Semi-Supervised Learning.
半监督学习(Semi-Supervised Learning)是指同时从有标签数据和无标签数据中进行学习,适用于标注数据有限、标注成本较高的场合。值得一提的是,目前半监督学习方法主要是为视觉任务设计的,而在自然语言任务中通常采用预训练+微调的学习流程。
在半监督学习中,通过有标签数据构造监督损失\(\mathcal{L}_s\),通过无标签数据构造无监督损失\(\mathcal{L}_u\),总损失函数通过权重项$\mu$加权:
\[\mathcal{L} = \mathcal{L}_s + \mu \mathcal{L}_u\]其中权重项$\mu=\mu(t)$通常设置为随训练轮数$t$变化的斜坡函数(ramp function),以逐渐增大无监督损失的重要性。
半监督学习的一些假设:
- 平滑性假设 (Smoothness Assumption):如果两个数据样本在特征空间的高密度区域中接近,则他们的标签应该相同或非常相似。
- 聚类假设 (Cluster Assumption):特征空间既有高密度区域又有稀疏区域。高密度分组的数据点自然形成一个聚类集群。同一集群中的样本应具有相同的标签。
- 低密度分离假设 (Low-density Separation Assumption):样本类别之间的决策边界倾向于位于稀疏的低密度区域;否则决策边界会将一个高密度集群划分为两个类,对应于两个集群,这会使平滑性假设和聚类假设无效。
- 流形假设 (Manifold Assumption):高维数据往往位于低维流形上。尽管真实世界数据通常在非常高的维度上观察到,它们实际上可以由较低维度的流形来捕获,其中某些属性相似的点被分为相近的分组。流形假设是表示学习的基础,能够学习更有效的表示,以便发现和测量无标签数据点之间的相似性。
常用的半监督学习方法包括:
- 一致性正则化:假设神经网络的随机性或数据增强不会改变输入样本的真实标签,如$\Pi$-Model, Temporal Ensembling, Mean Teacher, VAT, ICT, UDA。
- 伪标签:根据当前模型的最大预测概率为无标签样本指定假标签,如Label Propagation, Confirmation Bias, Noisy Student, Meta Pseudo Label。
- 一致性正则化+伪标签:既构造无标签样本的伪标签,又同时建立监督损失和无监督损失,如MixMatch, ReMixMatch, FixMatch, DivideMix。
1. 一致性正则化 Consistency Regularization
一致性正则化(Consistency Regularization)也称为一致性训练(Consistency Training),是假设神经网络的随机性或数据增强不会改变输入样本的真实标签,并可以基于此构造一致性正则化损失\(\mathcal{L}_u\)。

