单RGB图像3D多人姿态估计的相机距离感知的自顶向下方法.
- paper:Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image
本文提出了一种自顶向下的多人姿态估计方法,需要先将每个目标从2D图像中裁剪出来,再进行根节点的深度估计和相对根节点的姿态估计。算法的管道分为三个部分:
- 边界框检测网络DetectNet:检测每个目标的边界框;
- 根节点定位网络RootNet:定位根节点位置$(x_R,y_R,Z_R)$,其中$x_R$和$y_R$是像素坐标,$Z_R$是绝对深度坐标;
- 相对根节点的3D单人姿态估计网络PoseNet:估计相对根节点的3D姿态$(x_j,y_j,Z_j^{rel})$,其中$x_j$和$y_j$是在裁剪图像中的像素坐标,$Z_j^{rel}$是相对根节点的深度值。

⚪ DetectNet
Mask RCNN作为DetectNet。backbone 产生局部和全局特征(ResNet & FPN);RPN产生边界框候选;再通过RoIAlign提取特征,进行分类和回归。
⚪ RootNet
由于RootNet预测的深度值是相机中心的坐标系,所以2D图像关键点要映射到相机中心坐标空间中。从整张图片中定位2D姿态位置是较为容易的,因为整张图片提供了充足的信息。但是如果仅从抠出来的人体图片中去估计深度,就很困难了。所以引入了一个新的距离度量$k$,定义为
\(k=\sqrt{\alpha_x\alpha_y\frac{A_{real}}{A_{img}}}\) 其中$\alpha_x,\alpha_y$是焦距长度除以$x$轴和$y$轴的逐像素距离因子($pixel$);$A_{real}$是人体在实际空间的面积($mm^2$);$A_{img}$是人体在图像空间的面积($pixel^2$)。$k$是相机到目标的绝对深度的近似,是在实际面积和成像面积的比率和给定的相机参数的前提下得到的。
相机和目标之间的距离可以如以下公式所示:
\[d=\alpha_x\frac{l_{x,real}}{l_{x,img}}=\alpha_y\frac{l_{y,real}}{l_{y,img}}\]
其中$l_{x,real}, l_{x,img}, l_{y,real}, l_{y, img}$是一个目标在真实空间和图片空间在 $x$ 轴和 $y$ 轴 的长度。将上面的公式等号两项相乘起来开根号,就是相机到目标的绝对深度的近似。
假定$A_{real}$是一个常数,$\alpha_x$和$\alpha_y$可以从数据集中获得,所以一个目标的距离可以通过图像中边界框的面积得到。下图展示了$k$值与真实距离的相关性:

尽管$k$可以表示相机到人体的距离,但因为它是按照规则计算出来的,有可能是错误的。
- $A_{img}$是扩展二维边界框得到的,尽管目标到相机的距离是一样的,其也可能因为其表现不同(有不同的$A_{img}$)而有不同的$k$值。
- 不同的个体差异+不同相机距离也可以有一样的(相似的)的$A_{img}$。

为解决这个问题,设计RootNet去利用图像特征纠正$A_{img}A$,得到最终的$k$。RootNet输出一个纠正因子$\gamma$,与$A_{img}$相乘后得到纠正后的图像面积。在训练时,不同$\alpha_x$和$\alpha_y$的数据都用于训练。测试时没有$\alpha_x$和$\alpha_y$,将$\alpha_x$和$\alpha_y$设为任意数值代替,就能得到对应的深度估计值$Z_R$。
RootNet的网络设计如下图所示:网络架构由三个部分组成:
- backbone提取有用的全局特征;
- 2D图像估计:用三个连续的deconv/BN/ReLU进行上采样,然后再使用一个$1\times 1$卷积以生成根关节点的2D heatmap;
- 深度估计部分:应用全局平均池化,再通过$1\times 1$卷积输出一个标量值$\gamma$。
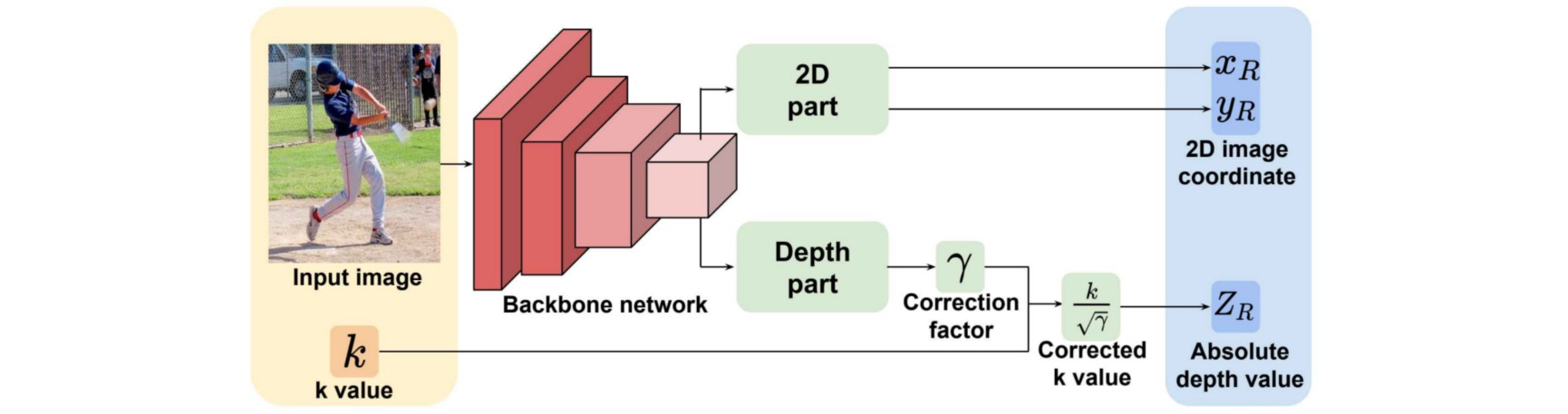
产生$\gamma$值之后,绝对深度值$Z_R=\frac{k}{\sqrt{\gamma}}$。在实际上,可以将RootNet的输出值变成$\gamma’=\frac{1}{\sqrt{\gamma}}$,那么绝对深度值$Z_R=\gamma’k$。
RootNet的损失函数为$L_1$距离。
\(L_{root}=\| R-R^* \|_1\)
⚪ PoseNet
- backbone:使用ResNet从裁剪后的图像后抽取有用的全局特征;
- 姿态检测部分:进行连续的三个deconv/BN/ReLU,再加$1\times 1$卷积应用在上采用层去产生每个关节点的3D heatmap。使用soft-argmax操作去提取2D图像坐标$(x_j, y_j)$和相对根节点的深度值$Z^{rel}_j$。
PoseNet的损失函数为$L_1$距离:
\[L_{pose}=\| P_j^{rel}-P_j^{rel*} \|_1\]⚪ 训练细节
在COCO上预训练的Mask RCNN作为DetectNet,而不经过微调。RootNet和PoseNet的backbone为ResNet-50,在ImageNet上预训练。其余的层采用高斯分布初始化(标准差$\alpha=0.001$)。
让RootNet和PoseNet进行联合训练与不进行联合训练的实验结果如下:其中MRPE为根节点位置的误差均值。作者认为RootNet和PoseNet的任务关联度不高,联合训练会导致训练难度更大,导致准确度更低。最终决定采用两个网络进行分别训练,而不是单独训练。



