ANNNet:语义分割的非对称非局部神经网络.
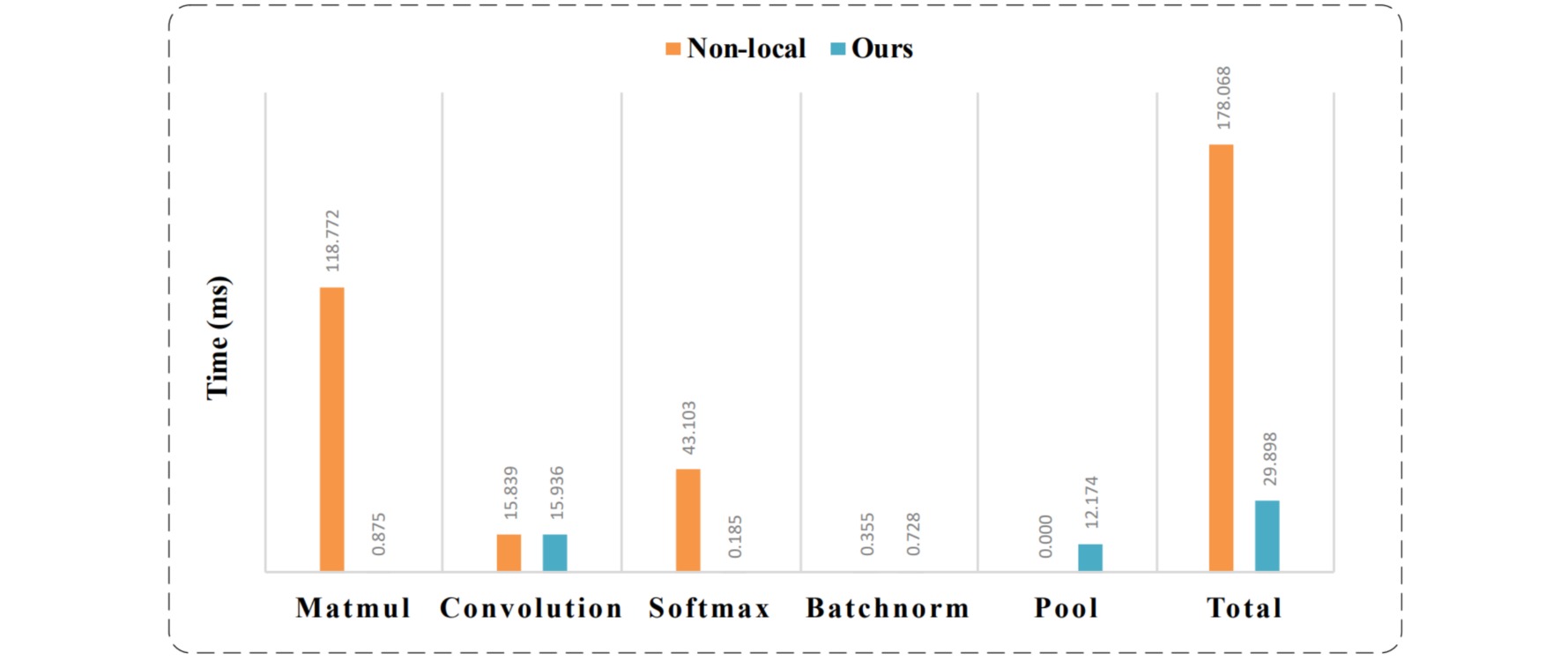
Non-Local Net引入了自注意力机制来建立长距离依赖,可以有效的提升分割效果,弥补网络感受野大小不足。然而Non-Local的方式虽然能够建立空间任意两点的信息,但是计算量十分大,导致模型运行很慢。
为了减少Non-Local的计算量,本文提出了Asymmetric Non-local Block,在计算Key和Value上通过sample的方式,减少了Key和Value的大小,从而在Matmul和Softmax操作上大大减少了计算量(这两个操作正好是Non-Local操作耗费时间较长的操作模块)。

ANNNet结构如图,其中主干网络主要为ResNet,ANN网络的亮点主要是:
- 通过Pyramid Pooling Module(PPM)来实现sample,减少Non-Local的计算量。
- 提出AFNP和APNB模块用来减少计算开销和融合特征,提升分割准确率。
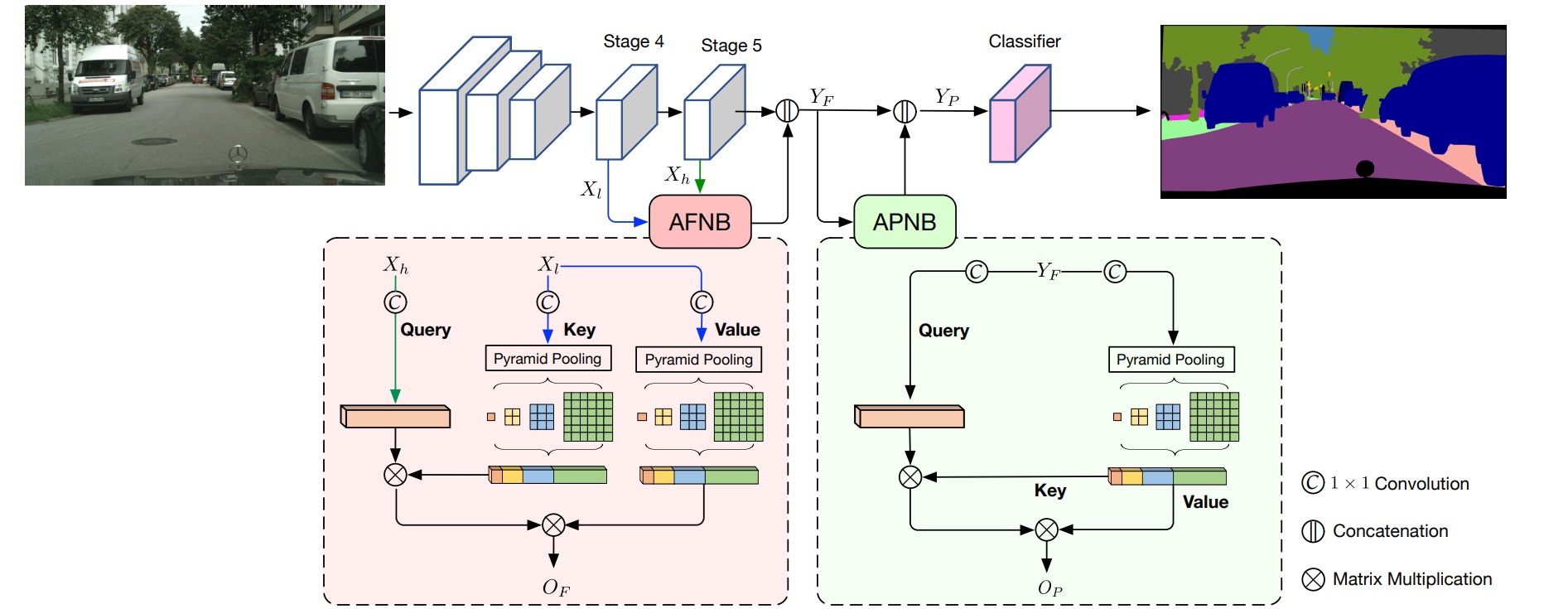
⚪ AFNB(Asymmetric Fusion Non-local Block)
AFNB结构与Non-Local结构的区别在于,AFNB结构计算Key和Value时,通过Pyramid Pooling Module(PPM)进行sample。而PPM结构最早由PSPNet提出,在这里,作者将Key和Value的特征图进行池化采样,池化大小为$[1, 3, 6, 8]$,输出为:$1×1$,$3×3$,$6×6$,$8×8$,展平链接后大小正好为$110$。
对于AFNB模块的计算公式,有主干网络stage4的输出$X_l$和stage5的输出$X_h$,对于Query、Key、Value和输出Out的计算:
\[\begin{aligned} &\text { query }=\mathrm{f}_{\mathrm{q}}\left(\mathrm{X}_{\mathrm{h}}\right)\\ &\text { key }=\Phi_{\text {sample }}\left(\mathrm{f}_{\mathrm{k}}\left(\mathrm{X}_{\mathrm{l}}\right)\right)\\ &\text { value }=\Phi_{\text {sample }} \left(\mathrm{f}_{\mathrm{v}}\left(\mathrm{X}_{\mathrm{l}}\right)\right)\\ &\text { Out }=\mathrm{f}_{\text {out }}(\text { SoftMax }(\text { query } \odot \text { key }) \odot(\text { value })) \end{aligned}\]class PPMModule(nn.ModuleList):
def __init__(self, pool_sizes=[1,3,6,8]):
super(PPMModule, self).__init__()
for pool_size in pool_sizes:
self.append(
nn.Sequential(
nn.AdaptiveAvgPool2d(pool_size)
)
)
def forward(self, x):
out = []
b, c, _, _ = x.size()
for index, module in enumerate(self):
out.append(module(x))
return torch.cat([output.view(b, c, -1) for output in out], -1)
class AFNPBlock(nn.Module):
def __init__(self, in_channels, key_channels, value_channels, pool_sizes=[1,3,6,8]):
