DeiT:通过注意力蒸馏训练数据高效的视觉Transformer.
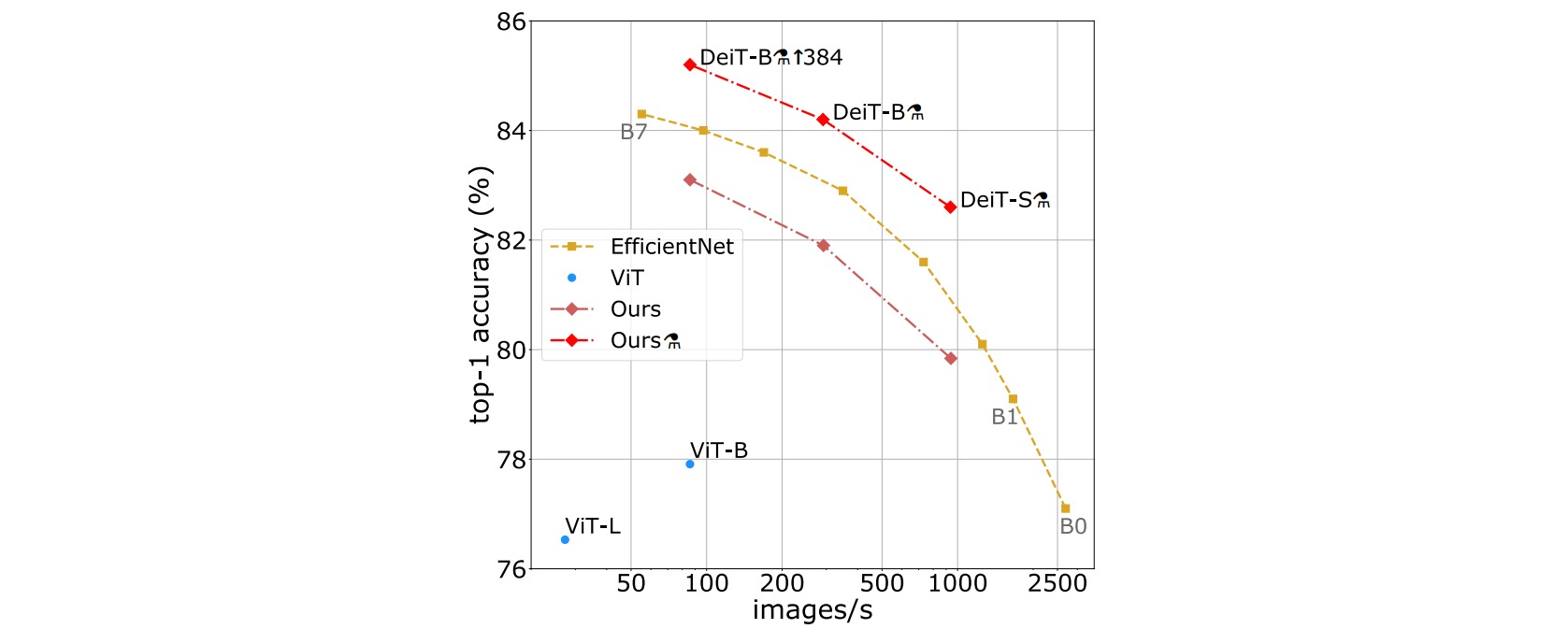
本文作者提出了DeiT,通过教师-学生网络的蒸馏策略,使得使用卷积网络作为教师时能够高效地训练视觉Transformer,只需单节点4GPU服务器在三天内就可以在ImageNet训练得到和SOTA相比具有竞争力的结果。
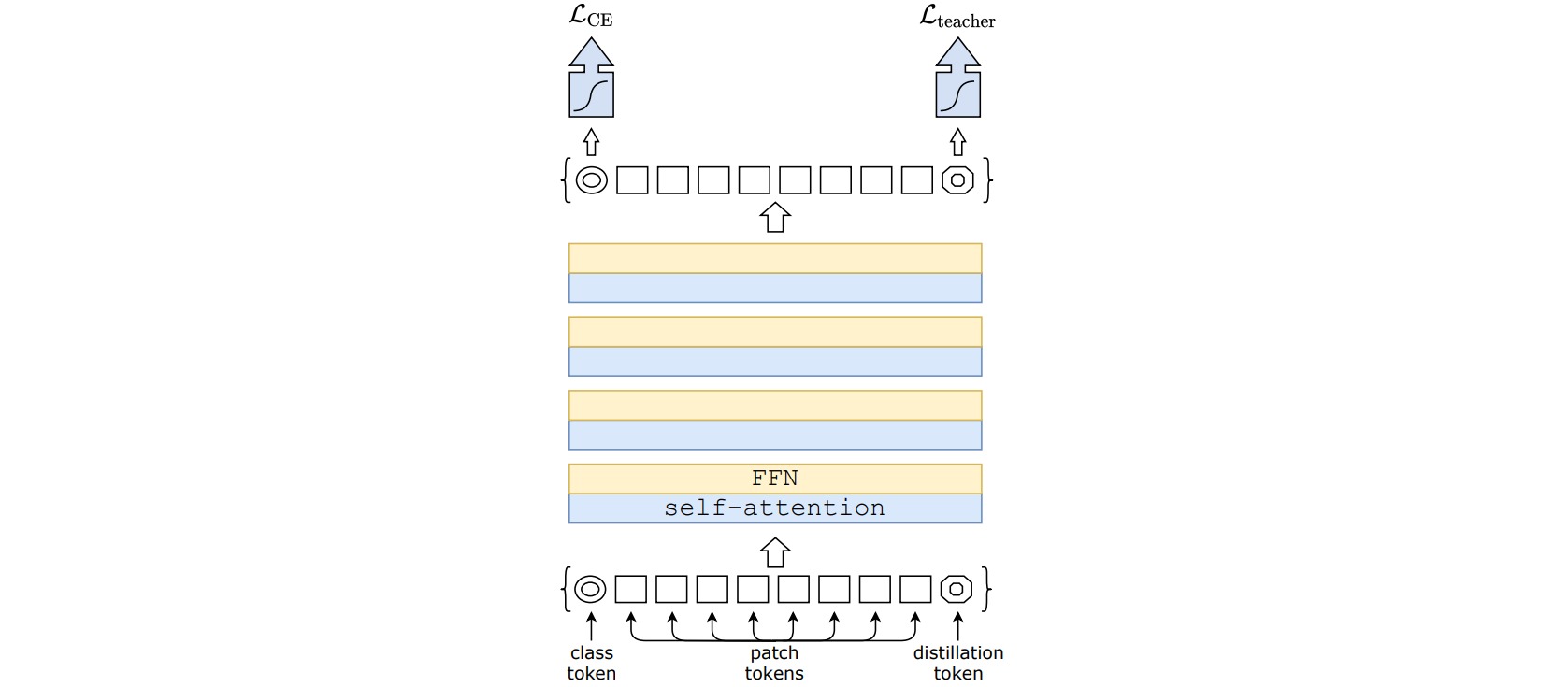
DeiT的网络结构与ViT基本一致,主要区别在于在输入图像块序列尾部添加了一个蒸馏token。蒸馏token和其他token通过注意力机制进行交互。类别token的输出特征以真实值作为目标进行学习,蒸馏token的输出特征以教师网络输出作为目标进行学习。
假设教师网络输出逻辑分数$Z_t$,学生网络输出逻辑分数$Z_s$,真实分类值为$y$,$\Psi$表示softmax函数,$y_t$是教师网络的决策结果(one hot向量)。在蒸馏过程中可以使用硬蒸馏和软蒸馏两种形式。
硬蒸馏是指分别以真实值$y$和教师网络决策结果$y_t$为基准,通过交叉熵损失进行学习:
\[\mathcal{L}_{\text {global }}^{\text {hardDistill }}=\frac{1}{2} \mathcal{L}_{\mathrm{CE}}\left(\psi\left(Z_s\right), y\right)+\frac{1}{2} \mathcal{L}_{\mathrm{CE}}\left(\psi\left(Z_s\right), y_{\mathrm{t}}\right)\]实验时使用label smoothing的方法,让真实标签具有$1-\epsilon$概率,其他标签具有$\epsilon / (K-1)$概率,实验中设置$\epsilon=0.1$。
软蒸馏是指以真实值$y$为基准通过交叉熵损失进行学习;同时以KL散度衡量教师网络和学生网络预测结果的差异。
\[\mathcal{L}_{\text {global }}=(1-\lambda) \mathcal{L}_{\mathrm{CE}}\left(\psi\left(Z_{\mathrm{s}}\right), y\right)+\lambda \tau^2 \mathrm{KL}\left(\psi\left(Z_{\mathrm{s}} / \tau\right), \psi\left(Z_{\mathrm{t}} / \tau\right)\right)\]作者验证了class Token和distillation Token的余弦相似度,在所有层中,二者的平均余弦相似度约为$0.06$。但是从输入到最终的输出层,二者的余弦相似度不断提高,最终达到$0.93$。 作为对照,两个class token的余弦相似度达到$0.999$。这说明distillation Token确实发挥了和class token不同的作用。
DeiT在训练过程中使用了大量数据增强方法,并且使用高分辨率图像进行精调。此外在分类时使用了class Token和distillation Token的逻辑分数层面的融合,将二者的分数相加后送入softmax再求概率。

作者对优化器和数据增强进行了全面的消融实验:

此外DeiT提供了一组优秀的超参数,它可以在不改变ViT模型结构的前提下实现涨点。

DeiT的完整实现可参考vit-pytorch,其主体结构与ViT相同,主要区别是在输入序列后增加了一个distillation Token:
class DeiT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = (image_size, image_size)
patch_height, patch_width = (patch_size, patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.distillation_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
self.distill_mlp = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
distill_tokens = repeat(distill_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((x, distill_tokens), dim = 1)
x = self.dropout(x)
x = self.transformer(x)
x, distill_tokens = x[:, :-1], x[:, -1]
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x), self.distill_mlp(distill_tokens)
分别使用硬蒸馏和软蒸馏方式构造损失函数:
class DistillWrapper(nn.Module):
def __init__(
self,
*,
teacher,
student,
temperature = 1.,
alpha = 0.5,
hard = False
):
super().__init__()
self.teacher = teacher
self.student = student
self.temperature = temperature
self.alpha = alpha
self.hard = hard
def forward(self, img, labels, temperature = None, alpha = None, **kwargs):
