关联嵌入:端到端学习关节点检测与分组.
本文提出了一种bottom-up的多人姿态估计方法Associative Embedding来处理关节点检测和分组问题。多人目标检测可以通过检测人的关节点然后再将它们进行分组(属于同一个人的关节点为一组)解决,类似的方法还可以推广到大部分计算机视觉的任务:检测一些小的单元,然后将它们组合成更大的单元。例如实例分割问题可以看作是检测一些相关的像素然后将它们组合成一个目标实例。

Associative Embedding是一种表示关节检测和分组任务的输出的新方法,其基本思想是为每个检测点引入一个实数,用作识别对象所属组的“标签”,标签将每个检测点与同一组中的其他检测点相关联。使用一个损失函数使得如果相应的检测点属于同一组则促使这一对标签具有相似的值。
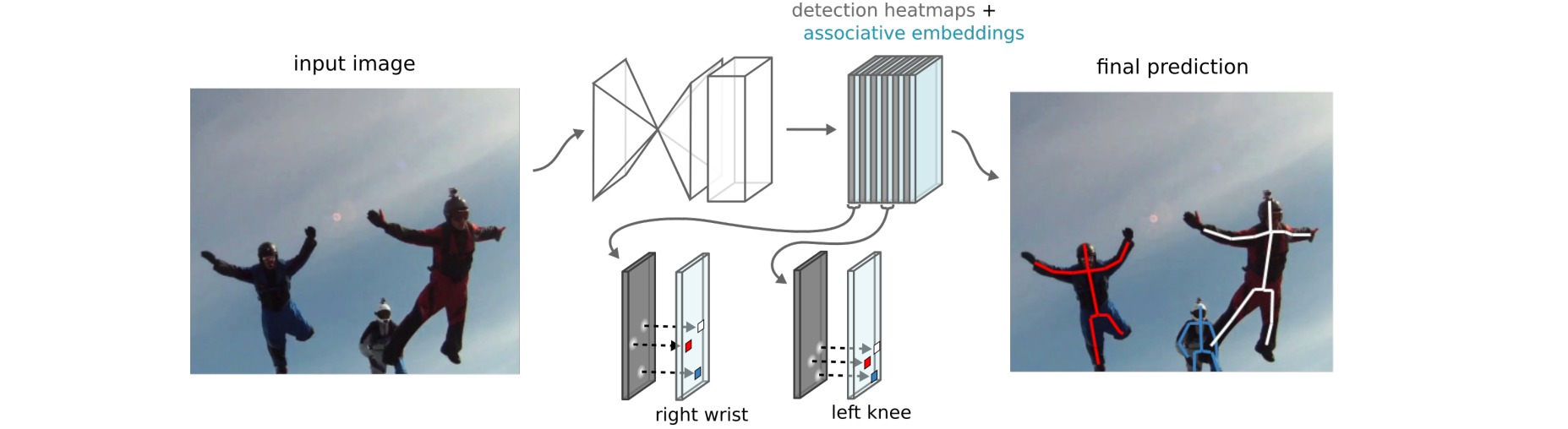
检测关节点的主体结构采用Stacked Hourglass Network,对每个关节点输出检测的热图和标签的热图,然后再将带有相似标签的关节点分组作为单个人的关节点集合。
Stacked Hourglass模型输出目标人物的人体关节点热图,热图中最高激活值将作为关节点的定位像素。这种网络结构的设计是为了兼顾全局与局部的信息,使得在获取整个人体结构的同时又能够进行精准的定位。

作者对原来的网络结构进行了细微的调整,在每次分辨率下降时增加输出的特征的数量($256$-$386$-$512$-$768$),另外每一层使用单个$3×3$卷积替换残差块。对于多人姿态估计任务,在训练时使用4个hourglass模块,输入大小为$512×512$,输出大小为$128×128$,batch size为$32$,学习速率为$2e-4$($100$K次迭代后降为$1e-5$)。
多人姿态估计与单人姿态估计的区别在于多人的热图应具有多个峰值(例如属于不同人的多个左手腕)。为了实现多人姿态估计,网络需要对每个关节点的每个像素位置产生一个标签,也就是说,每个关节点的热图对应一个标签热图,因此如果一张图片中待检测的关节点有$m$个,则网络理想状态下会输出$2m$个通道,$m$个通道用于定位,$m$个通道用于分组。
为了将检测结果对应到个人,使用非极大值抑制来取得每个关节热图峰值,然后检索其对应位置的标签,再比较所有身体位置的标签,找到足够接近的标签分为一组,这样就将关节点匹配单个人身上。
检测损失$L_d$使用均方误差,即计算预测关节点热图与标签热图之间的均方误差。分组损失$L_g$衡量预测的分组热图和分组标签匹配得有多好,即检索图片中所有人的所有身体节点的分组标签,然后比较每个人的标签,同一个人的标签应该相同,不同人的标签应该不同。
记$h_k \in R^{H\times W}$是预测的第$k$个关节点的分组热图,$h(x)$是像素$x$对应的标签值。对于$N$个人,分组标签为:
\[T = \{(x_{nk})\},n=1,...,N,k=1,...,K\]为了减少运算量,对每个人产生一个reference embedding,reference embedding的生成方法就是对人的关节点的embedding值取平均。
\[\overline{h}_n = \frac{1}{K}\sum_k h_k(x_{nk})\]对于单个人来说,计算每个关节点预测的embedding和reference embedding的平方距离;对于两个不同的人来说,比较他们之间的reference embedding,随着它们之间距离的增加,惩罚将以指数方式降为0:
\[L_g(h,T) = \frac{1}{N}\sum_n\sum_k(\overline{h}_n-h_k(x_{nk}))^2 + \frac{1}{N^2}\sum_n\sum_{n'}\exp\{-\frac{1}{2\sigma^2}(\overline{h}_n-\overline{h}_{n'})^2\}\]总损失定义为:
\[L = 0.001L_g + 0.999L_d\]下图展示了网络产生的embedding的一个样例:

图片中的小目标在池化之后的分辨率会变得很低,这样将会影响精度,为了解决这个问题,在测试的时候使用多尺寸测试,然后将得到的热图相加取平均;为了跨尺寸组合标签,作者将像素位置的标签组成一个向量,然后计算向量之间的距离。


