了方便 annotation 回溯对应图片,该部分格式如下:
[{
"license": 3,
"file_name": "000000017905.jpg",
"coco_url": "http://images.cocodataset.org/val2017/000000017905.jpg",
"height": 640,
"width": 480,
"date_captured": "2013-11-16 18:01:33",
"flickr_url": "http://farm1.staticflickr.com/44/173771776_53b9c22bb6_z.jpg",
"id": 17905 # 对应 annotation 中的 image_id
}, ···]
“annotations” 部分是一个列表,每一项是一个对象(人体、汽车等等)的一条标注,该部分中与姿态估计相关的数据格式如下:
"num_keypoints": 17
"keypoints": [x1,y1,vis1, ···], # 特征点坐标与可见性,共17个个特征点,长度3*17。
# 可见性对应关系为 { 0: "不可见", 1: "遮挡", 2: "可见" }。
"image_id": 17905, # 图片ID
"bbox": [81.27, 229.19, 119.39, 364.68], # [l, t, w, h] 格式的 bounding box
"category_id": 1, # 标注对象的类别,如果是 1 则是人体,选入姿态估计任务的数据
"id": 2157397 # 每一条标注数据的ID
⚪ AI Challenge (AIC)
AIC数据集包括:$210000$训练集,$30000$验证集,$30000$测试集;关节点个数$14$,$380000$人。
AIC数据集在论文主要以 “extra data” 的形式出现,因此最重要的是 “如何利用 AIC 数据进行预训练,提升 COCO 数据集上的结果”。有两种思路,一是在 AIC 数据集上先训练,然后在 COCO train2017 数据集上训练;另一种思路是合并 AIC 和 COCO train2017 数据集。因为两个数据集 “keypoints” 中特征点个数与“index与特征点对应关系”是不同的,不管哪种思路,都需要将 AIC “keypoints” 内容转换为 COCO 格式。
转换后的AIC数据集下载见链接。转换后 json 字段格式与 COCO 相同,可以参见 COCO 的标注格式。转换后的 AIC 标注格式与 COCO 不同的是 [“annotations”][“keypoints”] 字段,包括特征点个数与“index与特征点对应关系”是不同的。AIC 共14个个特征点,长度3*14,可见性对应关系与COCO相同。index与特征点对应关系如下:
{ 0: "right shoulder", 1: "right elbow", 2: "right wrist", 3: "left shoulder",
4: "left elbow", 5: "left wrist", 6: "right hip", 7: "right knee",
8: "right ankle", 9: "left hip", 10: "left knee", 11: "left ankle",
12: "head tops" 13: "upper neck" }
aic2coco标注格式转换代码见链接。
(2)3D姿态估计数据集
由于 3D 关键点标注难度较大,目前的数据集基本上都借助于MoCap和可穿戴IMU设备来完成数据标注,也正因为此,大多数数据集都局限于室内场景。
常用的三维人体姿态估计数据集包括:
⚪ Human3.6M
- paper:Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments
Human3.6M 是目前 3D HPE 任务最为常用的数据集之一,包含了360万帧图像和对应的 2D/3D 人体姿态。该数据集在实验室环境下采集,通过4个高清相机同步记录4个视角下的场景,并通过 MoCap 系统获取精确的人体三维关键点坐标及关节角。如图所示,Human3.6M 包含了多样化的表演者、动作和视角。
⚪ MPI-INF-3DHP
Human3.6M 尽管数据量大,但场景单一。为了解决这一问题,MPI-INF-3DHP 在数据集中加入了针对前景和背景的数据增强处理。具体来说,其训练集的采集是借助于多目相机在室内绿幕场景下完成的,对于原始的采集数据,先对人体、背景等进行分割,然后用不同的纹理替换背景和前景,从而达到数据增强的目的。测试集则涵盖了三种不同的场景,包括室内绿幕场景、普通室内场景和室外场景。因此,MPI-INF-3DHP 更有助于评估算法的泛化能力。
⚪ CMU Panoptic
CMU Panoptic是一个大型的多目图像数据集,提供了31个不同视角的高清图像以及10个不同视角的 Kinect 数据,包含了65段视频(总时长5.5 h),3D skeleton 总数超过150万。该数据集还包含了多个多人场景,因此也成为了多人 3D HPE 的 benchmark 之一。
⚪ AMASS
AMASS是一个经过SMPL参数标准化的三维人体动作捕捉数据集合。现有的人体mocap数据集使用不同的人体参数,很难将其集成到单个数据集中共同使用,作者将这些数据集使用SMPL模型进行统一参数化,将其整合成一个新的数据集。所整合的数据集包括CMU、MPI-HDM05、MPIPose Limits、KIT、BioMotion Lab、TCD和ACCAD数据集中的样本。


