CeiT:将卷积设计整合到视觉Transformers中.
CeiT想借助CNN来提升Transformer的性能,作者认为CNN最重要的特征是不变性 (invariance) 和局部性 (locality)。不变性是指卷积的权重共享机制,使得卷积能够捕获一个相邻区域的特征且具有平移不变性;局部性是指在视觉任务中,相邻的pixel之间往往是相互关联的。
但是Transformer很难利用好这些特性,即很难高效地提取low-level的特征,self-attention模块的长处是提炼token之间的long-range的信息之间的关系,往往会忽略空间信息。基于此,作者想把CNN的特性融入进来以解决这些问题,使模型既具备CNN的提取low-level特征的能力,强化局部特征的提取,也具有Transformer的提炼token之间的 long-range 的信息之间的关系的能力。
为了有效地提取low-level feature,作者通过 Image-to-tokens 先使用卷积+Flatten操作把图片变为tokens,而不是通过直接分patch的方法。为了强化局部特征的提取,作者把MLP层的Feed-Forwardnetwork换成了 Locally-enhanced Feed-Forward layer,在空间维度上促进相邻token之间的相关性。除此之外,在Transformer顶部使用 Layer-wise Class token Attention 进一步提升性能。
1. Image-to-tokens
ViT采用的是直接把一张$H\times W$的图片分成$N$个patch,每个patch的大小是$P \times P$的,所以patch的数量$N=HW/P^2$。但这么做会很难捕捉到low-level的信息,比如图片的边和角的信息。而且self-attention建模的是全局的信息,所以相当于是使用了很大的kernel,这样的kernel由于参数量过多导致很难训练,需要大量的数据。
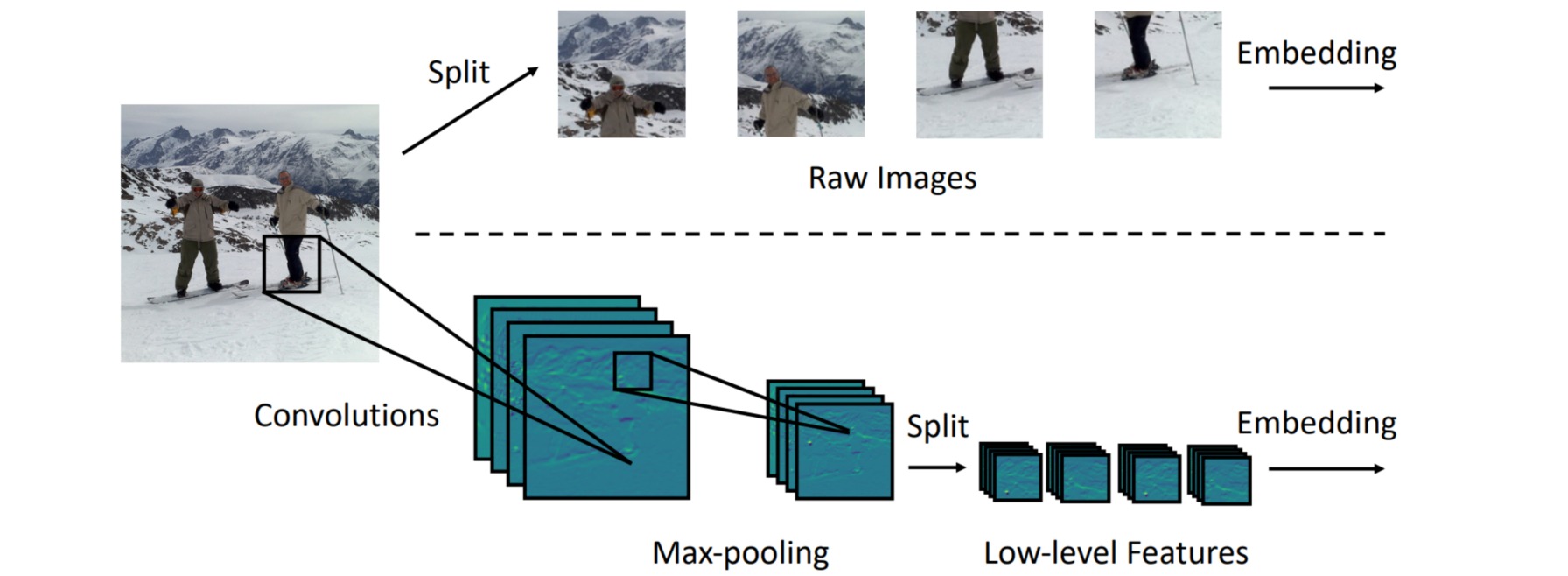
鉴于此作者提出了Image-to-tokens模块,如图所示是一个轻量化的模块,由一个卷积操作加上一个Batch Normalization + Max-pooling构成:
\[x' = I2T(x) = MaxPool(BN(Conv(x)))\]其中$x’ \in R^{H/S \times W/S \times D}$,$S$是卷积操作的stride值,$D$是做完卷积操作以后的channel数。这步卷积得到的$x’$会再分成patch,为了保持与ViT的patch数量的一致性,此时的patch的大小将有原来的$P \times P$变为$P/S \times P/S$,其中的$S=4$。I2T模块充分利用了卷积在提取low-level的特征方面的优势,通过缩小patch的大小来降低嵌入的训练难度。
2. Locally-enhanced Feed-Forward layer
为了结合CNN提取局部信息的优势和Transformer建立远程依赖关系的能力,强化局部特征的提取,作者把MLP层的Feed-Forwardnetwork 换成了 Locally-enhanced Feed-Forward layer,在空间维度上促进相邻token之间的相关性。
具体的做法是:保持MSA模块不变,保留捕获token之间全局相似性的能力。相反,原来的前馈网络层被Locally-enhanced Feed-Forward layer (LeFF)取代。结构如图所示。