b, *_ = img.shape
alpha = alpha if exists(alpha) else self.alpha
T = temperature if exists(temperature) else self.temperature
with torch.no_grad():
teacher_logits = self.teacher(img)
student_logits, distill_logits = self.student(img)
loss = F.cross_entropy(student_logits, labels)
if not self.hard:
distill_loss = F.kl_div(
F.log_softmax(distill_logits / T, dim = -1),
F.softmax(teacher_logits / T, dim = -1).detach(),
reduction = 'batchmean')
distill_loss *= T ** 2
else:
teacher_labels = teacher_logits.argmax(dim = -1)
distill_loss = F.cross_entropy(distill_logits, teacher_labels)
return loss * (1 - alpha) + distill_loss * alpha
实例化一个DeiT的例子如下,使用Resnet50作为教师网络:
import torch
from torchvision.models import resnet50
teacher = resnet50(pretrained = True)
v = DeiT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
distiller = DistillWrapper(
student = v,
teacher = teacher,
temperature = 3, # temperature of distillation
alpha = 0.5, # trade between main loss and distillation loss
hard = False # whether to use soft or hard distillation
)
img = torch.randn(2, 3, 256, 256)
labels = torch.randint(0, 1000, (2,))
loss = distiller(img, labels)
loss.backward()
# after lots of training above ...
pred = v(img) # (2, 1000)