super(AFNPBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = in_channels
self.key_channels = key_channels
self.value_channels = value_channels
# query 接受的是stage5的Xh 所以这里的是in_channels=2048
self.Conv_query = nn.Sequential(
nn.Conv2d(self.in_channels, self.key_channels, 1),
nn.BatchNorm2d(self.key_channels),
nn.ReLU()
)
# key 和 value 接受的是stage4的输出Xl 这里的in_channels//2为1024
self.Conv_key = nn.Sequential(
nn.Conv2d(self.in_channels // 2, self.key_channels, 1),
nn.BatchNorm2d(self.key_channels),
nn.ReLU()
)
self.Conv_value = nn.Conv2d(self.in_channels // 2, self.value_channels, 1)
self.ConvOut = nn.Conv2d(self.value_channels, self.out_channels, 1)
self.ppm = PPMModule(pool_sizes)
# 给ConvOut初始化为0
nn.init.constant_(self.ConvOut.weight, 0)
nn.init.constant_(self.ConvOut.bias, 0)
def forward(self, low_feats, high_feats):
# low_feats = stage4 high_feats = stage5
b, c, h, w = high_feats.size()
# value = [batch, -1, value_channels] // 这里-1由pool_sizes决定,目前的设置为110=1+3*3+6*6+8*8
value = self.ppm(self.Conv_value(low_feats)).permute(0, 2, 1)
# key = [batch, key_channels, -1] // 这里-1由pool_sizes决定,目前的设置为110=1+3*3+6*6+8*8
key = self.ppm(self.Conv_key(low_feats))
# query = [batch, key_channels, h*w] -> [batch, h*w, key_channels]
query = self.Conv_query(high_feats).view(b, self.key_channels, -1).permute(0, 2, 1)
# Concat_QK = [batch, h*w, 110]
Concat_QK = torch.matmul(query, key)
Concat_QK = (self.key_channels ** -.5) * Concat_QK
Concat_QK = F.softmax(Concat_QK, dim=-1)
# Aggregate_QKV = [batch, h*w, Value_channels]
Aggregate_QKV = torch.matmul(Concat_QK, value)
# Aggregate_QKV = [batch, value_channels, h*w]
Aggregate_QKV = Aggregate_QKV.permute(0, 2, 1).contiguous()
# Aggregate_QKV = [batch, value_channels, h*w] -> [batch, value_channels, h, w]
Aggregate_QKV = Aggregate_QKV.view(b, -1, h, w)
# Conv out
Aggregate_QKV = self.ConvOut(Aggregate_QKV)
return Aggregate_QKV
⚪ APNB(Asymmetric Pyramid Non-local Block)
APNB的结构同样类似于AFNB,Value计算同样通过一个卷积和一个Pyramid Pooling进行sample;需要注意的是这里计算Query和Key的卷积操作权重共享,也就是初步计算出来的Query和Key是等同的,接着Key再输入到Pyramid Pooling中进行sample。对应公式为:
\[\begin{aligned} &\text { query }=f_q\left(Y_F\right)\\ &\text { key }=\Phi_{\text {sample }}\left(\mathrm{f}_{\mathrm{q}}\left(\mathrm{Y}_{\mathrm{F}}\right)\right)\\ &\text { value }=\Phi_{\text {sample }} f_{\mathrm{v}}\left(Y_F\right)\\ &\text { Out }=\mathrm{f}_{\text {out }}(\text { SoftMax }(\text { query } \odot \text { key }) \odot(\text { value })) \end{aligned}\]class APNBBlock(nn.Module):
def __init__(self, in_channels, out_channels, key_channels, value_channels, pool_sizes=[1, 3, 6, 8]):
super(APNBBlock, self).__init__()
# Generally speaking, here, in_channels==out_channels and key_channels==value_channles
self.in_channels = in_channels
self.out_channles = out_channels
self.value_channels = value_channels
self.key_channels = key_channels
self.pool_sizes = pool_sizes
self.Conv_Key = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(self.key_channels),
nn.ReLU()
)
# 这里Conv_Query 和 Conv_Key权重共享,也就是计算出来的query和key是等同的
self.Conv_Query = self.Conv_Key
self.Conv_Value = nn.Conv2d(self.in_channels, self.value_channels, 1)
self.Conv_Out = nn.Conv2d(self.value_channels, self.out_channles, 1)
nn.init.constant_(self.Conv_Out.weight, 0)
nn.init.constant_(self.Conv_Out.bias, 0)
self.ppm = PPMModule(pool_sizes=self.pool_sizes)
def forward(self, x):
b, _, h, w = x.size()
# value = [batch, 110, value_channels]
value = self.ppm(self.Conv_Value(x)).permute(0, 2, 1)
# query = [batch, h*w, key_channels]
query = self.Conv_Query(x).view(b, self.key_channels, -1).permute(0, 2, 1)
