Self-Attention Mechanism in Convolutional Neural Networks.
卷积神经网络中的自注意力(Self-Attention)机制表现为非局部滤波(non-local filtering)操作,其实现过程与Seq2Seq模型的自注意力机制类似。
标准的卷积层是一种局部滤波操作,其输出特征上的任意位置是由对应输入特征的一个邻域构造的,只能捕捉局部特征之间的关系。而自注意力机制通过计算任意两个位置之间的关系直接捕捉远程依赖,而不用局限于相邻点,相当于构造了一个和特征图尺寸一样大的卷积核,从而可以捕捉更多信息。

在卷积网络的自注意力机制中,首先构造输入特征$x$的键特征$f(x)$, 查询特征$g(x)$和值特征$h(x)$;然后应用点积注意力构造自注意力特征图:
\[\alpha_{i} = \text{softmax}\left(f(x_i)^Tg(x_j)\right) =\frac{e^{f(x_i)^Tg(x_j)}}{\sum_j e^{f(x_i)^Tg(x_j)}}\]在计算输出位置$i$的响应$y_i$时,考虑所有输入值特征$h(x_j)$的加权:
\[y_i= \sum_{j}^{} \alpha_{j}h(x_j) = \sum_{j}^{} \frac{e^{f(x_i)^Tg(x_j)}}{\sum_k e^{f(x_i)^Tg(x_k)}} h(x_j)\]上式可以被写作更一般的形式:
\[y_i=\frac{1}{C\left(x_i\right)} \sum_j f\left(x_i, x_j\right) h\left(x_j\right)\]其中相似度函数$f(\cdot,\cdot)$计算两个特征位置$x_i,x_j$的相似程度,输出被权重因子$C(x_i)$归一化。注意到当相似度函数取Embedded Gaussian函数:
\[f\left(\mathbf{x}_i, \mathbf{x}_j\right)=e^{\theta\left(\mathbf{x}_i\right)^T \phi\left(\mathbf{x}_j\right)}\]此时自注意力机制等价于上述query-key-value形式。

自注意力机制的实现可参考:
class SelfAttention(nn.Module):
def __init__(self, in_channels):
super(SelfAttention, self).__init__()
self.f = nn.Conv2d(in_channels, in_channels, 1)
self.g = nn.Conv2d(in_channels, in_channels, 1)
self.h = nn.Conv2d(in_channels, in_channels, 1)
self.o = nn.Conv2d(in_channels, in_channels, 1)
def forward(self, x):
b, c, h, w = x.shape
fx = self.f(x).view(b, c, -1) # [b, c, hw]
fx = fx.permute(0, 2, 1) # [b, hw, c]
gx = self.g(x).view(b, c, -1) # [b, c, hw]
attn = torch.matmul(fx, gx) # [b, hw, hw]
attn = F.softmax(attn, dim=2) # 按行归一化
hx = self.h(x).view(b, c, -1) # [b, c, hw]
hx = hx.permute(0, 2, 1) # [b, hw, c]
y = torch.matmul(attn, hx) # [b, hw, c]
y = y.permute(0, 2, 1).contiguous() # [b, c, hw]
y = y.view(b, c, h, w)
return self.o(y)
卷积神经网络中的自注意力机制包括:
- 增强特征提取能力:Non-local Net, DANet, A^2-Net, AAConv, RNL, DMSANet, SAN, PSA, SNL。
- 降低计算复杂度:CCNet, GCNet, EMANet, ISANet, ANNNet, LightNL, NLSA, Hamburger。
(1)增强特征提取能力
⚪ Non-local Net
Non-Local Net设计了卷积网络中自注意力机制的基本结构。

⚪ Dual Attention Network (DANet)
DANet设计了Dual Attention,同时引入了沿空间维度和和通道维度的自注意力。

⚪ Double Attention Network (A^2-Net)
$A^2$-Net首先使用双线性池化提取特征的一系列描述子,然后使用注意力机制将这些特征描述子分配给特征的每个位置。
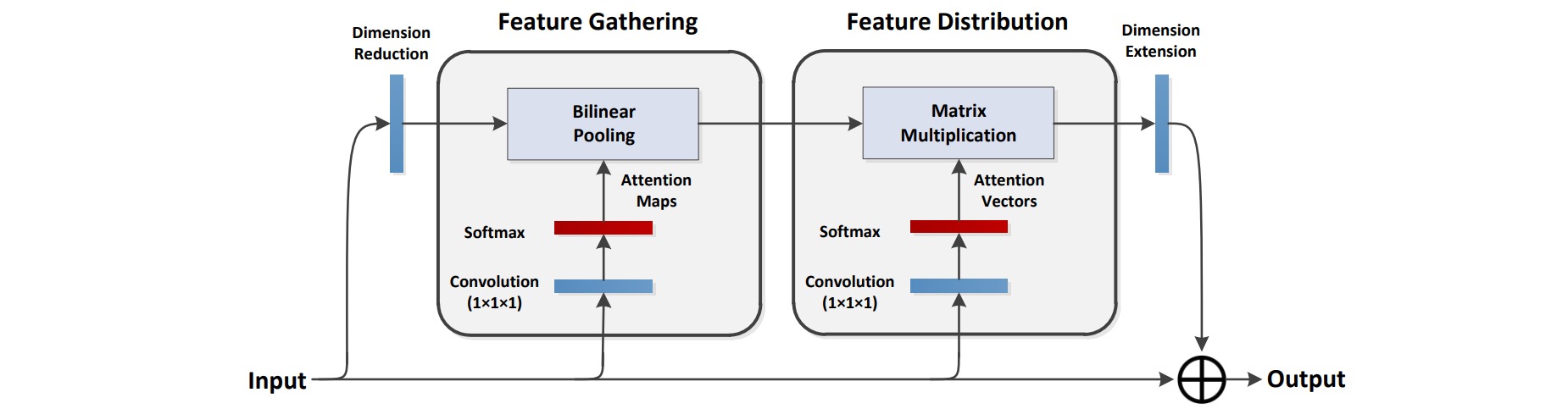
⚪ Attention Augmented Convolution (AAConv)
AAConv为自注意力机制引入了multi-head形式和相对位置编码,并且使用卷积层补充局部特征。

⚪ Region-based Non-local (RNL)
基于区域的non-local计算两个特征位置$x_i,x_j$的相似程度时,不仅仅与这两个点本身有关,还与其周边region有关。
\[y_i=\frac{1}{C\left(x_i\right)} \sum_j f\left( \theta(\mathcal{N}_i),\theta(\mathcal{N}_j)\right) x_j\]
⚪ Dual Multi Scale Attention Network (DMSANet)
DMSANet首先把特征按通道进行分组,并行地应用空间和特征自注意力机制,再通过注意力机制聚合特征。

⚪ Self-attention Network (SAN)
作者设计了两种self-attention形式:pairwise self-attention和patchwise self-attention。
\[\mathbf y_i = \sum\limits_{j\in \mathcal{R}(i)}\alpha(\mathbf x_i,\mathbf x_j) \odot \beta(\mathbf x_j) \\ \mathbf y_i = \sum\limits_{j\in \mathcal{R}(i)}\alpha(\mathbf{x}_{\mathcal{R}_{(i)}})_j \odot \beta(\mathbf x_j)\]
⚪ Polarized Self-Attention (PSA)
极化自注意力基于摄影中的极化滤波原理。先在某个方向(通道维度或空间维度)上对特征进行压缩,然后对损失的强度范围进行增强或者抑制。

