FixMatch:通过一致性和置信度简化半监督学习.
FixMatch通过较弱的数据增强生成未标注样本的伪标签,并且只保留具有较高置信度的预测结果。较弱的数据增强和高置信度过滤都能够产生高质量的伪标签目标。对于监督损失,通过较弱的数据增强预测结果;对于无监督损失,通过较强的数据增强预测结果。
\[\begin{aligned} \mathcal{L}_s &= \frac{1}{|\mathcal{X}|} \sum_{(x,y) \in \mathcal{X}} D[y,f_{\theta}(\mathcal{A}_{\text{weak}}(x))] \\ \mathcal{L}_u &= \frac{1}{|\mathcal{U}|} \sum_{(u,\hat{y}) \in \mathcal{U}} \Bbb{I}[\max(\hat{y})\geq \tau] \cdot D[\hat{y},f_{\theta}(\mathcal{A}_{\text{strong}}(u))] \end{aligned}\]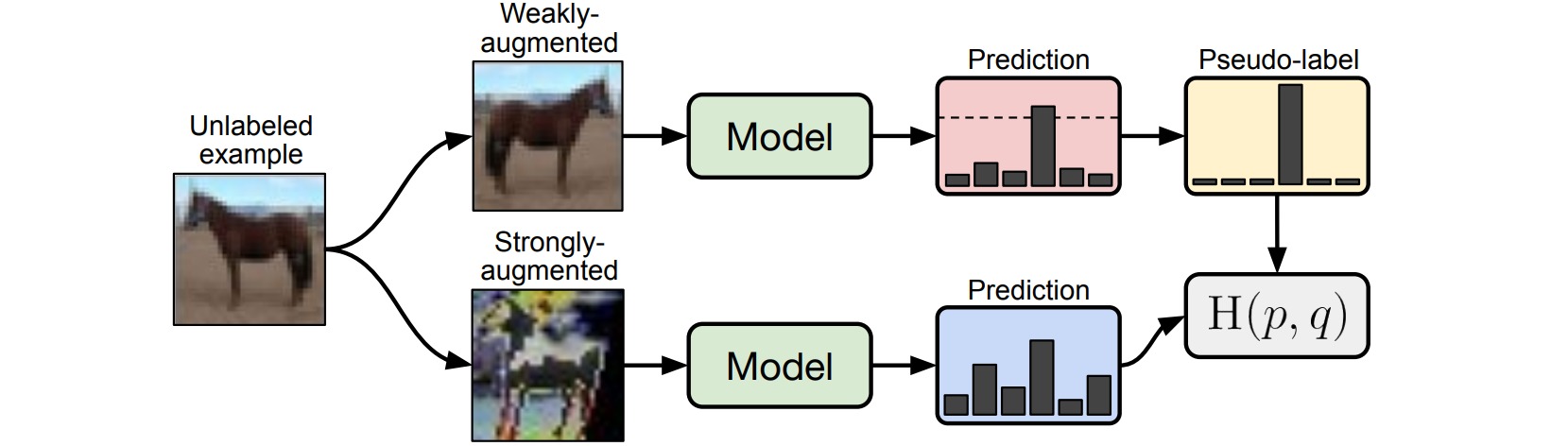
较弱的数据增强选用标准的翻转和平移变换(flip-and-shift)。较强的数据增强选用AutoAugment, Cutout, RandAugment, CTAugment。
不同半监督学习方法在图像分类任务上的表现如下:

FixMatch的消融实验表明:
- 当应用预测置信度$\tau$过滤时,对预测分布引入温度$T$进行锐化并没有显著影响;
- Cutout和CTAugment作为较强的数据增强方法是必要的;
- 在生成伪标签时,使用较强的数据增强代替较弱的数据增强,则模型在训练早期就会发散;如果不使用数据增强,则模型容易过拟合;
- 在预测未标注样本的伪标签时,采用较弱的数据增强代替较强的数据增强将会导致不稳定的表现。


