CrossViT:图像分类的交叉注意力多尺度视觉Transformer.
多尺度的特征表示已被证明对许多视觉任务有益。本文作者研究了如何学习Transformer模型中的多尺度特征表示,以进行图像识别。具体地,作者提出了一种双分支Transformer来组合不同大小的图像patch,以产生更强的视觉特征作为图像分类的依据。该方法处理具有不同计算复杂度的两个独立分支的小patch和大patch token,这些token多次融合以相互补充。为了减少计算量,作者还开发了一个简单而有效的基于交叉注意的token融合模块,该模块为每个分支使用单个token作为查询,与其他分支交换信息。所提出的的交叉注意只需要计算和内存复杂度的线性时间,而不需要二次时间。
⚪ Multi-Scale Vision Transformer
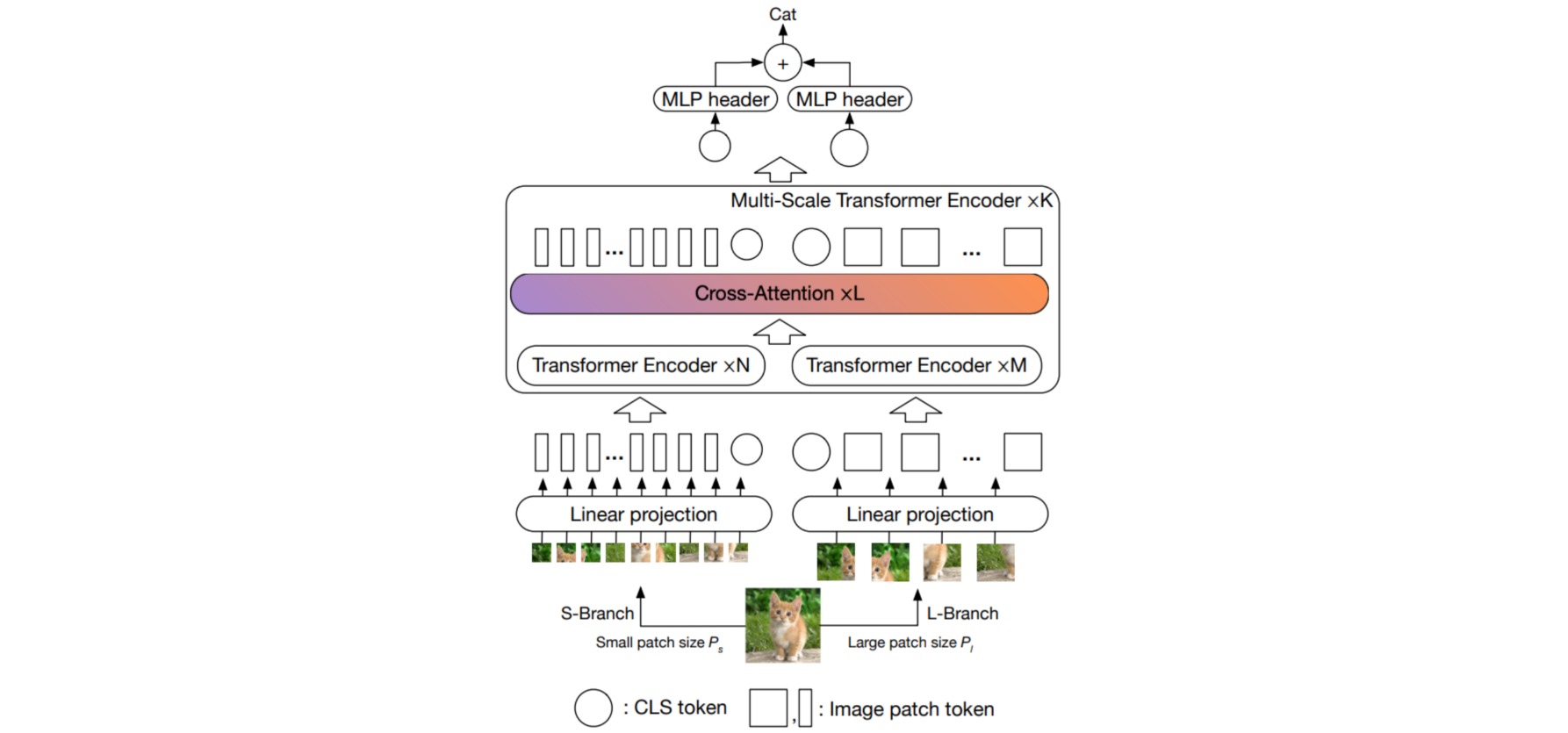
patch大小的粒度会影响ViT的准确性和复杂性;使用细粒度的patch大小,ViT可以表现得更好,但会导致更高的FLOPs和内存消耗。例如,patch大小为16的ViT比patch大小为32的ViT性能要好$6\%$,但前者需要多4×的序列长度。在此基础上,作者提出的方法是试图利用更细粒度的patch大小的优势,同时平衡复杂性。作者首先引入了一个双分支CrossViT,其中每个分支以不同的patch大小运行,然后提出了一个简单而有效的模块来融合分支之间的信息。
CrossViT由K个多尺度Transformer编码器组成。每个多尺度Transformer编码器使用两个不同的分支处理不同大小的图像token($P_s$和$P_l$),并通过一个基于CLS token交叉注意的有效模块融合token。编码器包括了两个分支中不同数量(即$N$和$M$)的常规Transformer编码器,以平衡计算成本。
class MultiScaleEncoder(nn.Module):
def __init__(
self,
*,
depth,
sm_dim,
lg_dim,
sm_enc_params,
lg_enc_params,
cross_attn_heads,
cross_attn_depth,
cross_attn_dim_head = 64,
dropout = 0.
):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Transformer(dim = sm_dim, dropout = dropout, **sm_enc_params),
Transformer(dim = lg_dim, dropout = dropout, **lg_enc_params),
CrossTransformer(sm_dim = sm_dim, lg_dim = lg_dim, depth = cross_attn_depth, heads = cross_attn_heads, dim_head = cross_attn_dim_head, dropout = dropout)
]))
def forward(self, sm_tokens, lg_tokens):
for sm_enc, lg_enc, cross_attend in self.layers:
sm_tokens, lg_tokens = sm_enc(sm_tokens), lg_enc(lg_tokens)
sm_tokens, lg_tokens = cross_attend(sm_tokens, lg_tokens)
return sm_tokens, lg_tokens
⚪ Multi-Scale Feature Fusion
有效的特征融合是学习多尺度特征表示的关键。作者探索了四种不同的方法融合解决策略:三种简单的启发式方法和所提出的交叉注意模块,如图所示。

- (a)全注意融合,将两个branch的token concatenate起来。