⚪ Spectral Nonlocal (SNL)
SNL把自注意力机制建模为在全连接图上生成的一组图过滤器,基于切比雪夫滤波器和对称亲和矩阵设计了谱非局部模块:
\[\boldsymbol{Y}=\boldsymbol{X}+\mathcal{F}_s(\boldsymbol{A}, \boldsymbol{Z})=\boldsymbol{X}+\boldsymbol{Z}W_1+\boldsymbol{A}\boldsymbol{Z}W_2 \\ \text{s.t. } \boldsymbol{A} = \boldsymbol{D}^{-1/2}_{\hat{M}}\hat{M}\boldsymbol{D}^{-1/2}_{\hat{M}},\hat{M}=(M+M^T)/2\]
(2)降低计算复杂度
⚪ Criss-Cross Attention (CCNet)
CCNet设计了Criss-Cross Attention,计算一个点的横纵位置的attention信息,通过串行两个Criss-Cross attention模块间接与全图位置内的任意点进行注意力计算。

⚪ Global Context Network (GCNet)
GCNet设计了Global Context Block,通过query和key权重共享简化了attention map的构造,并且引入了通道注意力。

⚪ Expectation-Maximization Attention Network (EMANet)
EMANet通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制。

⚪ Interlaced Sparse Self-Attention (ISANet)
ISANet把特征图进行分块,先进行块内的self attention计算得到Long-range的attention;然后进行块之间计算self attention得到Short-range的attention。

⚪ Asymmetric Non-local Neural Network (ANNNet)
ANNNet通过Pyramid Pooling对Non-Local中的Key和Value进行采样以减少计算量。

⚪ Lightweight Non-Local Network (LightNL)
LightNL是为神经结构搜索设计的轻量级Non-Local模块,主要有三点差异:$Q,K,V$的生成去掉了$1\times 1$卷积、输出卷积替换为深度卷积、使用更小的特征图计算相关性。

⚪ Non-Local Sparse Attention (NLSA)
NLSA通过局部敏感哈希构造attention bucket,只对同一个attention bucket内的特征进行自注意力计算。

⚪ Hambuger
Hamburger模块通过将全局上下文建模问题转化为低秩恢复问题,并利用矩阵分解的优化算法设计网络架构。

⭐ 参考文献
- Non-local Neural Networks:(arXiv1711)非局部神经网络。
- Dual Attention Network for Scene Segmentation:(arXiv1809)场景分割的对偶注意力网络。
- A^2-Nets: Double Attention Networks:(arXiv1810)A^2-Net:双重注意力网络。
- CCNet: Criss-Cross Attention for Semantic Segmentation:(arXiv1811)CCNet:语义分割中的交叉注意力机制。
- GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond:(arXiv1904)GCNet:结合非局部神经网络和通道注意力。
- Attention Augmented Convolutional Networks:(arXiv1904)注意力增强卷积网络。
- Expectation-Maximization Attention Networks for Semantic Segmentation:(arXiv1907)EMANet: 语义分割的期望最大化注意力网络。
- Interlaced Sparse Self-Attention for Semantic Segmentation:(arXiv1907)ISANet:语义分割的交错稀疏自注意力网络。
- Asymmetric Non-local Neural Networks for Semantic Segmentation:(arXiv1908)ANNNet:语义分割的非对称非局部神经网络。
- Neural Architecture Search for Lightweight Non-Local Networks:(arXiv2004)轻量级非局部网络的神经结构搜索。
- Exploring Self-attention for Image Recognition:(arXiv2004)探索图像识别的自注意力机制。
- Region-based Non-local Operation for Video Classification:(arXiv2007)为视频分类设计的基于区域的非局部网络。
- DMSANet: Dual Multi Scale Attention Network:(arXiv2106)DMSANet: 对偶多尺度注意力网络。
- Polarized Self-Attention: Towards High-quality Pixel-wise Regression:(arXiv2107)极化自注意力: 面向高质量像素级回归。
- Unifying Nonlocal Blocks for Neural Networks:(arXiv2108)统一神经网络的非局部模块。
- Image Super-Resolution with Non-Local Sparse Attention:(CVPR2021)通过非局部稀疏注意力实现图像超分辨率。
- Is Attention Better Than Matrix Decomposition?:(arXiv2109)注意力比矩阵分解更好吗?


