视觉Transformer真的需要显式位置编码吗?
self-attention结构的特点是可以建模一整个输入序列的信息,并能根据图片的内容来动态调整感受野,但是self-attention具有排列不变性 (permutation-invariant),即无法建模输入序列的顺序信息,输入这个序列顺序的调整是不会影响输出结果的。Transformer引入了位置编码机制。位置编码在图像识别任务中的作用是保持像素间的空间位置关系,建模像素点前后左右的位置信息。位置编码可以设置为可学习的,也可以设置为不可学习的正弦函数。
位置编码的缺点是长度往往是固定的。比如输入图片的大小是224×224的,分成大小为16×16的patch,那么序列长度是196。所以训练时把位置编码的长度也设置为196。但是后续进行迁移学习时输入图片是384×384的,分成大小为16×16的patch,那么序列长度是576。此时长度196的位置编码就不够了。如果直接去掉位置编码会严重地影响分类性能,因为输入序列的位置信息丢失了。
本文提出了一种新的位置编码策略CPVT,既能解决传统位置编码不可变长度的局限性,又能起到位置编码的作用。CPVT能自动生成一种包含位置信息的编码PEG,编码过程是即时的 (on-the-fly),能够灵活地把位置信息引入Transformer中。

CPVT生成编码是通过Positional Encoding Generator (PEG)实现的。首先把输入\(X \in \mathbb{R}^{B \times N \times C}\) reshape回3D的张量\(X^{\prime} \in \mathbb{R}^{B \times C \times H \times W}\),然后通过深度卷积处理该张量,再把输出变为\(X^{\prime \prime} \in \mathbb{R}^{B \times N \times C}\),与输入$X$连接后作为输出。整个过程中class token \(Y \in \mathbb{R}^{B \times C}\)保持不变。
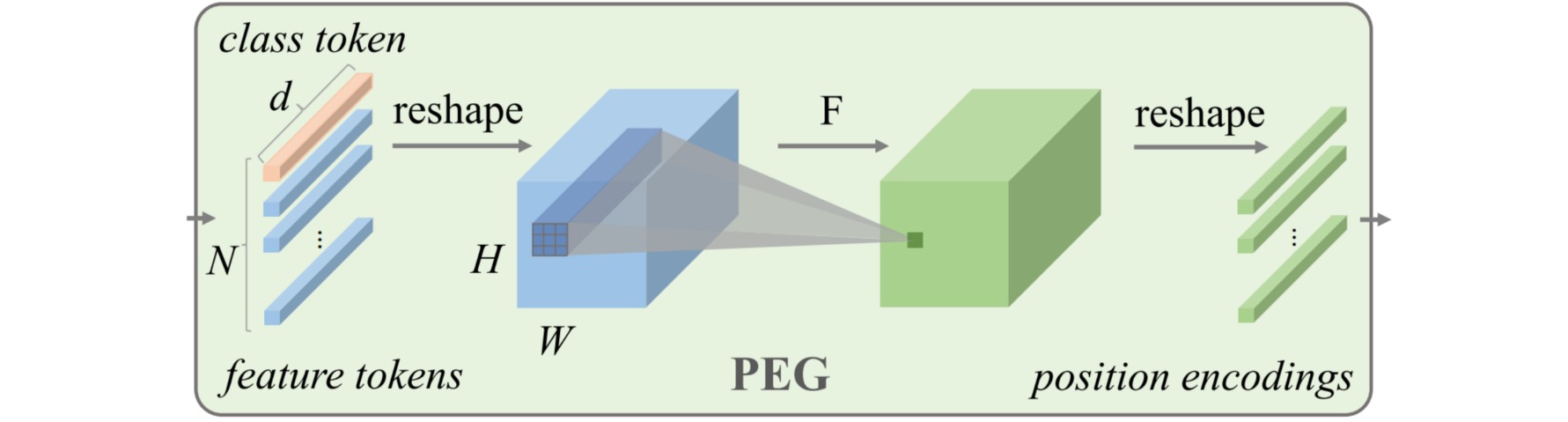
卷积操作的卷积核大小$k \geq 3$,零填充$p=\frac{k-1}{2}$。PEG的卷积部分以zero-padding作为参考点,以卷积操作提取相对位置信息,借助卷积得到适用于Transformer的可变长度的位置编码。可视化使用CPVT以后的attention maps,最左上方的格子关注的点在左上,而最左下方的格子关注的点在左下,以此类推,所以CPVT依然能够学习到local information。

class PEG(nn.Module):
def __init__(self, dim=256, k=3):
self.proj = nn.Conv2d(dim, dim, k, 1, k//2, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
cls_token, feat_token = x[:, 0], x[:, 1:]
cnn_feat = feat_token.transpose(1, 2).view(B, C, H, W)
x = self.proj(cnn_feat) + cnn_feat
x = x.flatten(2).transpose(1, 2)
x = torch.cat((cls_token.unsqueeze(1), x), dim=1)
return x