LeFF的具体流程是:首先输入的token $x_t^h \in R^{(N+1)\times C}$由前面的MSA模块得到,然后分成2部分,第1部分是把class token $x_c^h \in R^{C}$单独拿出来,剩下的第2部分是$x_p^h \in R^{N\times C}$。接着把第2部分通过linear projection拓展到高维的$x_p^{l_1} \in R^{N\times (eC)}$,其中$e$代表expand ratio。接着将其还原成2D的图片$x_p^{s} \in R^{\sqrt{N}\times \sqrt{N}\times (eC)}$,再通过Depth-wise convolution得到$x_p^{d} \in R^{\sqrt{N}\times \sqrt{N}\times (eC)}$,再Flatten成$x_p^{f} \in R^{N\times (eC)}$的张量。最后通过Linear Projection映射回原来的维度$x_p^{l_2} \in R^{N\times C}$,并与一开始的class token concat起来得到$x_{t+1}^h \in R^{(N+1)\times C}$。每个Linear Projection和convolution之后都会加上BatchNorm 和 GELU 操作。总的流程可以写成下式:
\[\begin{aligned} \mathbf{x}_c^h, \mathbf{x}_p^h & =\operatorname{Split}\left(\mathbf{x}_t^h\right) \\ \mathbf{x}_p^{l_1} & =\operatorname{GEL}\left(\operatorname{BN}\left(\operatorname{Linear} 1\left(\mathbf{x}_p^h\right)\right)\right) \\ \mathbf{x}_p^s & =\operatorname{SpatialRestore}\left(\mathbf{x}_p^{l_1}\right) \\ \mathbf{x}_p^d & =\operatorname{GELU}\left(\operatorname{BN}\left(\operatorname{DWConv}\left(\mathbf{x}_p^s\right)\right)\right) \\ \mathbf{x}_p^f & =\operatorname{Flatten}\left(\mathbf{x}_p^d\right) \\ \mathbf{x}_p^{l_2} & =\operatorname{GELU}\left(\operatorname{BN}\left(\operatorname{Linear} 2\left(\mathbf{x}_p^f\right)\right)\right) \\ \mathbf{x}_t^{h+1} & =\operatorname{Concat}\left(\mathbf{x}_c^h, \mathbf{x}_p^{l_2}\right) \end{aligned}\]3. Layer-wise Class token Attention
在CNN中,随着网络层数的加深,感受野在不断地变大。所以不同layer的feature representation是不同的。为了综合不同layer的信息,作者提出了Layer-wise Class token Attention模块,它把$L$个layer的class token都输入进去,并经过一次Multi-head Self-attention模块和一个FFN网络,得到最终的output,如下图所示。它计算的是这$L$个layer的class token的相互关系。