- (b)类标token融合,class token可以视为是一个branch的全局特征表示,因此一个直接的方法是将两个branch的class token加起来作为两个branch后续的class token。
- (c)成对融合,其中相应空间位置的token融合在一起,CLS分别融合。由于两个branch的patch size不一样,数量不一样,作者选择对patch进行插值来对齐以解决这个问题。
- (d)交叉注意,其中来自一个分支的CLS token和来自另一个分支的patch token融合在一起。
交叉注意融合涉及到一个分支的CLS token和另一个分支的patch token。具体来说,为了更有效地融合多尺度特征,首先利用每个分支上的CLS token作为代理,在来自另一个分支的patch token之间交换信息,然后将其重新投影到自己的分支中。由于CLS token已经在其自己的分支中的所有patch token中学习了抽象信息,因此与另一个分支中的patch token的交互有助于包含不同规模的信息。在与其他分支token融合后,CLS token在下一个编码器层上再次与自己的patch token交互,它能够将来自另一个分支的学习信息传递给自己的patch token,以丰富每个patch token的表示。

一个分支的CLS token作为一个查询token,通过注意与从另一个分支中获得的patch token 进行交互。$f^l(\cdot)$和$g^l(\cdot)$是调整尺寸的投影。由于只在查询中使用CLS,因此在交叉注意中生成注意图的计算和内存复杂度是线性的,而不是像在全注意中那样是二次的,这使整个过程更加有效。此外在交叉注意后,不应用前馈网络FFN。
实验表明,与其他三种简单的启发式方法相比,交叉注意获得了最好的精度,同时对多尺度特征融合也很有效。

class CrossTransformer(nn.Module):
def __init__(self, sm_dim, lg_dim, depth, heads, dim_head, dropout):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
ProjectInOut(sm_dim, lg_dim, PreNorm(lg_dim, Attention(lg_dim, heads = heads, dim_head = dim_head, dropout = dropout))),
ProjectInOut(lg_dim, sm_dim, PreNorm(sm_dim, Attention(sm_dim, heads = heads, dim_head = dim_head, dropout = dropout)))
]))
def forward(self, sm_tokens, lg_tokens):
(sm_cls, sm_patch_tokens), (lg_cls, lg_patch_tokens) = map(lambda t: (t[:, :1], t[:, 1:]), (sm_tokens, lg_tokens))
for sm_attend_lg, lg_attend_sm in self.layers:
sm_cls = sm_attend_lg(sm_cls, context = lg_patch_tokens, kv_include_self = True) + sm_cls
lg_cls = lg_attend_sm(lg_cls, context = sm_patch_tokens, kv_include_self = True) + lg_cls
sm_tokens = torch.cat((sm_cls, sm_patch_tokens), dim = 1)
lg_tokens = torch.cat((lg_cls, lg_patch_tokens), dim = 1)
return sm_tokens, lg_tokens