# key = [batch, key_channels, 110] where 110 = sum([s*2 for s in pool_sizes]) 1 + 3*2 + 6*2 + 8*2
key = self.ppm(self.Conv_Key(x))
# Concat_QK = [batch, h*w, 110]
Concat_QK = torch.matmul(query, key)
Concat_QK = (self.key_channels ** -.5) * Concat_QK
Concat_QK = F.softmax(Concat_QK, dim=-1)
# Aggregate_QKV = [batch, h*w, Value_channels]
Aggregate_QKV = torch.matmul(Concat_QK, value)
# Aggregate_QKV = [batch, value_channels, h*w]
Aggregate_QKV = Aggregate_QKV.permute(0, 2, 1).contiguous()
# Aggregate_QKV = [batch, value_channels, h*w] -> [batch, value_channels, h, w]
Aggregate_QKV = Aggregate_QKV.view(b, -1, h, w)
# Conv out
Aggregate_QKV = self.Conv_Out(Aggregate_QKV)
return Aggregate_QKV
⚪ ANNNet
ANNNet通过Pyramid Pooling对Non-Local中的Key和Value进行采样以减少计算量;分别提出AFNB和APNB两个非对称结构用于特征融合和提高分割准确率。
class asymmetric_non_local_network(nn.Sequential):
def __init__(self, num_classes=2):
super(asymmetric_non_local_network, self).__init__()
self.num_classes = num_classes
self.backbone = ResNet.resnet50(replace_stride_with_dilation=[1,2,4])
# AFNB and APNB
self.fusion = AFNPBlock(in_channels=2048, value_channels=256, key_channels=256, pool_sizes=[1,3,6,8])
self.APNB = APNBBlock(in_channels=512, out_channels=512, value_channels=256, key_channels=256, pool_sizes=[1,3,6,8])
# extra added layers
self.context = nn.Sequential(
nn.Conv2d(2048, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
self.APNB
)
self.cls = nn.Conv2d(512, self.num_classes, kernel_size=1, stride=1, padding=0, bias=True)
def forward(self, x_):
x = self.backbone(x_)
x = self.fusion(x[-2], x[-1])
x = self.context(x)
x = self.cls(x)
x = F.interpolate(x, size=(x_.size(2), x_.size(3)), mode="bilinear", align_corners=True)
return x

