用于参数高效微调的自适应预算分配.
在NLP领域,对于下游任务进行大型预训练语言模型的微调已经成为一种重要的做法。一般会采用对原有的预训练模型进行全量微调的方法来适配下游任务,但这种方法存在两个问题。
- 训练阶段。对于预训练模型进行微调的时候,为了更新权重参数,需要大量的显存来存储参数的梯度和优化器信息,在当今预训练模型的参数变得越来越大的情况下,针对下游任务微调门槛变得越来越高。
- 推理阶段。由于训练是对于模型参数进行全量的更新,所以对于多个下游任务需要为每个任务维护一个独立的大型模型,这样就导致在实际应用的时候浪费了不必要的存储空间。
为了解决这些问题,研究者提出了两个主要研究方向,以减少微调参数的数量,同时保持甚至提高预训练语言模型的性能。
- 方向一:添加小型网络模块:将小型网络模块添加到预训练模型中,保持基础模型保持不变的情况下仅针对每个任务微调这些模块,可以用于所有任务。这样只需引入和更新少量任务特定的参数,就可以适配下游的任务,大大提高了预训练模型的实用性。这类方法虽然大大减少了内存消耗,但是存在一些问题,比如引入了推理延时、比较难收敛。
- 方向二:下游任务增量更新:对预训练权重的增量更新进行建模,而无需修改模型架构,即$W=W_0+\Delta W$。此类方法可以达到与完全微调几乎相当的性能,但是也存在一些问题,比如训练过程中需要存储完整的参数变化矩阵,相比于全量微调并没有降低计算成本。
本文作者提出了AdaLoRA,它根据权重矩阵的重要性得分,在权重矩阵之间自适应地分配参数预算。
- 不能预先指定增量矩阵$\Delta W$的秩,因为权重矩阵的重要性在不同模块和层之间存在显著差异。
- 需要找到更加重要的矩阵,分配更多的参数,裁剪不重要的矩阵。找到重要的矩阵,可以提升模型效果;而裁剪不重要的矩阵,可以降低参数计算量,降低模型效果差的风险。
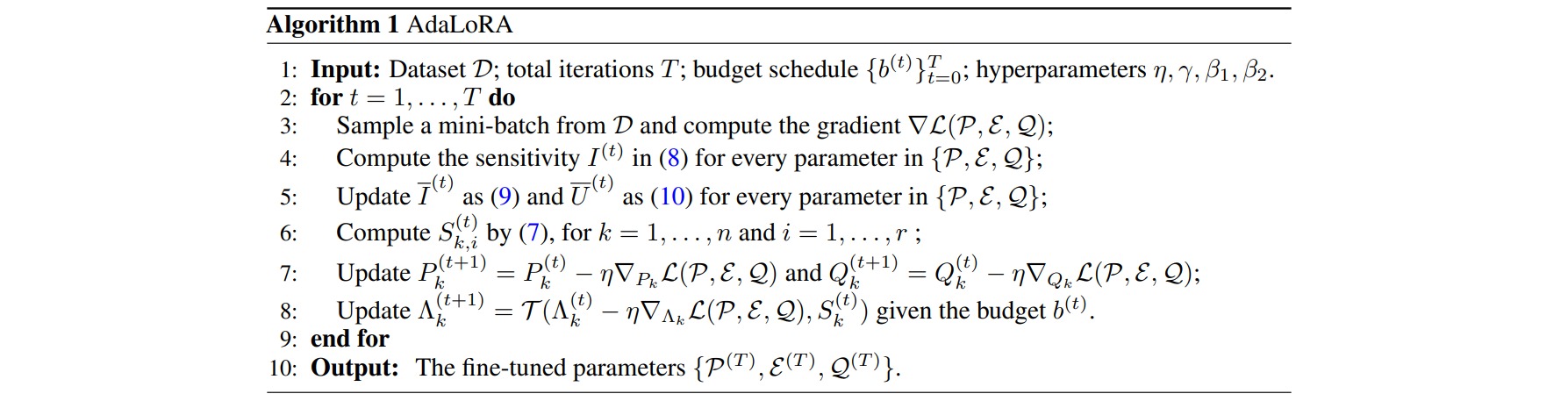
AdaLoRA是对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵。具体做法如下:
- 调整增量矩分配。AdaLoRA将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。
- 以奇异值分解的形式对增量更新进行参数化,并根据重要性指标裁剪掉不重要的奇异值,同时保留奇异向量。由于对一个大矩阵进行精确奇异值分解的计算消耗非常大,这种方法通过减少它们的参数预算来加速计算,同时保留未来恢复的可能性并稳定训练。
- 在训练损失中添加了额外的惩罚项,以规范奇异矩阵$P$和$Q$的正交性,从而避免SVD的大量计算并稳定训练。
通过实验证明,AdaLoRA 实现了在所有预算、所有数据集上与现有方法相比性能更好或相当的水平。 例如,当参数预算为 $0.3M$ 时,AdaLoRA 在RTE数据集上比表现最佳的基线高 $1.8\%$。



