Parameter-Efficient Fine-Tuning for Large Pretrained Models.
基于Transformer架构的大型语言模型(LLM)在自然语言处理、计算机视觉和音频等任务上取得突出的表现。然而这些模型通常具有大量参数(如GPT3.5具有1.75万亿参数),从头训练需要极大的算力和训练成本;因此为不同的下游任务训练不同的大型模型是不现实的。
将预训练好的大型模型在下游任务上进行微调已成为处理不同任务的通用范式。与直接使用冻结参数的预训练模型相比,在下游数据集上微调这些预训练模型会带来巨大的性能提升。但是随着模型越来越大,对模型进行全部参数的微调(full fine-tuning)变得非常昂贵,因为微调模型(调整模型的所有参数)与原始预训练模型的大小完全相同。
近年来研究者们提出了各种各样的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,即冻结预训练模型的大部分参数,仅微调少量或额外的模型参数(微调参数可以是模型的自有参数,也可以是额外引入的一些参数),以此达到与微调全部参数相当的性能。参数高效微调方法大大降低了计算和存储成本,甚至在某些情况下比全部参数的微调效果更好,可以更好地泛化到域外场景。
参数高效微调方法有以下几种形式:
- 增加额外参数(addition):在原始模型中引入额外的可训练参数,如Adapter, AdapterFusion, AdapterDrop, AdapterFormer, AdaMix, Ladder Side-Tuning
- 引入额外提示(prompt):在输入序列中引入可学习的prompt,如P-Tuning, Prompt Tuning, Prefix-Tuning, P-Tuning v2, VPT
- 选取部分参数(specification):指定原始模型中的部分参数可训练,如BitFit, Child-Tuning
- 重参数化(reparameterization):将微调过程重参数化为低维子空间的优化,如Diff Pruning, LoRA, AdaLoRA, QLoRA, GLoRA, LoRA+, LoRA-GA
- 混合方法:如MAM Adapter, UniPELT

扩展阅读:
- Parameter-efficient Fine-tuning of Large-scale Pre-trained Language Models
- Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
1. 增加额外参数的参数高效微调方法
这类方法在原始模型中引入额外的可训练参数,比如将小规模的神经网络模块插入到模型中,并且只微调这一小部分参数。由于引入了额外参数,这类方法的优化效率往往比其他微调范式更低,收敛时间更长,并且在中小型模型上表现不佳。
⚪ Adapter
Adapter在每个Transformer模块的两个位置(分别是多头注意力投影之后和全连接层之后)引入了带有少量参数的adapter模块。adapter模块由两个全连接层和一个非线性函数组成。

⚪ AdapterFusion
Adapter Fusion是一种融合多任务信息的Adapter变体,通过将学习过程分为两阶段来提升下游任务表现。
- 知识提取阶段:在不同任务下引入各自的Adapter模块,用于学习特定任务的信息。
- 知识组合阶段:将预训练模型与特定任务的Adapter参数固定,引入包含新参数的AdapterFusion来学习组合多个Adapter中的知识,以提高模型在目标任务中的表现。

⚪ AdapterDrop
AdapterDrop从较低的Transformer层中删除可变数量的Adapter,尽可能地减少模型的参数量,提高模型在反向传播(训练)和正向传播(推理)时的效率。

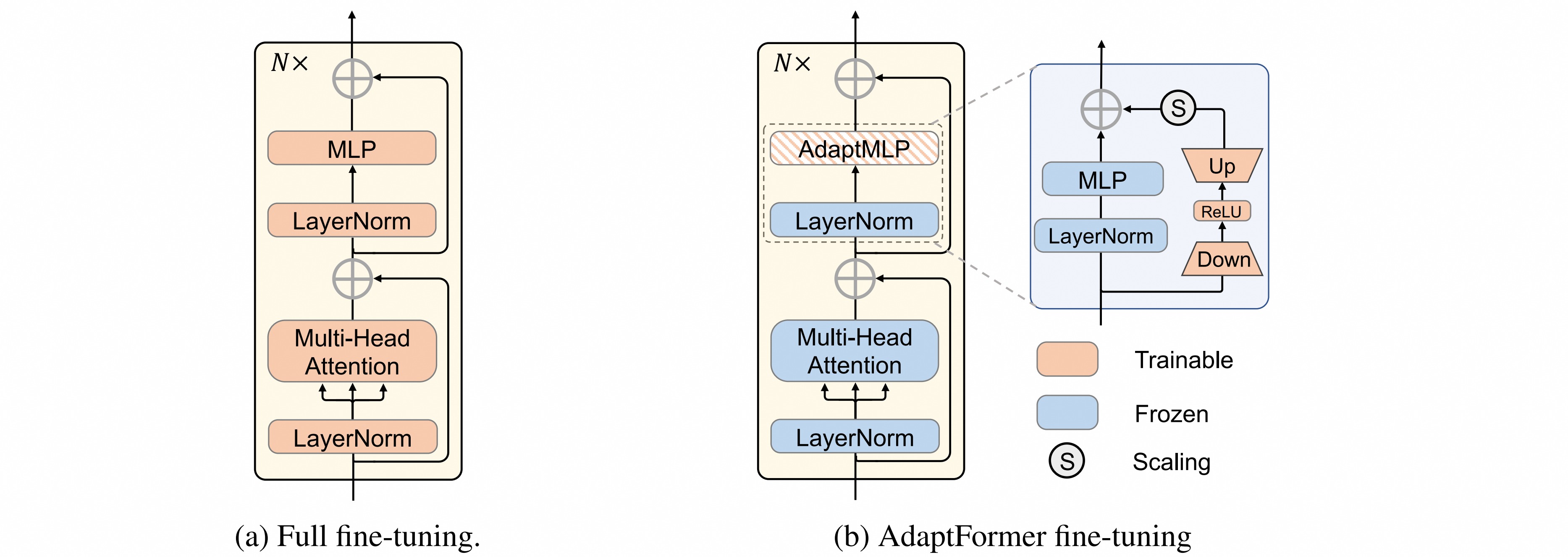
⚪ AdaptFormer
AdaptFormer用AdaptMLP代替了Transformer编码器中的MLP块。AdaptMLP由两个并行的子分支组成:左分支中的MLP层与原始网络相同;右分支是引入的task-specific轻量级模块,设计为轻量级编码器-解码器结构。
⚪ AdaMix
AdaMix将Adapter的两个 FFN 层(up 映射和 down 映射)设置为多专家模型,在训练时采用随机平均选择专家的方式,在推理阶段将所有专家平均参数。

⚪ Ladder Side-Tuning
Ladder Side-Tuning (LST)在原有大模型的基础上搭建了一个“旁支”,将大模型的部分层输出作为旁枝模型的输入。由于大模型仅提供输入,并不需要直接在大模型上执行反向传播,因此可以明显提升训练效率。

2. 引入额外提示的参数高效微调方法
这类方法把通过冻结预训练好的模型并添加一些可训练的prompt迁移到新任务上。把可学习参数插入到token空间既可以在线性投影之前预先添加到嵌入token中,也可以在线性投影之后添加到Q, K, V token中。
⚪ P-Tuning
- arXiv2103:GPT Understands, Too
P-Tuning方法把传统人工设计模版中的自然语言token替换成可微的virtual token,并用一个提示编码器来建模virtual token的相互依赖。

⚪ Prompt Tuning
Prompt Tuning方法给每个任务定义了自己的Prompt(可学习token),然后在输入层拼接到输入数据上。

⚪ Prefix-Tuning
Prefix-Tuning在每一层输入token之前构造一段任务相关的virtual tokens作为Prefix,在训练时只更新Prefix部分的参数,而语言模型中的其他部分参数固定。对于自回归结构,构造z = [PREFIX; x; y];对于编码器-解码器结构,构造z = [PREFIX; x; PREFIX’; y]。

⚪ P-Tuning v2
- arXiv2110:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
P-Tuning v2在Transformer网络的每一层都加入了可学习的Prompts tokens作为输入。

⚪ VPT
- arXiv2110:Visual Prompt Tuning
VPT在视觉Transformer的输入prompt空间引入少量的可训练prompt,并同时微调输出head。

3. 选取部分参数的参数高效微调方法
这类方法指定原始模型中的某些特定参数变得可训练,而其他参数则被冻结。这类方法不会在模型中引入任何新参数,也不改变模型的结构,而是直接指定要优化的部分参数。尽管方法简单,但是通常效果比较好。
⚪ BitFit (Bias-terms Fine-tuning)
- arXiv2106:BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
BitFit训练时只更新网络中的bias参数。Transformer模型涉及到的bias参数有:attention模块中计算query,key,value与合并多个attention结果时涉及到的bias、MLP层和LayerNorm层的bias。

⚪ Child-Tuning
ChildTuning方法每次从预训练模型中选择一个子网络进行优化;子网络的选择又分为两种方式:ChildTuning-D和ChildTuning-F。

ChildTuning-D是任务相关的选择方式,通过计算每个参数的Fisher信息作为该参数的重要性,选择最重要的top-$p$个参数,在模型更新过程中只优化这些参数。
ChildTuning-F是任务无关的选择方式。在每步更新时随机构建一个与梯度同尺寸的0/1矩阵$M$,其中设置$1$的比例为$p$,然后将梯度修改为\(g \leftarrow \frac{g \otimes M}{p}\)。
4. 重参数化的参数高效微调方法
通常尽管预训练模型的参数量很大,但每个下游任务对应的本征维度(Intrinsic Dimension)并不大,理论上可以微调非常小的参数量,就能在下游任务取得不错的效果。
重参数化方法把预训练模型的参数微调过程重参数化为为一个低维子空间的优化过程,可以仅仅通过微调子空间内的参数就达到令人满意的性能。对于预训练参数矩阵$W_0$,不直接微调$W_0$,而是微调一个子空间中的增量$\Delta W$:
\[W \leftarrow W_0 + \Delta W\]⚪ Diff Pruning
Diff Pruning把模型微调时的参数更新量建模为与下游任务相关的差异向量$\delta$,并通过在损失中引入$\delta$的L0-norm惩罚来约束其稀疏性。
\[W \leftarrow W_0 + \delta\]⚪ LoRA (Low-Rank Adaptation)
LoRA通过低秩分解来模拟参数的改变量。在原始矩阵乘法$Wx$旁边增加一个新的通路$BAx$,第一个矩阵$A$负责降维,第二个矩阵$B$负责升维,中间层维度为$r$,用来模拟微调后矩阵的本征秩。
\[W \leftarrow W_0 + BA\]
⚪ AdaLoRA
AdaLoRA根据重要性评分动态分配参数预算给权重矩阵:
- 对重要性评分高的增量矩阵分配更高的秩;
- 增量更新以奇异值分解的形式进行,并根据重要性指标裁剪掉不重要的奇异值;
- 在训练损失中添加了额外的惩罚项,以规范奇异矩阵$P$和$Q$的正交性。
⚪ QLoRA
QLoRA将预训练模型量化为4 bit后添加可学习的低秩权重。为实现高保真4 bit微调,QLoRA引入了以下技术:
- 设计了一种低精度存储数据类型4bit NormalFloat(NF4),该数据类型能产生更好的4 bit正态分布数据;
- 采用双量化,即对第一次量化后的常量再进行一次量化;
- 分页优化器:使用NVIDIA统一内存特性,该特性可以在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页传输,以实现无错误的GPU处理。

⚪ GLoRA
GLoRA同时考虑权重空间和特征空间中的可调维度,并通过进化搜索来学习网络每层的微调参数。可调参数包括:$A$用于缩放权重参数,$B$用于缩放输入和偏移权重参数,$C$用于补充层级可训练prompt(与prompt tuning相似),$D,E$用于缩放和偏移偏置参数。
\[\begin{aligned} f(x) &= (W_0 + \underbrace{W_0A + B}_{\text{weight space}} )x + \underbrace{CW_0+Db_0+E}_{\text{feature space}}+b_0 \\ \end{aligned}\]
⚪ LoRA+
LoRA+指出设置权重$B$的学习率应该要大于权重$A$的学习率。

⚪ LoRA-GA
LoRA-GA采样一批样本计算初始梯度\(\frac{\partial \mathcal{L}}{\partial W}\),并进行奇异值分解\(\frac{\partial \mathcal{L}}{\partial W}=U\Sigma V\);取$U$的前$r$列初始化 $B$,取$V$的第$r+1\sim 2r$行初始化$A$;从而使得在初始阶段参数高效微调接近全量微调。

5. 混合方法
一些参数高效的微调方法通过混合上述不同类型的微调方法,进一步提高下游任务中微调的性能。
⚪ MAM Adapter
作者分析了当下最先进的参数高效迁移学习方法(Adapter, Prefix Tuning和LoRA)的设计,并提出了一种在它们之间建立联系的统一框架MAM Adapter。


MAM Adapter是用于FFN的并行Adapter和soft prompt的组合:
- 并行放置的Adapter优于串行放置的Adapter,并且与FFN并行放置的Adapter优于与MHA并行放置的Adapter。
- soft prompt可以通过仅更改 $0.1\%$ 的参数来有效地修改注意力。
⚪ UniPELT
UniPELT是LoRA、Prefix Tuning和Adapter的门控组合。对于每个模块,通过线性层实现门控,通过$G_P$控制Prefix-tuning方法的开关,$G_L$控制LoRA方法的开关,$G_A$控制Adapter方法的开关。



