参数高效迁移学习的统一视角.
近年来提出了多种参数高效的迁移学习方法,这些方法仅微调少量(额外)参数即可获得强大的性能。虽然有效,但人们对为什么有效的关键要素以及各种高效微调方法之间的联系知之甚少。
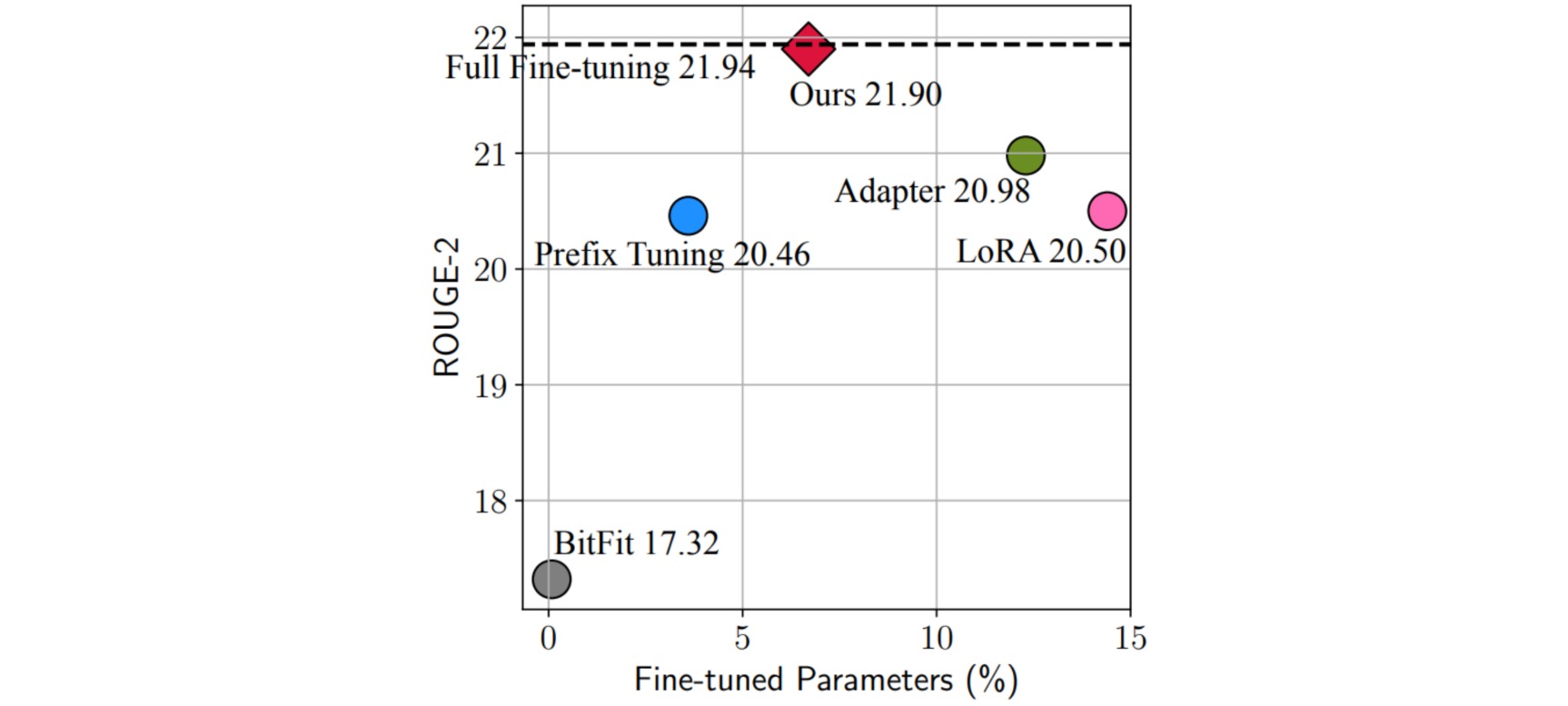
下图展示了不同的微调方法在Xsum数据集上做英文文本摘要任务的效果(ROUGE-2是该任务的评价指标,越大越好)以及高效微调方法参数量相对于全参数微调参数量的百分比。从图中发现Adapter,Prefix Tuning和LoRA都是性能比较好的方法。
作者分解了当下最先进的参数高效迁移学习方法(Adapter, Prefix Tuning和LoRA)的设计,并提出了一种在它们之间建立联系的统一框架MAM Adapter。具体来说,将它们重新构建为对预训练模型中特定隐状态的修改,并定义一组设计维度,不同的方法对这些维度做相应的变化。

作者分析了不同微调方法的内部结构和结构插入形式的相似之处。具体分析点包括新增可训练参数结构形式(functional form)、结构插入形式(Insertion form)、新增结构修改的具体位置(modified representation)、新增结构组合函数(composition function)。


作者得出如下结论:
- 并行放置的Adapter优于顺序放置的Adapter,并且与 FFN 并行放置的Adapter优于多头注意力(MHA)并行放置的Adapter。
- soft prompt可以通过仅更改 $0.1\%$ 的参数来有效地修改注意力。

通过上述分析,作者提出了mix-and-match(MAM),MAM Adapter是用 FFN 层的并行Adapter和soft prompt的组合。通过最终的实验结果,可以看到 MAM Adapter 在仅用了$6.7\%$参数量(相比全量微调)的情况下,在Xsum和MT这两个任务上达到了和全量微调相近的效果。



