AdaptFormer:微调视觉Transformer用于可扩展视觉识别.
预训练后的ViT广泛用于视觉领域,每个模型都需要独立完整的微调才能适应不同的任务,但巨大的计算量和存储负担限制了可迁移性。作者提出了Transformer自适应方法,即AdaptFormer,只需要训练很少的参数,其他大部分固定参数是跨任务共享的。
- AdaptFormer简单高效,引入了轻量级模块,只向ViT添加了不到$2\%$的额外参数,能够在不更新其原始预训练参数的情况下增加ViT的可迁移性。
- AdaptFormer即插即用,可扩展到多种视觉任务,在参数放大时具有优异的鲁棒性。
- AdaptFormer大大改善了目标域中ViTs的性能表现,显著优于现有的微调方法。
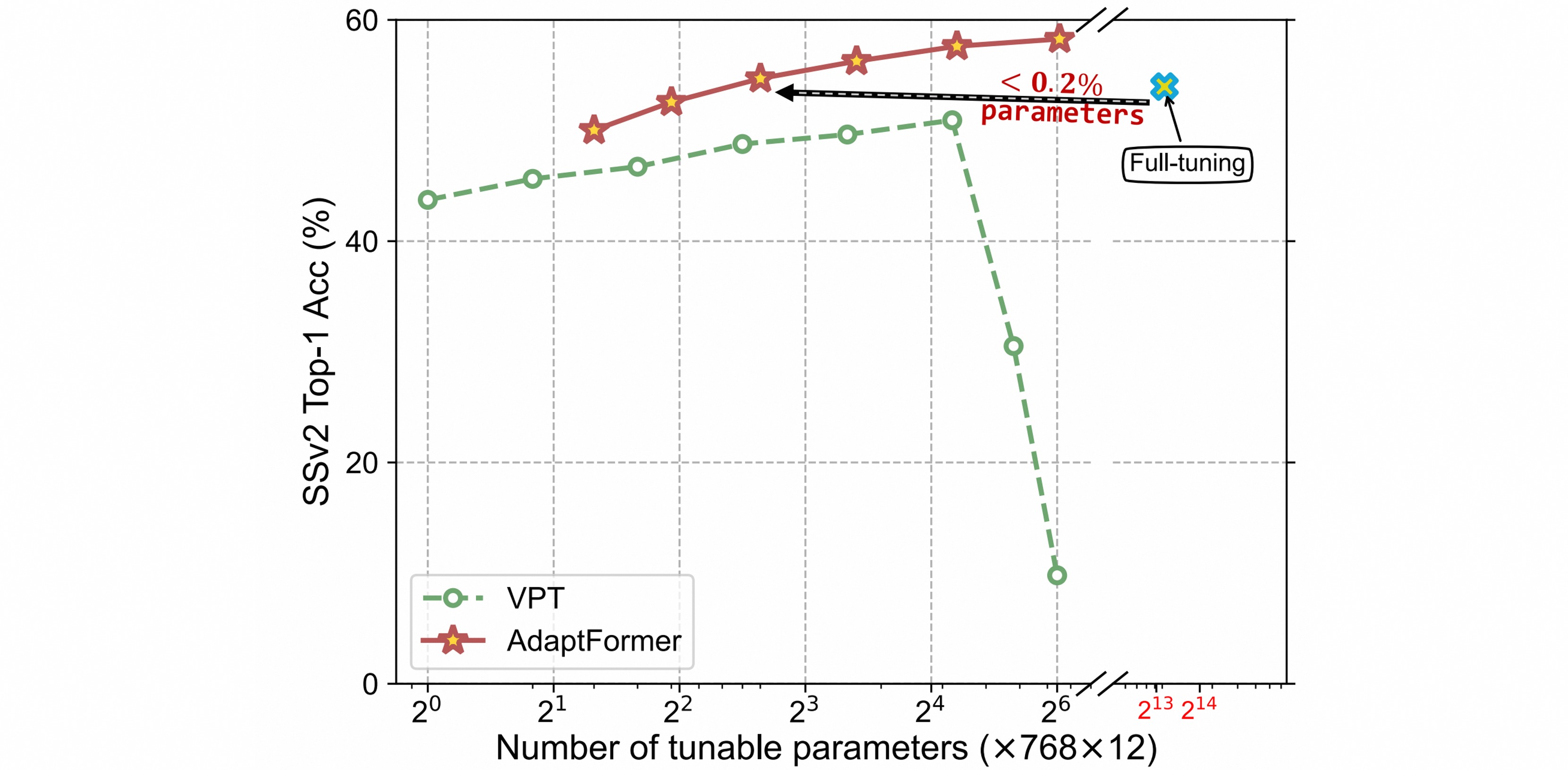
AdaptFormer与VPT在SSv2数据集上的Parameter-Accuracy trade-off,同时与全量微调相比,AdaptFormer用更少的参数达到更高的性能。
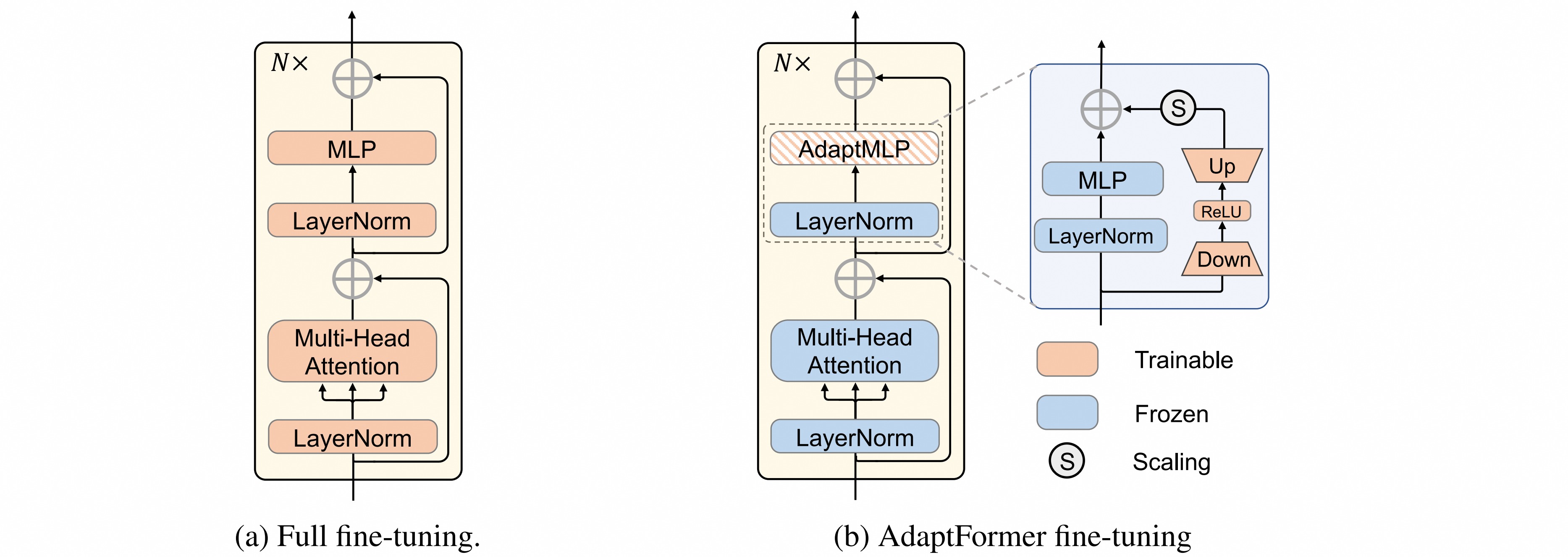
作者借鉴冻结backbone和引入可调参数的思想,将参数加到Transformer的MLP层。AdaptFormer用AdaptMLP代替了Transformer编码器中的MLP块。AdaptMLP由两个并行的子分支组成:
- 左分支中的MLP层与原始网络相同,也叫冻结分支;
- 右分支是引入的task-specific轻量级模块,设计为bottleneck结构,轻量级编码器-解码器结构旨在通过降低中间维度来限制新引入的参数量。bottleneck结构由两个全连接层,一个非线性激活函数和一个缩放因子组成,与原始ViT模型的前馈网络 (FFN) 并行设置。
对于多头自注意力层(MHSA),公式计算如下:
\[x_l^\prime=A t t e n t i o n(Q,K,V)=S o f t m a x(\frac{Q K^{T}}{\sqrt{d}})V\]对于AdaptMLP层,$W_{down}$是下投影层参数,$W_{up}$是上投影层参数,$\hat{d}$是bottleneck中间维度,公式计算如下:
\[\tilde{x}_l = ReLU(LN(x_l^\prime)\cdot W_{down}) \cdot W_{up}\]最后通过残差连接融合特征:
\[x_l = MLP(LN(x_l^\prime)) + s\cdot \tilde{x}_l + x_l^\prime\]在微调阶段,原始模型部件(图中的蓝色块)从预训练的checkpoint加载权重并保持不变,避免下游任务之间的交互。新添加的参数(橙色块)在特定数据域上随任务特定损失进行更新。在微调后,保持共享参数固定,并额外加载前一阶段微调的额外参数的权重。 AdaptFormer仅通过微调少量额外参数就获得了强大的迁移学习能力,避免了任务间的干扰。

作者基于ViT模型进行实验,直接加载原始模型预训练的权重,在微调过程中保持预训练权重frozen。对于新添加的模块,向下投影层Down用Kaiming Normal初始化,其余的部分用零初始化(以零初始化初始新添加的参数,使得新函数近似于原始函数。如果初始化偏离同一函数太远,则模型不稳定,无法训练)。
AdaptFormer始终优于linear probing和Visual Prompt tuning(VPT)方法,在视频领域优势更加显著。相比全量调整,参数量只有不到$2\%$,但准确率高$5\%$。

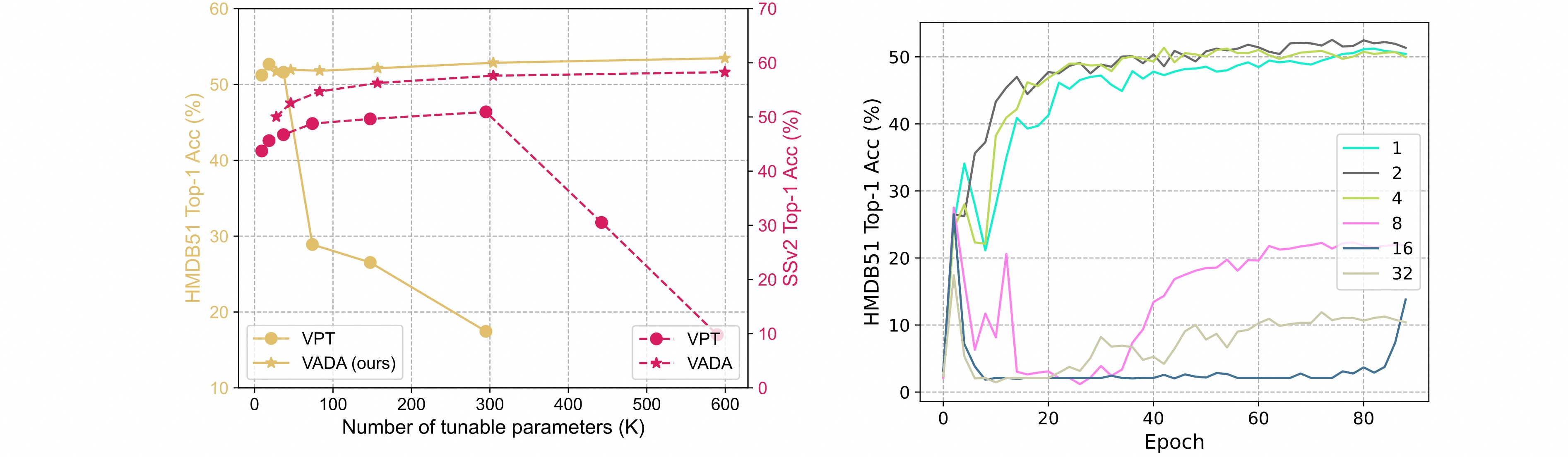
在参数量的比较上,相比于VPT方法,本文的方法在两个数据集上都能达到更高的性能。当参数数量超过任务特定值时,VPT的准确性会显著下降,而AdaptFormer对不断增加的参数具有鲁棒性。逐渐增加VPT的token数量,token≤4时是稳定的,≥8训练会崩溃;而中间维度控制AdaptFormer引入的参数的数量,可以看出Adaptformer随着参数量的增加精度保持稳定。
一系列消融实验:
- 中间维度$\hat{d}$:$\hat{d}$越小,引入的参数越少。在SSv2数据集上,当中间维度增加到64时,准确度持续提高,当中间维度大约为64时,达到饱和点。当中间维度甚至降低到$1$时,AdaptFormer也可以获得不错的性能。
- 添加层数:AdaptFormer的性能与添加的层数呈正相关。当引入相同数量的层时,并行效果比串行效果好。原因是因为并行设计使用一个独立的分支来保持原始特征,并通过元素的缩放和来聚合更新的上下文;同时串行设计相当于添加更多的层,这可能会导致优化困难。
- 缩放因子$s$:$s$是用于平衡task-agnostic特性(由原始冻结分支生成)和task-specific特性(由可调bottleneck分支生成)。结果表明$s$在$0.1$左右达到最佳性能。
- 帧数:嵌入patch token的数量随着视频帧的数量线性增加。作者使用不同数量的帧进行了实验,即$2,4,8$,观察到增加帧数对所有这三种微调方法都是有益的。AdaptFormer始终优于线性方式和VPT方法。

与前两个方法相比,全量微调策略在特征方面表现良好,但需要消耗大量的计算资源。AdaptFormer有助于以更少的可学习参数生成更多的可分离表示。



