TokenPose:学习人体姿态估计的关键点token.
人体姿态估计任务主要依赖两方面的信息:视觉信息(图像纹理信息)和解剖学的约束信息(关节之间的连接关系)。对于CNN来说,其优势在于对于图像纹理信息的特征提取能力极强,能学习到高质量的视觉表征,但在约束信息的学习上则有所不足。本文利用了Transformer中多头注意力机制的特点,能学到位置关系上的约束,以及不同关键点之间的关联性,并且极大地减少了模型的参数量和计算量。

Token在NLP中是指每个词或字符用一个特征向量来表示。在本工作中设置了两种Token类型,一种是visual token,是将特征图按patch拆分后拉成的一维特征向量;另一种是keypoint token,专门学习每一个关键点的特征表示。将两种Token特征一起放入Transformer,于是模型可以同时学习到图像纹理信息和关键点连接的约束信息。
TokenPose先通过一个基于CNN的骨干网络来提取特征图,将特征图拆分为patch后拉平为一维向量,经过一个线性函数(全连接层)投影到d维空间,这些向量称为visual tokens,负责图片纹理信息的学习。考虑到姿态估计任务对于位置信息是高度敏感的,因此还要给token加上2d位置编码。然后通过随机初始化一些可学习的d维向量来作为keypoint tokens,每个token对应一个keypoint。将两种token一起送入transformer进行学习,并将输出的keypoint tokens通过一个MLP映射到HxW维,以此来预测heatmap。

在实验部分作者通过对注意力进行可视化的方式,验证了关键点约束信息的学习情况。对不同transformer层对应的每个关键点注意力进行了可视化,可以清晰地看到一个逐渐确定到对应关节的过程:
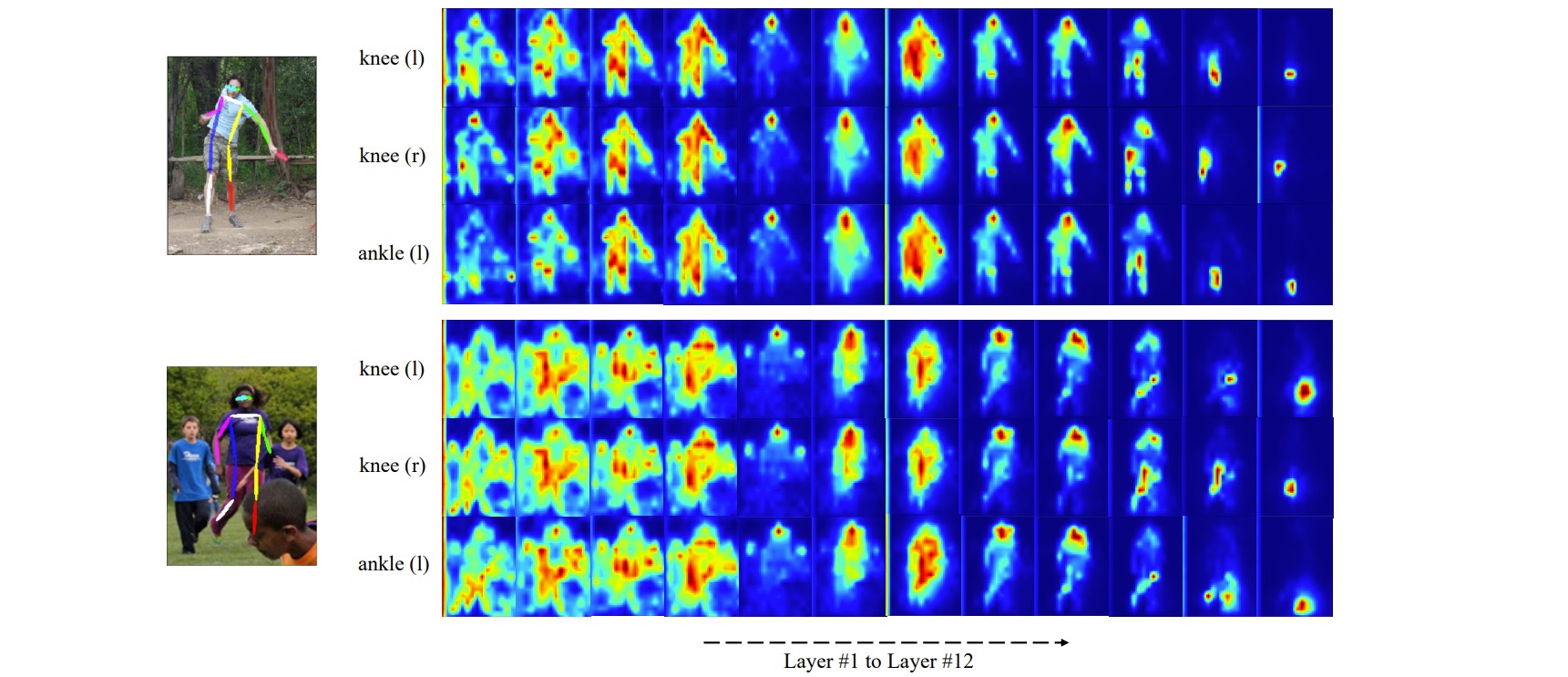
对学习完成的keypoint tokens计算内积相似度也可以发现,相邻关节点和左右对称位置的关节的token相似度是最高的:



