AdapterFusion:迁移学习中的非破坏性任务组合.
为了整合来自多个任务的知识,传统的两个方法是按一定顺序微调(Sequential fine-tuning)或者多任务学习(multi-task learning)。前者的一大问题是需要先验知识来确定顺序,且模型容易遗忘之前任务学到的知识;后者的问题是不同的任务会互相影响,也难以平衡数据集大小差距很大的任务。
在之前的工作中,Adapter不用更新预训练模型的参数,而是插入比较少的新的参数就可以很好地学会一个任务。此时,Adapter的参数某种程度上就表达了解决这个任务需要的知识。
作者受此启发,如果想要把来自多个任务的知识结合起来,是否可以考虑把多个任务的Adapter的参数结合起来?基于此,作者提出了 AdapterFusion,这是一种新的两阶段学习算法,可以利用来自多个任务的知识。
Adapter Fusion是一种融合多任务信息的Adapter的变体,在 Adapter 的基础上进行优化,通过将学习过程分为两阶段来提升下游任务表现。
- 知识提取阶段:在不同任务下引入各自的Adapter模块,用于学习特定任务的信息。
- 知识组合阶段:将预训练模型与特定任务的Adapter参数固定,引入包含新参数的AdapterFusion来学习组合多个Adapter中的知识,以提高模型在目标任务中的表现。

对于第一阶段,有两种训练方式,分别如下:
- Single-Task Adapters(ST-A):对于N个任务,模型都分别独立进行优化,各个任务之间互不干扰,互不影响。
- Multi-Task Adapters(MT-A):N个任务通过多任务学习的方式,进行联合优化。
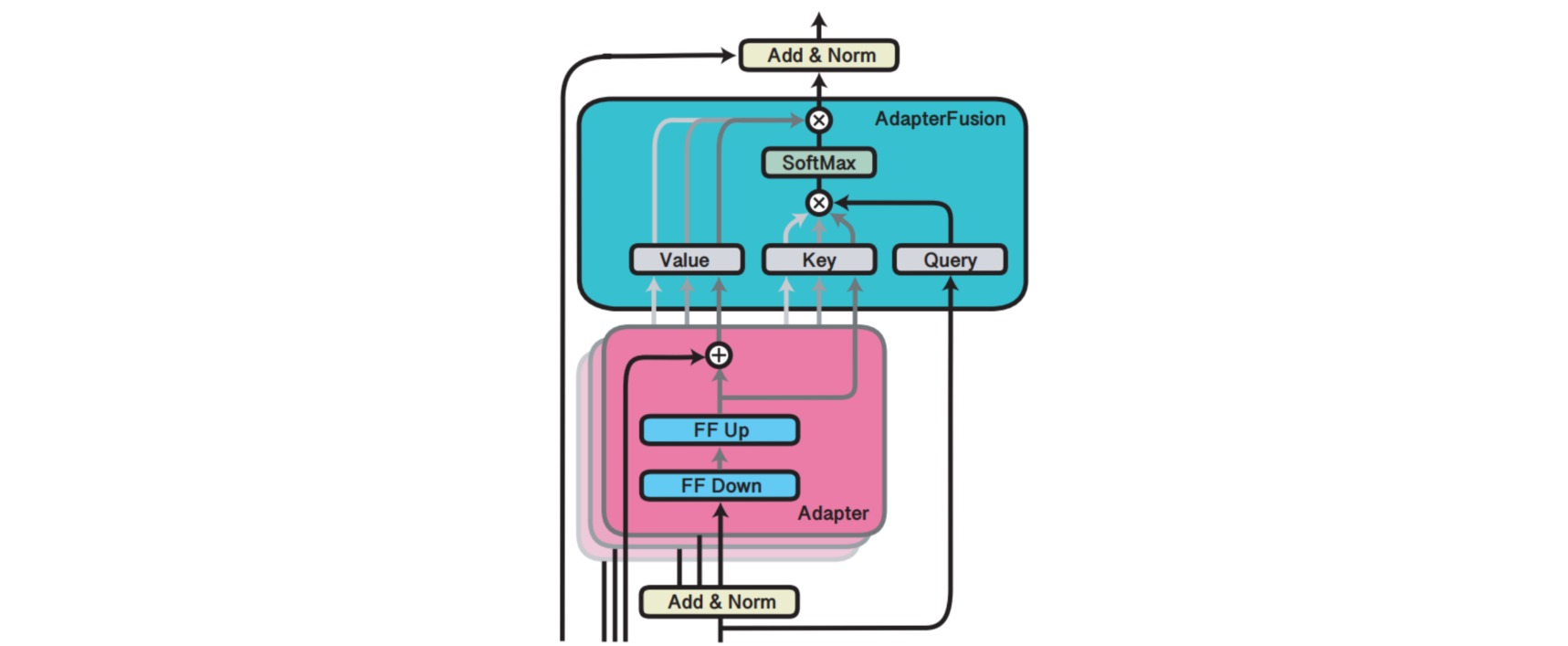
对于第二阶段,为了避免通过引入特定任务参数而带来的灾难性遗忘问题,AdapterFusion提出了一个共享多任务信息的结构。针对特定任务m,AdapterFusion联合了第一阶段训练得到的N个Adapter信息。固定语言模型的参数跟N个Adapter的参数,新引入AdapterFusion的参数,目标函数也是学习针对特定任务m的AdapterFusion的参数。
AdapterFusion具体结构是一个自注意力模块,它的参数包括query, key, value的矩阵参数,在transformer的每一层都存在,query是transformer模块全连接层的输出结果,key跟value则是N个任务的adapter的输出。通过AdapterFusion,模型可以为不同的任务对应的adapter分配不同的权重,聚合N个任务的信息,从而为特定任务输出更合适的结果。
通过对全量微调、Adapter Tuning、AdapterFusion这三种方法在各个数据集上进行对比实验可以看出,AdapterFusion在大多数情况下性能优于全模型微调和Adapter Tuning,特别在MRPC与RTE数据集中,性能显著优于另外两种方法。
同时还可以看到第一阶段采用ST-A+第二阶段AdapterFusion是最有效的方法,在多个数据集上的平均效果达到了最佳。而第一阶段采用MT-A+第二阶段AdapterFusion没有取得最佳的效果,在于第一阶段其实已经联合了多个任务的信息了,所以AdapterFusion的作用没有那么明显,同时MT-A这种多任务联合训练的方式需要投入较多的成本,并不算一种高效的参数更新方式。另外,ST-A的方法在多个任务上都有提升,但是MT-A的方法则不然,这也表明了MT-A虽然可以学习到一个通用的表征,但是由于不同任务的差异性,很难保证在所有任务上都取得最优的效果。

总之,通过将学习过程分为知识提取和知识组合两部分,解决了灾难性遗忘、任务间干扰和训练不稳定的问题。但是AdapterFusion模块的添加也导致模型整体参数量的增加,降低了模型推理时的性能。


