视觉提示微调.
- paper:Visual Prompt Tuning
把大模型应用于下游任务时,通常的策略是进行端到端的全面微调(full fine-tuning),然而这种策略需要为每个任务存储部署单独的主干参数,代价比较高。
一种简单的方法是仅微调参数的子集,如下图(a):如分类器头部或者偏差项。之前的研究还会试着向主干添加额外的残差结构或者adapter。然而这些策略会在准确度上略差于执行完全微调。
本文介绍Visual Prompt Tuning(VPT)作为一种有效的用于大规模Transformer的视觉微调。它只需要在输入空间引入少量(不到$1\%$的模型参数)的可训练参数,同时冻结backbone。实践中,这些附加参数只是预先加入到Transformer每层输入序列中,并在微调时和线性头一起学习。
在ViT预训练微调的24个跨域的下游任务中,VPT优于其他迁移学习的baseline,有20个超过了完全微调,同时保持了为每个单独任务储存较少参数的优势。

对于一个$N$层的ViT,输入的图片被分为$m$个patch $I_j,j=1,…,m$。每一个patch和位置编码embedding连接后被嵌入到$d$维潜在空间。给定一个预先训练好的Transformer,在Embed层后的输入空间引入一组$d$维的连续prompt。在微调过程中,只有prompt会被更新,主干将会冻结。

