一致性训练的无监督数据增强.
无监督数据增强 (Unsupervised Data Augmentation, UDA)旨在使模型对一个无标签样本及其增强样本预测相同的输出,重点关注增强噪声的质量将会如何影响半监督学习方法的一致性训练表现。UDA采用比较先进的数据增强策略生成有意义和高效的噪声样本,而好的增强策略应能提供有效的(不改变样本标签)、多样性的噪声,并引入有目标的归纳偏置。

在计算无监督损失时,UDA采用了以下技巧:
- 低置信度遮挡(low confidence masking):丢弃预测置信度低于阈值$\tau$的样本;
- 锐化预测分布(sharpening prediction distribution):在softmax中引入温度系数$T$;
- 域内数据过滤(in-domain data filtration):为了在域外数据集中提取更多域内数据,训练一个分类器预测域标签,并保留域内分类置信度高的样本。
UDA的损失函数为:
\[\mathcal{L}_u^{UDA} = \sum_{x \in \mathcal{D}} \Bbb{I} [\mathop{\max}_c f_{\theta}^c(x) > \tau] \cdot \text{D}[\text{sg}(f_{\theta}(x;T)),f_{\theta}(\hat{x})]\]其中\(\hat{x}\)是应用数据增强的样本,\(\text{sg}(\cdot)\)表示不计算梯度,\(\Bbb{I}\)是示性函数,\(\text{D}\)是距离函数,对于分类任务常取KL散度;温度$T$用于调整softmax计算:
\[f_{\theta}^i(x;T) = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)}\]对于图像任务,UDA采用RandAugment,该方法随机均匀地从PIL提供的图像增强策略中采样增强方式,不需要学习或优化过程,因此是一种高效的自动增强策略。

在CIFAR-10和SVHN分类数据集上,监督学习的Wide-ResNet-28-2和PyramidNet分别报告了$5.4$和$2.7$的错误率,而半监督学习方法的错误率为:
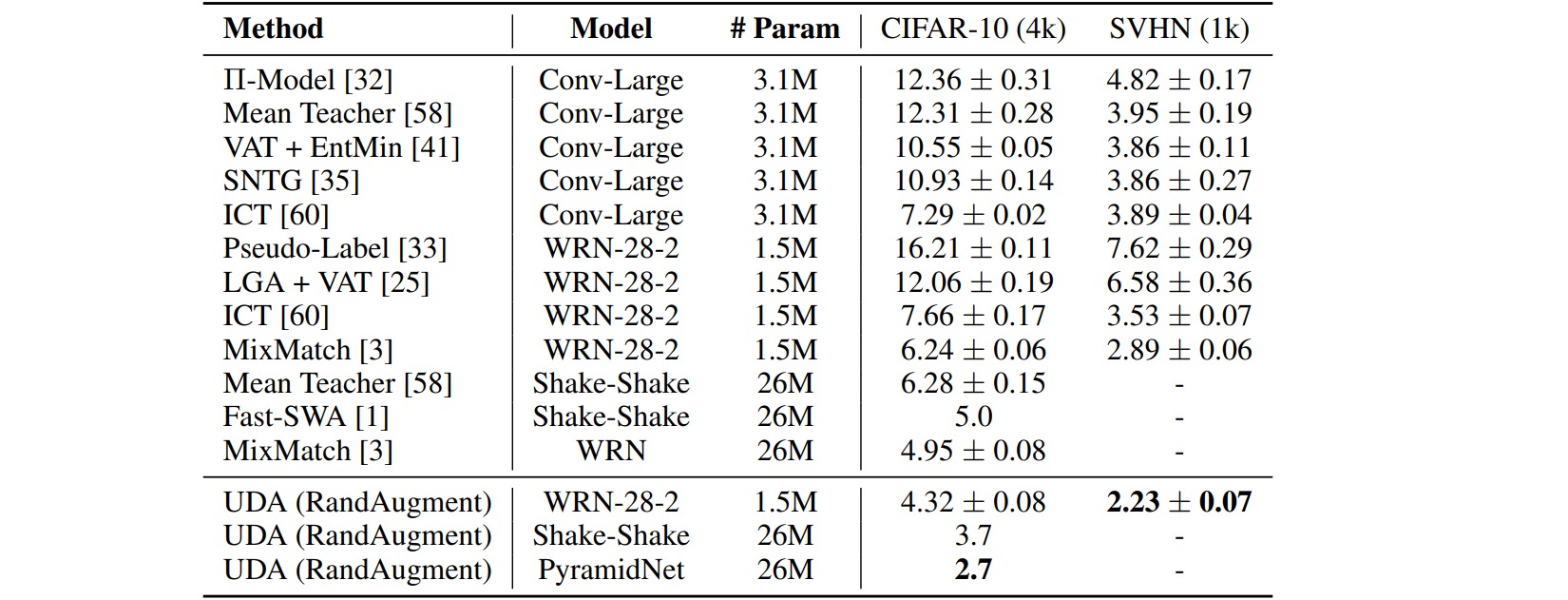
对于语言任务,UDA采用反向翻译(back-translation)和基于TF-IDF的单词替换。反向翻译保留了高级语义信息但不会保持精确的单词,TF-IDF词替换丢弃了具有较低TF-IDF得分的信息量较小的单词。

结果表明UDA能够作为语言领域中迁移学习和表示学习的补充:



