PVT:一种无卷积密集预测的通用骨干.
目前流行的ViT backbone本身并没有针对视觉中诸如分割、检测等密集预测型的任务设计合适的结构。这些ViT通常只能提取到单尺度特征。在语义分割任务上,多尺度的特征是非常重要的,因此本文提出了一种能够提取多尺度特征的vision transformer backbone:PVT。
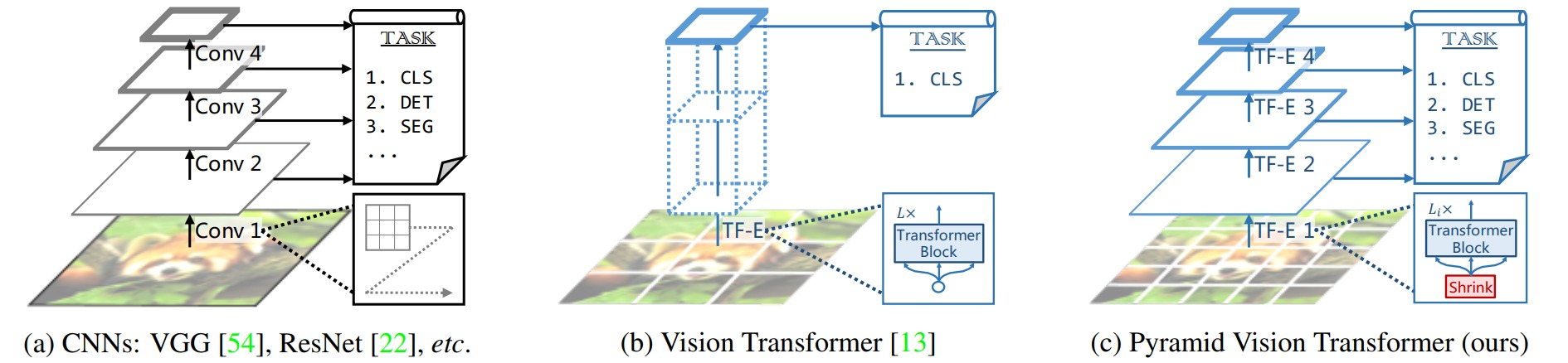
ViT的设计方案中输出的特征图和输入大小基本保持一致,将其应用到分割、检测等密集预测任务上将会面临着两方面的问题:
- 计算开销剧增:分割和检测相对于分类任务而言,往往需要较大的分辨率图片输入,因此需要划分更多个patch才能得到相同粒度的特征。如果仍然保持同样的patch数量,那么特征的粒度将会变粗,从而导致性能下降。另一方面,Transformer的计算开销与token化后的patch数量正相关, patch数量越大,计算开销越大。
- 缺乏多尺度特征:ViT 输出的特征图和输入大小基本保持一致。这导致ViT作为Encoder时,只能输出单尺度的特征。而在CNN中,多尺度的特征已经早就被证实对分割、检测等任务有着重要的作用,有效的利用多尺度特征能够取得性能上的提升。
针对上述两点问题,作者设计了PVT,可以作为密集预测任务的ViT backbone。模型总体上由4个stage组成,每个stage包含Patch Embedding和若干个修改的Transformer模块组成。
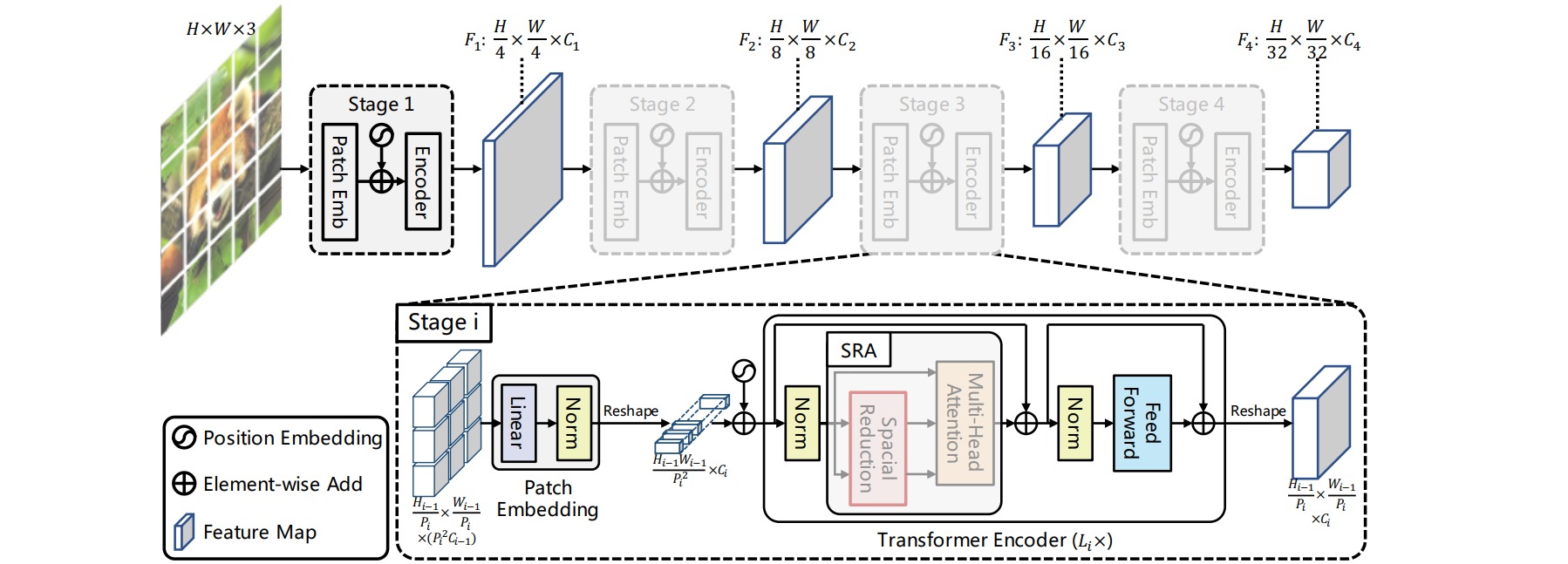
⚪ Patch Embedding
在每个stage开始,首先像ViT一样对输入图像进行token化,即进行patch embedding,patch大小除第1个stage的是4x4外,其余均采用2x2大小。这意味着每个stage(第一个stage除外)最终得到的特征图维度是减半的,tokens数量对应减少4倍。每个patch随后会送入一层Linear中,调整通道数量,然后再reshape以将patch token化。
这使得PVT总体上与resnet看起来类似,4个stage得到的特征图相比原图大小分别是1/4,1/8,1/16 和 1/32。这也意味着PVT可以产生不同尺度的特征。由于不同的stage的tokens数量不一样,所以每个stage采用不同的position embeddings,在patch embed之后加上各自的position embedding;当输入图像大小变化时,position embeddings也可以通过插值来自适应。
⚪ Spatial-reduction attention(SRA)

在Patch embedding之后,需要将token化后的patch输入到若干个transformer 模块中进行处理。为了进一步减少计算量,作者将multi-head attention (MHA)用所提出的spatial-reduction attention (SRA)来替换,在MHA中将K和V的空间分辨率都降低了R倍。在实现上,首先将维度为(HW,C)的K,V通过 reshape变换到维度为(H,W,C)的3-D特征图,然后均分大小为R × R的patchs,每个patchs通过线性变换将得到维度为(HW / R×R,C)的patch embeddings,最后应用一个layer norm层,这样就可以大大降低K和V的数量。
⚪ 代码实现
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
# Spatial-reduction attention(SRA)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, H, W):
x = x + self.attn(self.norm1(x), H, W)
x = x + self.mlp(self.norm2(x))
return x
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
# assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
# f"img_size {img_size} should be divided by patch_size {patch_size}."
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
class PyramidVisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
for i in range(num_stages):
patch_embed = PatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
patch_size=patch_size if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
num_patches = patch_embed.num_patches if i != num_stages - 1 else patch_embed.num_patches + 1
pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dims[i]))
pos_drop = nn.Dropout(p=drop_rate)
block = nn.ModuleList([Block(
dim=embed_dims[i], num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate,
norm_layer=norm_layer, sr_ratio=sr_ratios[i])
for j in range(depths[i])])
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"pos_embed{i + 1}", pos_embed)
setattr(self, f"pos_drop{i + 1}", pos_drop)
setattr(self, f"block{i + 1}", block)
self.norm = norm_layer(embed_dims[3])
# cls_token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims[3]))
# classification head
self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def forward_features(self, x):
B = x.shape[0]
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
pos_embed = getattr(self, f"pos_embed{i + 1}")
pos_drop = getattr(self, f"pos_drop{i + 1}")
block = getattr(self, f"block{i + 1}")
x, (H, W) = patch_embed(x)
if i == self.num_stages - 1:
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
pos_embed_ = self._get_pos_embed(pos_embed[:, 1:], patch_embed, H, W)
pos_embed = torch.cat((pos_embed[:, 0:1], pos_embed_), dim=1)
else:
pos_embed = self._get_pos_embed(pos_embed, patch_embed, H, W)
x = pos_drop(x + pos_embed)
for blk in block:
x = blk(x, H, W)
if i != self.num_stages - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return