根据加入prompt的层数量分为浅VPT和深VPT。
VPT-Shallow是指Prompt仅插入第一层。每一个prompt token都是一个可学习的$d$维参数。
\[\begin{aligned} \left[\mathbf{x}_{1},\mathbf{Z}_{1},\mathbf{E}_{1}\right]&=L_{1}\left(\left[\mathbf{x}_{0},\mathbf{P},\mathbf{E}_{0}\right]\right)\\ \left[\mathbf{x}_{i},\mathbf{Z}_{i},\mathbf{E}_{i}\right]&=L_{i}\left(\left[\mathbf{x}_{i-1},\mathbf{Z}_{i-1},\mathbf{E}_{i-1}\right]\right)\\ \mathbf{y}&=\text{Head}(\mathbf{x}_{N}) \end{aligned}\]VPT-Deep是指Prompt被插入每一层的输入序列。
\[\begin{aligned} \left[\mathbf{x}_{i},\_\_,\mathbf{E}_{i}\right]&=L_{i}\left(\left[\mathbf{x}_{i-1},\mathbf{P}_{i-1},\mathbf{E}_{i-1}\right]\right)\\ \mathbf{y}&=\text{Head}(\mathbf{x}_{N}) \end{aligned}\]VPT对于多个下游任务都是有帮助的,只需要为每个任务存储学习到的prompt和分类头,重新使用预训练的Transformer,从而显著降低存储成本。
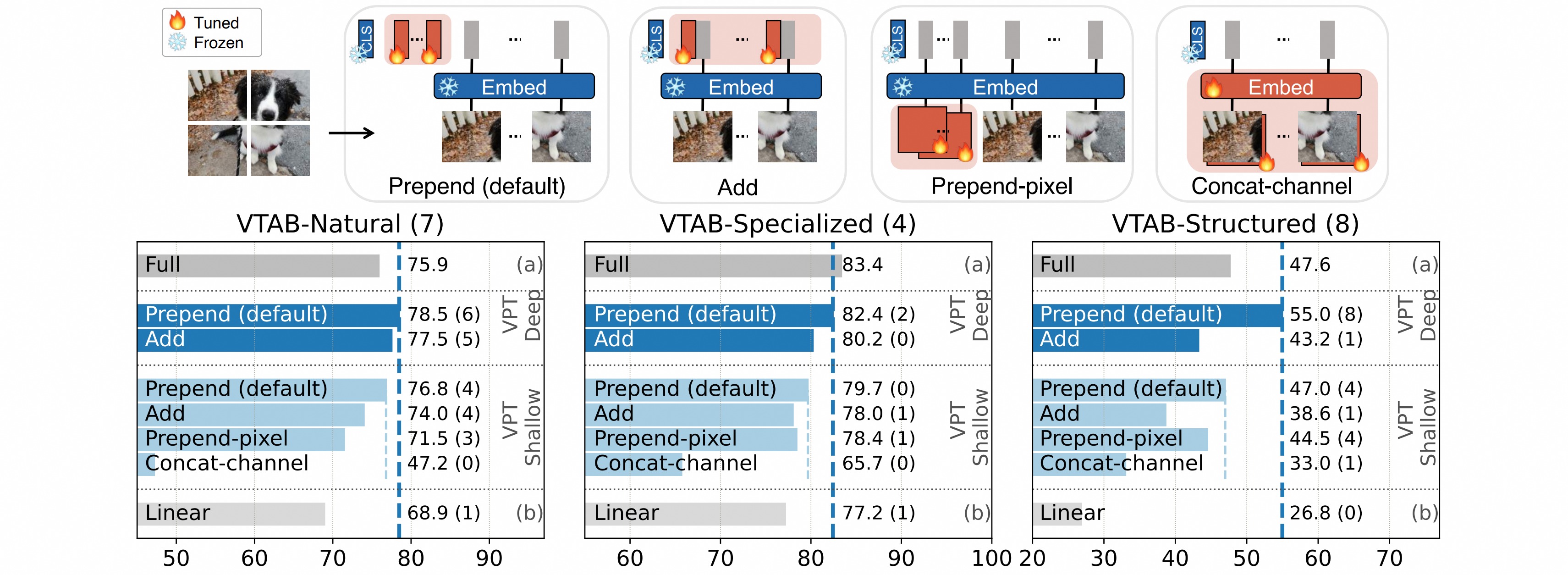
作者做了关于prompt位置的消融实验,本文提出的prepend与直接在embedding上添加对比效果更好。除此之外,作为前置像素或者concat通道的效果也都在下降。
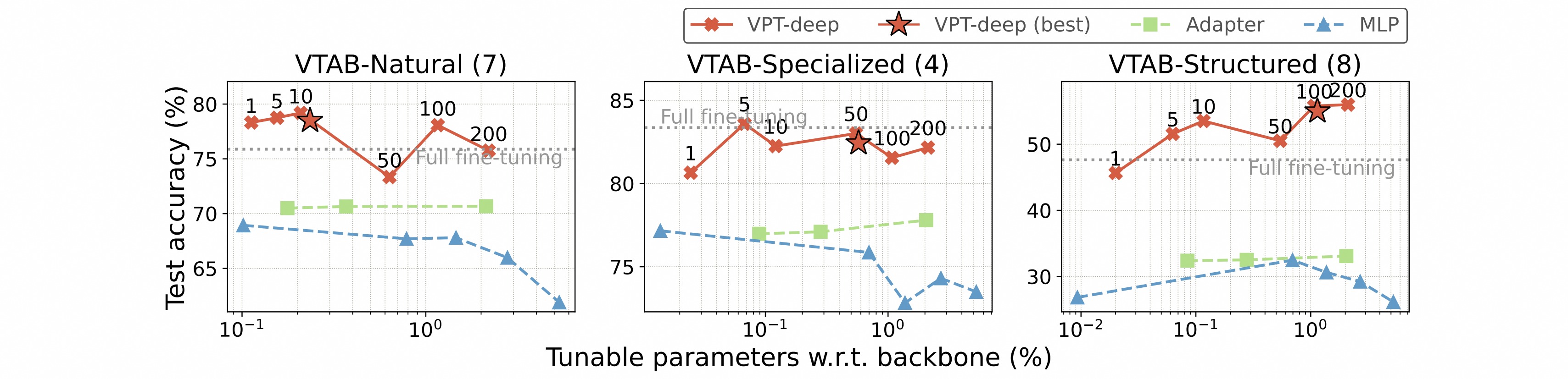
作者做了关于prompt长度的消融实验,最佳提示长度因任务而异,即使只有一个prompt,深VPT的效果仍显著优于另外两种方法。
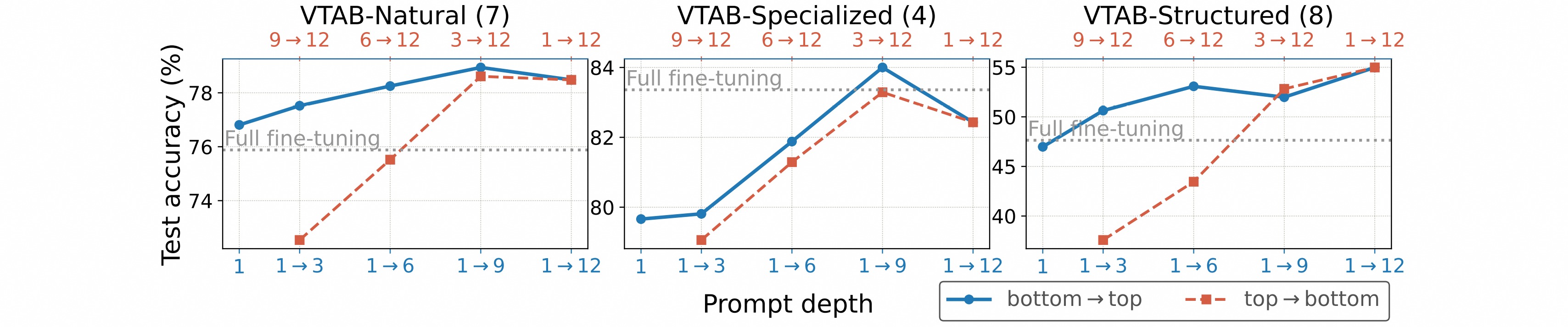
作者做了关于prompt深度的消融实验,从上到下插入prompt,准确性会显著下降。这表明前面Transformer层的prompt比后面层更加重要。
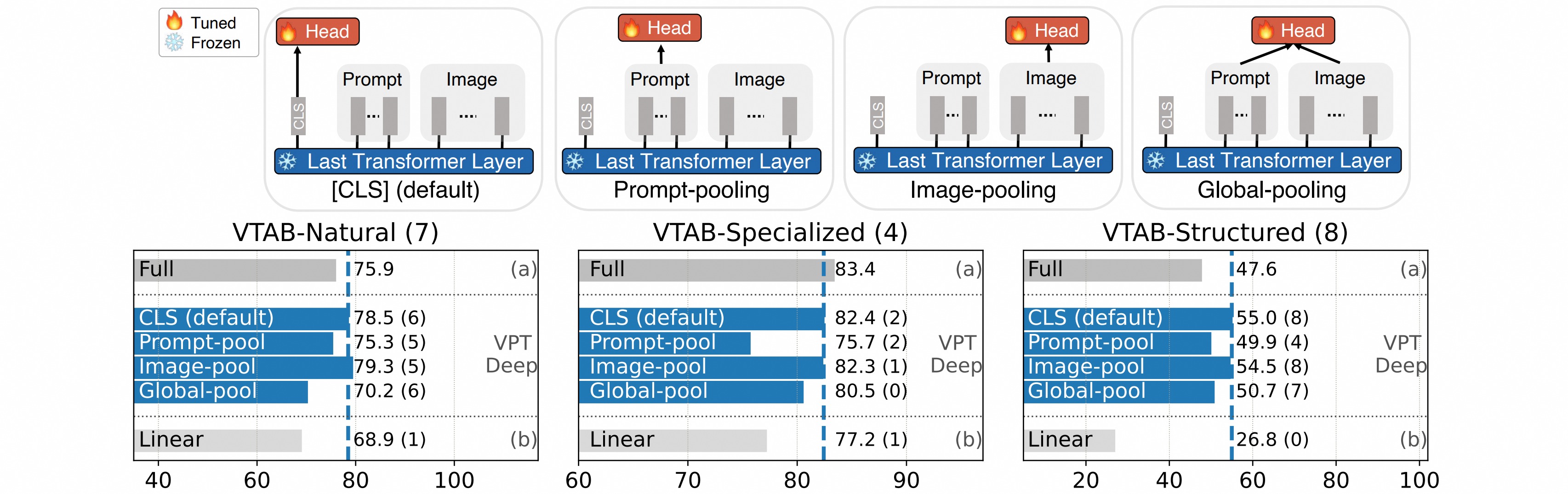
作者做了关于输出head位置的消融实验,结果表明使用CLS token或者图像patch的输出特征进行预测效果最好。