UniPELT:参数高效的语言模型微调的统一框架.
近年来,涌现出了许多针对语言模型的参数高效微调(PELT)方法,在模型训练参数极大减少的情况下,模型效果与全量微调相当。但是不同的PELT方法在同一个任务上表现差异可能都非常大,这让针对特定任务选择合适的方法非常繁琐。基于此,作者提出了UniPELT方法,将不同的PELT方法作为子模块,并通过门控机制学习激活最适合当前数据或任务的方法。
UniPELT是LoRA、Prefix Tuning和Adapter的门控组合。LoRA用于$W_Q$和$W_V$注意力矩阵,Prefix Tuning应用于Transformer层的key和value,Adapter应用于Transformer块的feed-forward子层之后。
对于每个模块,通过线性层实现门控,通过$G_P$参数控制Prefix-tuning方法的开关,$G_L$控制LoRA方法的开关,$G_A$控制Adapter方法的开关。可训练参数包括 LoRA 矩阵$W_{down},W_{up}$、Prefix-tuning参数$P_K,P_V$、Adapter参数和门控函数权重。即图中蓝颜色的参数为可学习的参数。

UniPELT 仅用 100 个样本就在低数据场景中展示了相对于LoRA、Prefix Tuning和Adapter方法的显著改进。在更多数据的场景中,UniPELT 的性能与这些方法相当或更好。
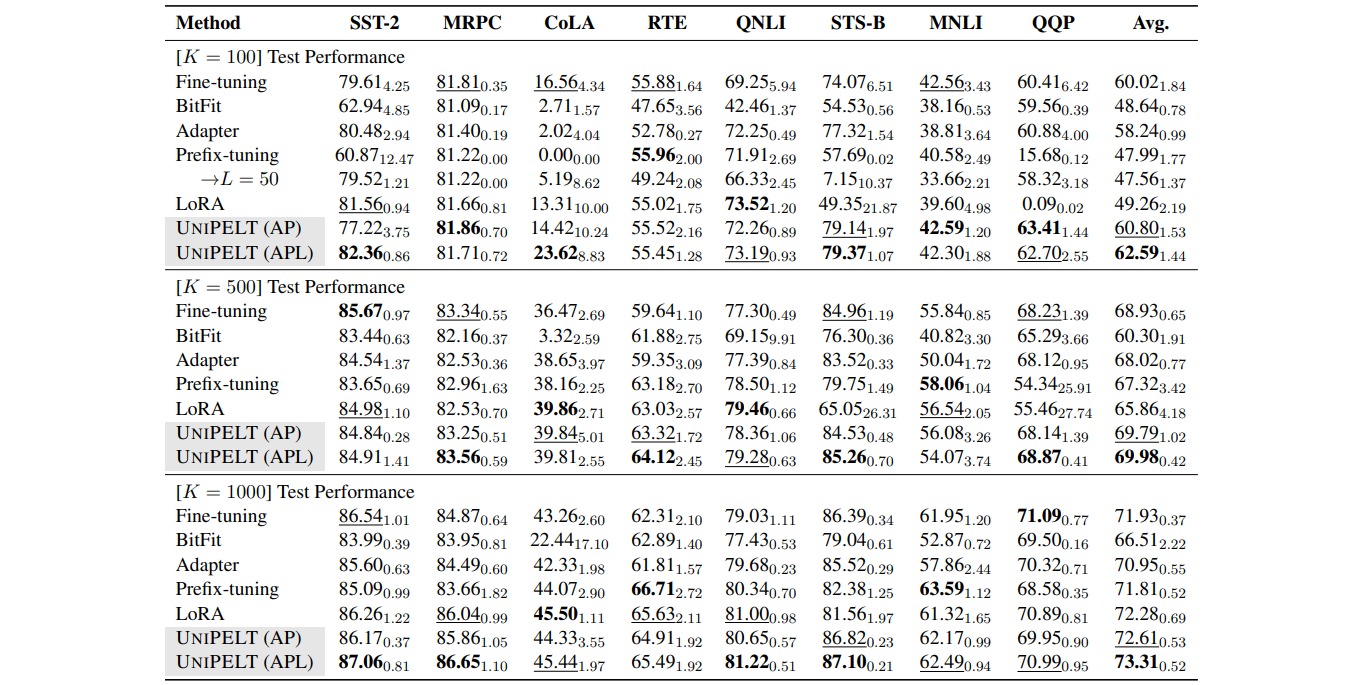
实验还对不同 PELT 方法训练时间和推理时间进行了分析。
- 从训练速度来看,UniPELT比之前微调的方法多一些,但是还在能接受的范围,
- 从推理时间来看,BitFit方法增加的最少,UniPELT方法时间增加了$27\%$。
- 从训练参数量来看,LoRA,BitFit,Prefix-tuning都比较小,UniPELT参数量相对会多一些。
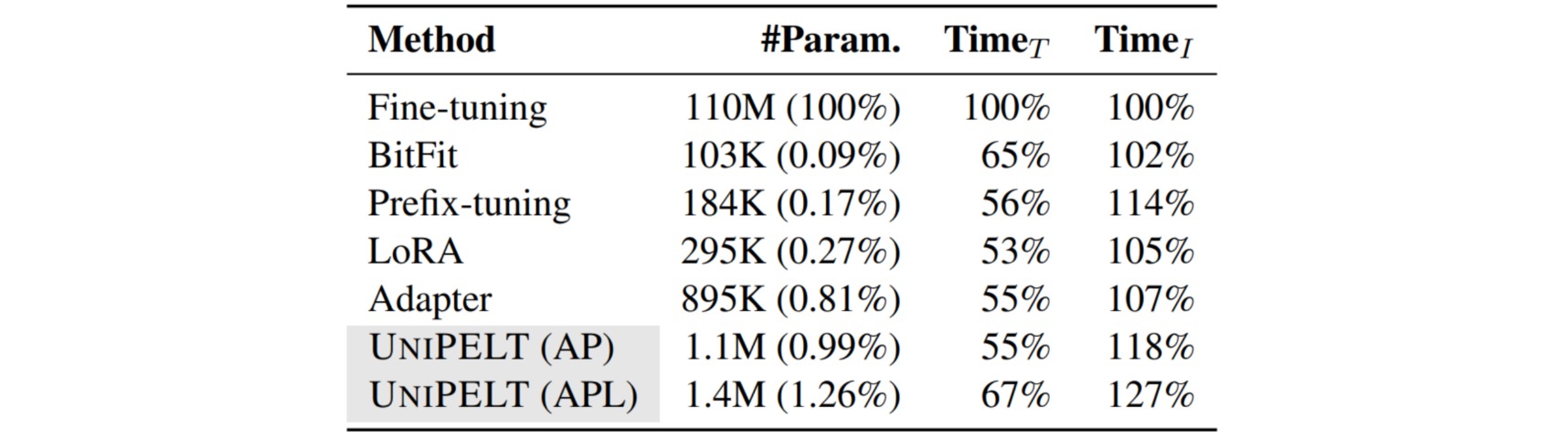
UniPELT方法始终优于常规的全量微调以及它在不同设置下包含的子模块,通常超过在每个任务中单独使用每个子模块的最佳性能的上限;并且通过研究结果表明,多种 UniPELT 方法的混合可能对模型有效性和鲁棒性都有好处。


