CaiT:更深的视觉Transformer.
CaiT旨在为图像分类构建和优化更深层次的Vision Transformer,主要贡献有二:
- 引入LayerScale,即对残差模块的输出进行按特征维度的乘法。这个方法解决残差连接的问题,其本质是残差连接会放大方差。
- 发现Image Patches和Class Token的优化目标矛盾,提出Class-Attention Layer,将两者优化参数分离。
1. LayerScale
作者发现随着网络加深,Vision Transformer的精度不再提升,主要是残差连接部分出现了问题。因此在残差块的输出上引入了可学习的向量权重,对输出特征的通道进行加权。
\[\begin{aligned} x_l^{\prime} & =x_l+\alpha_l \operatorname{SA}\left(x_l\right) \\ x_{l+1} & =x_l^{\prime}+\alpha_l^{\prime} \operatorname{FFN}\left(x_l^{\prime}\right) \end{aligned}\]
作为对比,图a表示标准的残差块,其中$\eta$为LayerNorm。图b引入可学习的标量权重,并移除了LayerNorm,该结构无法收敛。图c引入可学习的标量权重,效果不如可学习的向量权重。
可学习的向量权重作用于embedding dimension,在18层之前初始化为$0.1$。若网络更深则在24层之前初始化为$1e-5$,在之后更深的网络中初始化为$1e-6$。这样做使得每个block在一开始的时候更接近Identity mapping,在训练的过程中逐渐地学习到残差信息。作者通过实验证明,以这种方式训练网络更容易。
2. Class-Attention Layer
此外作者提出把Class Token与Patch Token分离的Class-Attention Layer,其整体相当于一个编码器-解码器结构。在网络前半部分,Patch Token相互交互计算注意力;而在网络最后几层,Patch Token不再改变,Class Token与其交互计算注意力。

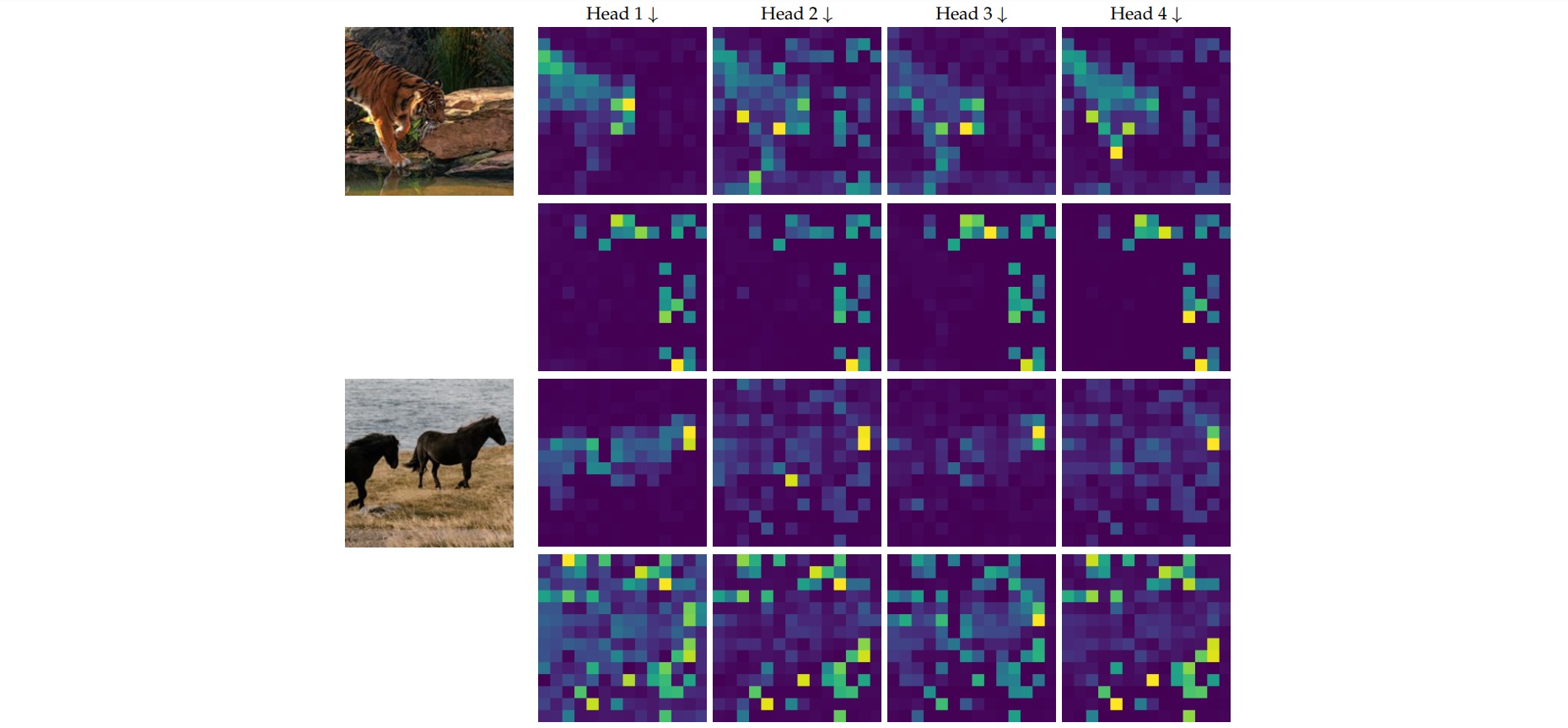
作者可视化模型的2个CA层的attention map,观察发现:
- 第1个class-attention层关注图片中的object多一点,不同的head关注不同的部位。
- 第2个class-attention层关注图片的背景信息或全局信息。
CaiT的完整实现可参考vit-pytorch。其中在Vision Transformer中有四个改进点:为残差连接引入特征的通道加权(LayerScale)、实现Class-Attention Layer(context)、为注意力引入Talking Heads机制、引入随机深度(dropout_layer),本文只关注前两者。
class LayerScale(nn.Module):
def __init__(self, dim, fn, depth):
super().__init__()
if depth <= 18: # epsilon detailed in section 2 of paper
init_eps = 0.1
elif depth > 18 and depth <= 24:
init_eps = 1e-5
else:
init_eps = 1e-6
scale = torch.zeros(1, 1, dim).fill_(init_eps)
self.scale = nn.Parameter(scale)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(x, **kwargs) * self.scale
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
