T2T-ViT:在ImageNet上从头开始训练视觉Transformer.
使用中等大小的数据集 (如 ImageNet) 训练时,目前视觉Transformer的性能相比于 CNN 模型 (比如 ResNet) 更低,作者认为原因有2点:
- 视觉Transformer处理图像的方式不够好,无法建模一张图片的局部信息;
- 视觉Transformer的自注意力机制的 Backbone 不如 CNN 设计的好。
1. 改进图像处理方式
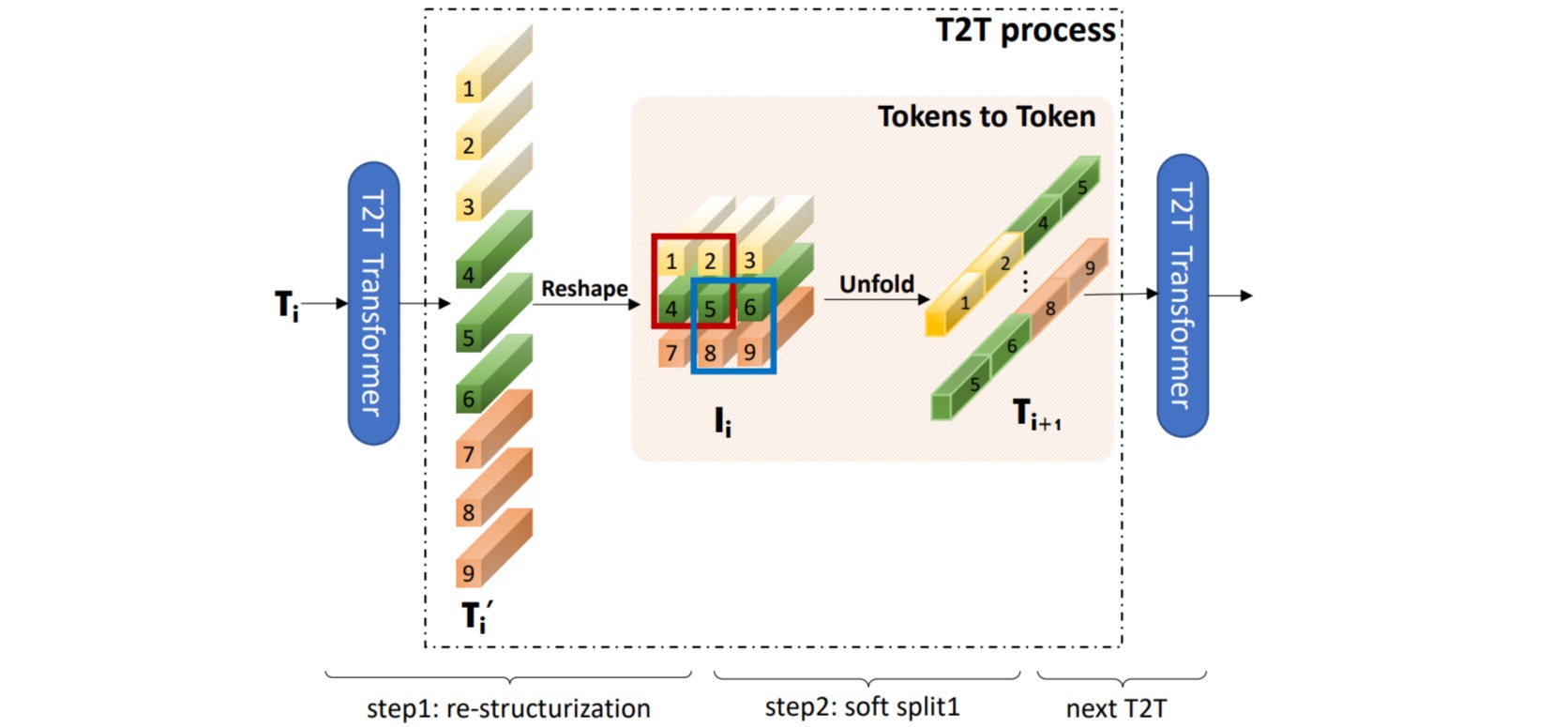
ViT将图片分成不同的patch后,对每个patch进行tokenization操作,不同patch之间没有Overlapping部分,等价于kernel_size和stride相等的Conv2d操作,是一种Hard Split操作。
作者提出了一种soft-split操作,每个patch中都包含有overlapping的部分,让每个token能够捕捉到更加精细的局部结构。这种操作称为Tokens-to-Token (T2T)。
T2T中用到了Pytorch提供的Unfold操作,这个操作的具体作用是在输入图像中按一定的stride和kernel_size,滑动地提取出局部区域块(只要stride比kernel_size小,提取出的局部区域块中就会有overlapping部分),然后把区域块内每个像素的特征拼接起来。
import torch
import torch.nn as nn
x = torch.randn(1, 3, 224, 224)
soft_split = nn.Unfold(kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))
x = soft_split(x).transpose(1,2) # size: 1, 3136, 147
x = self_attention(x) # 进行self-attention操作
B, new_HW, C = x.shape
x = x.transpose(1,2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
用一层Tokens-to-Token操作举例,假设输入的图像是$(3,224,224)$,经过Unfold操作后,将一个kernel中的tokens纵向拼接起来,生成的每一个token大小是$7\times 7\times 3=147$,其中$7\times 7$表示一个kernel中有49个token,3是channel维度;根据stride和padding计算后一共生成了3136个token,每个token的维度是147,再进行一次self-attention操作来处理生成的tokens,然后再reshape成feature map。为了防止因为不断的unfold操作导致每个token的维度越来越高,每一层的self-attention操作后都会将其投影回一个较低的维度,文中设置的是$64$。 T2T-ViT在生成最终输入进transformer encoder的token之前总共进行了三次tokens-to-token操作。