⚪ $\Pi$-Model
$\Pi$-Model的无监督损失旨在最小化一个数据样本两次经过同一个带随机变换(如数据增强或dropout)的网络后预测结果的差异:
\[\mathcal{L}_u^{\Pi} = \sum_{x \in \mathcal{D}} \text{Dist}[f_{\theta}(x),f_{\theta}'(x)]\]
⚪ Temporal Ensembling
时序集成对每个数据样本$x$的预测结果$f_{\theta}(x)$存储一个指数滑动平均值\(\tilde{f}_{\theta}(x) \leftarrow \beta \tilde{f}_{\theta}(x) + (1-\beta)f_{\theta}(x)\);则无监督损失旨在最小化当前预测与滑动平均的差异:
\[\mathcal{L}_u^{TE} = \sum_{x \in \mathcal{D}} \text{Dist}[f_{\theta}(x),\tilde{f}_{\theta}(x)]\]
⚪ Mean Teacher
Mean Teacher存储模型参数的滑动平均值$\theta’\leftarrow \beta \theta’ + (1-\beta)\theta$作为教师模型,通过当前学生模型和教师模型的预测结果构造无监督损失。
\[\mathcal{L}_u^{MT} = \sum_{x \in \mathcal{D}} \text{Dist}[f_{\theta}(x),f_{\theta'}(x)]\]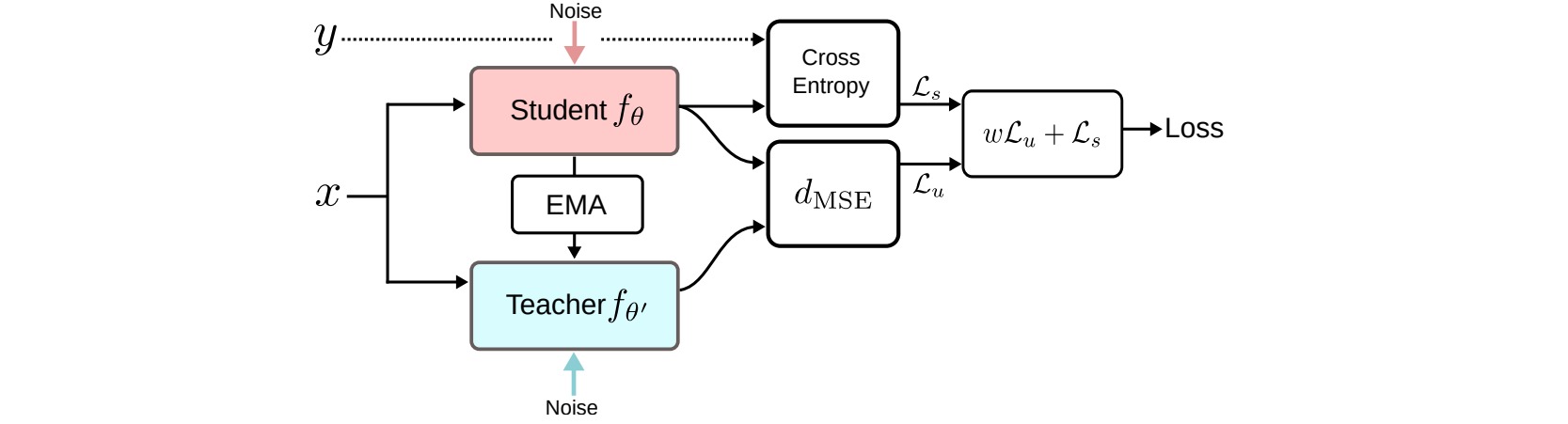
⚪ Virtual Adversarial Training (VAT)
虚拟对抗训练把对抗训练的思想引入半监督学习:构造当前样本的攻击噪声$r$,则无监督损失旨在最小化引入噪声$r$前后模型预测结果的差异:
\[\begin{aligned} r &= \mathop{\arg \max}_{||r|| \leq \epsilon} \text{Dist}[\text{sg}(f_{\theta}(x)),f_{\theta}(x+r)] \\ \mathcal{L}_u^{VAT} &= \sum_{x \in \mathcal{D}} \text{Dist}[\text{sg}(f_{\theta}(x)),f_{\theta}(x+r)] \end{aligned}\]⚪ Interpolation Consistency Training (ICT)
插值一致性训练通过mixup构造插值样本进行一致性预测,则无监督损失旨在最小化插值样本的预测结果和预测结果的插值之间的差异:
\[\mathcal{L}_u^{ICT} = \sum_{(x_i,x_j) \in \mathcal{D}} \text{Dist}[f_{\theta}(\lambda x_i + (1-\lambda) x_j),\lambda f_{\theta'}(x_i) + (1-\lambda) f_{\theta'}(x_j)]\]其中$\theta’$是$\theta$的滑动平均值。

⚪ Unsupervised Data Augmentation (UDA)
无监督数据增强采用先进的数据增强策略生成噪声样本\(\hat{x}\),并采用以下技巧:丢弃预测置信度低于阈值$\tau$的样本;在softmax中引入温度系数$T$;训练一个分类器预测域标签,并保留域内分类置信度高的样本。
\[\mathcal{L}_u^{UDA} = \sum_{x \in \mathcal{D}} \Bbb{I} [\mathop{\max}_c f_{\theta}^c(x) > \tau] \cdot \text{Dist}[\text{sg}(f_{\theta}(x;T)),f_{\theta}(\hat{x})]\]
2. 伪标签 Pseudo Label
伪标签(pseudo label)方法是指根据当前模型的最大预测概率为无标签样本指定假标签,然后通过监督学习方法同时训练有标签和无标签样本。
伪标签等价于熵正则化(Entropy Regularization),即最小化无标签样本的类别概率的条件熵以实现类别间的低密度分离。模型预测的类别概率是类别间重叠(class overlap)的一种测度,最小化其熵等价于减少不同类别的重叠。下图表明在训练过程中引入伪标签样本后,学习到的特征空间会更加分离。

通常用于生成伪标签的模型称为教师(Teacher),通过伪标签样本进行学习的模型称为学生(Student)。使用伪标签进行训练的过程是一种迭代过程。
⚪ Label Propagation
标签传播(Label Propagation)通过特征嵌入构造样本之间的相似图,然后把有标签样本的标签传播到无标签样本,传播权重正比于图中的相似度得分。

⚪ Confirmation Bias
确认偏差(Confirmation bias)是指教师网络可能会提供错误的伪标签,可能会导致学生网络对这些错误标签过拟合。为了缓解确认偏差问题,可以对样本及其软标签应用mixup;并在训练时对有标签样本进行过采样。
⚪ Noisy Student
Noisy Student首先使用有标记数据集训练一个教师网络,通过教师网络构造无标签数据的伪标签;然后通过全部数据训练一个更大的学生网络,训练过程中引入噪声干扰;最后将训练好的学生网络作为新的教师网络,并重复上述过程。

⚪ Meta Pseudo Label
元伪标签根据学生网络在标注数据集上的反馈表现持续地调整教师网络。记教师网络和学生网络的参数分别为$\theta_T,\theta_S$,则元伪标签的目标函数为:
\[\begin{aligned} \mathop{\min}_{\theta_T} \mathcal{L}_s(\theta_S(\theta_T&)) = \mathop{\min}_{\theta_T} \sum_{(x^l,y) \in \mathcal{X}} \text{CE}[y,f_{\theta_S(\theta_T)}(x^l)] \\ \text{where} \quad \theta_S(\theta_T) &= \mathop{\arg \min}_{\theta_S} \mathcal{L}_u(\theta_S,\theta_T) \\ & = \mathop{\arg \min}_{\theta_S} \sum_{x^u \in \mathcal{U}} \text{CE}[f_{\theta_T}(x),f_{\theta_S}(x)] \end{aligned}\]
3. 一致性正则化+伪标签
在半监督学习中可以结合一致性正则化和伪标签方法:既构造无标签样本的伪标签,又同时建立监督损失和无监督损失。
⚪ MixMatch
MixMatch针对每个无标签样本生成$K$个数据增强的样本\(\overline{u}^{(k)},k=1,...,K\),然后通过预测结果的平均构造伪标签:\(\hat{y} = \frac{1}{K} \sum_{k=1}^K f_{\theta}(\overline{u}^{(k)})\)。在此基础上结合一致性正则化、熵最小化、MixUp增强以构造监督损失和无监督损失:
\[\begin{aligned} \mathcal{L}_s^{MM} &= \frac{1}{|\overline{\mathcal{X}}|} \sum_{(\overline{x},y) \in \overline{\mathcal{X}}} D[y,f_{\theta}(\overline{x})] \\ \mathcal{L}_u^{MM} &= \frac{1}{C|\overline{\mathcal{U}}|} \sum_{(\overline{u},\hat{y}) \in \overline{\mathcal{U}}} ||\hat{y},f_{\theta}(\overline{u})||_2^2 \end{aligned}\]
⚪ ReMixMatch
ReMixMatch引入了分布对齐和增强锚点。分布对齐是指把构造的伪标签的分布\(p(\hat{y})\)调整为更接近已标注样本的标签分布$p(y)$。增强锚点是指给定未标注样本$u$,首先通过较弱的数据增强生成一个样本锚点,然后通过$K$次较强增强的预测均值构造伪标签。