⚪ CrossViT
CrossViT的完整实现可参考vit-pytorch。
class CrossViT(nn.Module):
def __init__(
self,
*,
image_size,
num_classes,
sm_dim,
lg_dim,
sm_patch_size = 12,
sm_enc_depth = 1,
sm_enc_heads = 8,
sm_enc_mlp_dim = 2048,
sm_enc_dim_head = 64,
lg_patch_size = 16,
lg_enc_depth = 4,
lg_enc_heads = 8,
lg_enc_mlp_dim = 2048,
lg_enc_dim_head = 64,
cross_attn_depth = 2,
cross_attn_heads = 8,
cross_attn_dim_head = 64,
depth = 3,
dropout = 0.1,
emb_dropout = 0.1
):
super().__init__()
self.sm_image_embedder = ImageEmbedder(dim = sm_dim, image_size = image_size, patch_size = sm_patch_size, dropout = emb_dropout)
self.lg_image_embedder = ImageEmbedder(dim = lg_dim, image_size = image_size, patch_size = lg_patch_size, dropout = emb_dropout)
self.multi_scale_encoder = MultiScaleEncoder(
depth = depth,
sm_dim = sm_dim,
lg_dim = lg_dim,
cross_attn_heads = cross_attn_heads,
cross_attn_dim_head = cross_attn_dim_head,
cross_attn_depth = cross_attn_depth,
sm_enc_params = dict(
depth = sm_enc_depth,
heads = sm_enc_heads,
mlp_dim = sm_enc_mlp_dim,
dim_head = sm_enc_dim_head
),
lg_enc_params = dict(
depth = lg_enc_depth,
heads = lg_enc_heads,
mlp_dim = lg_enc_mlp_dim,
dim_head = lg_enc_dim_head
),
dropout = dropout
)
self.sm_mlp_head = nn.Sequential(nn.LayerNorm(sm_dim), nn.Linear(sm_dim, num_classes))
self.lg_mlp_head = nn.Sequential(nn.LayerNorm(lg_dim), nn.Linear(lg_dim, num_classes))
def forward(self, img):
sm_tokens = self.sm_image_embedder(img)
lg_tokens = self.lg_image_embedder(img)
sm_tokens, lg_tokens = self.multi_scale_encoder(sm_tokens, lg_tokens)
sm_cls, lg_cls = map(lambda t: t[:, 0], (sm_tokens, lg_tokens))
sm_logits = self.sm_mlp_head(sm_cls)
lg_logits = self.lg_mlp_head(lg_cls)
return sm_logits + lg_logits