2. 改进自注意力机制
自注意力机制的 Backbone 一开始不是为 CV 任务设计的,所以在ViT中,注意力存在冗余设计,在有限的训练数据集中难以产生丰富的特征图。通过可视化ViT中的特征图发现,在其中存在大量无效的特征图(红色框),并且一些特征的局部细节不如卷积神经网络。

为了设计一种更高效的 Backbone,同时增加特征图的丰富性,作者借鉴了一些 CNN 的 Backbone 架构设计方案:
- 借鉴 DenseNet:使用 Dense 连接。
- 借鉴 Wide-ResNets:Deep-narrow vs. shallow-wide 结构对比。
- 借鉴 SE 模块:使用 Channel attention 结构。
- 借鉴 ResNeXt:在注意力机制中使用更多的 heads。
- 借鉴 GhostNet:使用 Ghost 模块。
经过比较作者得出了2个结论:
- 使用 Deep-narrow 架构,并减少 embedding dimension 更适合视觉 Transformer,可以增加特征的丰富程度,同时也可以降低计算量。
- SE 模块的 Channel attention 结构也可以提升 ViT 的性能,但是效果不如前者。
根据以上结论,作者设计了一个 Deep-narrow 架构的 T2T Backbone,它的 embedding dimension 比较小,同时层数较多:

一个完整的T2T-ViT网络首先通过 T2T 模块对图像的局部信息进行建模,再通过 T2T-ViT 的 Backbone提取特征用于下游任务。T2T 模块有$3$层,会进行3次 Soft Split 操作和2次 Restructurization 操作。其中3次 unfold 操作使用的卷积核的大小分别是$[7,3,3]$,patches 之间重叠的大小分别是$[3,1,1]$, stride 的大小分别是$[4,2,2]$。T2T 模块会把 $224×224$ 大小的图片变成 $14×14$ 大小。T2T 模块的输出张量进入 T2T Backbone 里面, T2T Backbone 有14层 Block,embedding dimension 大小是384。
T2T-ViT的完整实现可参考vit-pytorch。
import math
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# helpers
def conv_output_size(image_size, kernel_size, stride, padding):
return int(((image_size - kernel_size + (2 * padding)) / stride) + 1)
# classes
class RearrangeImage(nn.Module):
def forward(self, x):
return rearrange(x, 'b (h w) c -> b c h w', h = int(math.sqrt(x.shape[1])))
# main class
class T2TViT(nn.Module):
def __init__(self, *, image_size, num_classes, dim, depth = None, heads = None, mlp_dim = None, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0., transformer = None, t2t_layers = ((7, 4), (3, 2), (3, 2))):
super().__init__()
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
layers = []
layer_dim = channels
output_image_size = image_size
for i, (kernel_size, stride) in enumerate(t2t_layers):
layer_dim *= kernel_size ** 2
is_first = i == 0
is_last = i == (len(t2t_layers) - 1)
output_image_size = conv_output_size(output_image_size, kernel_size, stride, stride // 2)
layers.extend([
RearrangeImage() if not is_first else nn.Identity(),
nn.Unfold(kernel_size = kernel_size, stride = stride, padding = stride // 2),
Rearrange('b c n -> b n c'),
Transformer(dim = layer_dim, heads = 1, depth = 1, dim_head = layer_dim, mlp_dim = layer_dim, dropout = dropout) if not is_last else nn.Identity(),
])
layers.append(nn.Linear(layer_dim, dim))
self.to_patch_embedding = nn.Sequential(*layers)
self.pos_embedding = nn.Parameter(torch.randn(1, output_image_size ** 2 + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :n+1]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)