⚪ FixMatch
FixMatch通过较弱的数据增强生成未标注样本的伪标签,并且只保留具有较高置信度的预测结果。较对于监督损失,通过较弱的数据增强预测结果;对于无监督损失,通过较强的数据增强预测结果。
\[\begin{aligned} \mathcal{L}_s &= \frac{1}{|\mathcal{X}|} \sum_{(x,y) \in \mathcal{X}} D[y,f_{\theta}(\mathcal{A}_{\text{weak}}(x))] \\ \mathcal{L}_u &= \frac{1}{|\mathcal{U}|} \sum_{(u,\hat{y}) \in \mathcal{U}} \Bbb{I}[\max(\hat{y})\geq \tau] \cdot D[\hat{y},f_{\theta}(\mathcal{A}_{\text{strong}}(u))] \end{aligned}\]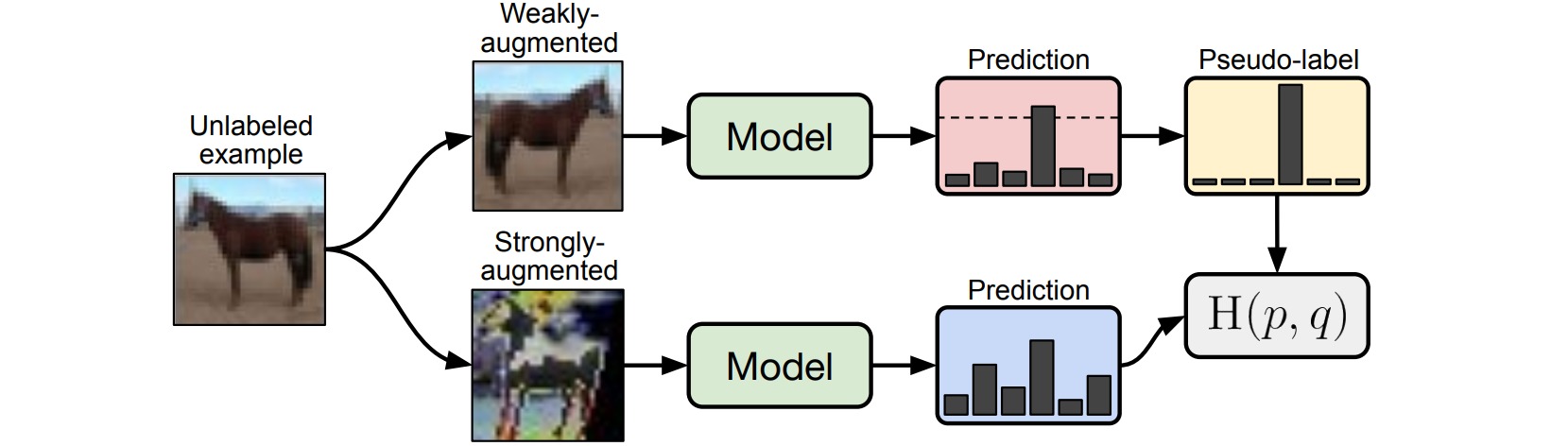
⚪ DivideMix
DivideMix把半监督学习和噪声标签学习结合起来,通过高斯混合模型把训练数据分成标注数据集和未标注数据集;同时训练了两个独立的网络,每个网络使用根据另一个网络预测结果划分的数据集;对于标注数据集,根据另一个网络划分数据集的概率$w_i$把真实标签$y_i$和多次数据增强后的预测结果均值\(\hat{y}_i\)进行加权;对于未标注数据集,平均两个网络的预测结果;之后应用MixMatch方法进行训练。

⭐ 参考文献
- Learning with not Enough Data Part 1: Semi-Supervised Learning(Lil’Log)一篇介绍半监督学习的博客。
- An Overview of Deep Semi-Supervised Learning:(arXiv2006)一篇深度半监督学习的综述。
- Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning:(arXiv1606)深度半监督学习的随机变换和扰动正则化。
- Temporal Ensembling for Semi-Supervised Learning:(arXiv1610)半监督学习的时序集成。
- Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results:(arXiv1703)加权平均一致性目标改进半监督深度学习。
- Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning:(arXiv1704)虚拟对抗训练:一种半监督学习的正则化方法。
- Interpolation Consistency Training for Semi-Supervised Learning:(arXiv1903)半监督学习的插值一致性训练。
- Unsupervised Data Augmentation for Consistency Training:(arXiv1904)一致性训练的无监督数据增强。
- Label Propagation for Deep Semi-supervised Learning:(arXiv1904)深度无监督学习的标签传播。
- MixMatch: A Holistic Approach to Semi-Supervised Learning:(arXiv1905)MixMatch:一种半监督学习的整体方法。
- Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning:(arXiv1908)深度无监督学习的伪标签和确认偏差。
- Self-training with Noisy Student improves ImageNet classification:(arXiv1911)通过噪声学生网络的自训练改进图像分类。
- ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring:(arXiv1911)ReMixMatch:通过分布对齐和增强锚点实现半监督学习。
- FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence:(arXiv2001)FixMatch:通过一致性和置信度简化半监督学习。
- DivideMix: Learning with Noisy Labels as Semi-supervised Learning:(arXiv2002)DivideMix:通过噪声标签实现半监督学习。
- Meta Pseudo Labels:(arXiv2003)元伪标签。