self.heads = heads
self.scale = dim_head ** -0.5
self.to_q = nn.Linear(dim, inner_dim, bias = False)
self.to_kv = nn.Linear(dim, inner_dim * 2, bias = False)
# 以下略
def forward(self, x, context = None):
b, n, _, h = *x.shape, self.heads
context = x if (context is None) else torch.cat((x, context), dim = 1)
qkv = (self.to_q(x), *self.to_kv(context).chunk(2, dim = -1)
# 以下略
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for ind in range(depth):
self.layers.append(nn.ModuleList([
LayerScale(dim, PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)), depth = ind + 1),
LayerScale(dim, PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout)), depth = ind + 1)
]))
def forward(self, x, context = None):
for attn, ff in self.layers:
x = attn(x, context = context) + x
x = ff(x) + x
return x
在CaiT中,设置depth层Self-Attention Layer,cls_depth层Class-Attention Layer:
class CaiT(nn.Module):
def __init__(
self,
*,
image_size,
patch_size,
num_classes,
dim,
depth,
cls_depth,
heads,
mlp_dim,
dim_head = 64,
dropout = 0.,
emb_dropout = 0.,
):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_size // patch_size) ** 2
patch_dim = 3 * patch_size ** 2
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim)
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.patch_transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.cls_transformer = Transformer(dim, cls_depth, heads, dim_head, mlp_dim, dropout)
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
x += self.pos_embedding[:, :n]
x = self.dropout(x)
x = self.patch_transformer(x)
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = self.cls_transformer(cls_tokens, context = x)
return self.mlp_head(x[:, 0])


