Attention Mechanism in Convolutional Neural Networks.
卷积神经网络中的注意力机制(Attention Mechanism)表现为在特征的某个维度上计算相应统计量,并根据所计算的统计量对该维度上的每一个元素赋予不同的权重,用以增强网络的特征表达能力。
class Attention(nn.Module):
def __init__(self, ):
super(Attention, self).__init__()
self.layer() = nn.Sequential()
def forward(self, x):
b, c, h, w = x.size()
w = self.layer(x) # 在某特征维度上计算权重
return x * w.expand_as(x) # 对特征进行加权
卷积层的特征维度包括通道维度$C$和空间维度$H,W$,因此注意力机制可以应用在不同维度上:
- 通道注意力(Channel Attention):SENet, CMPT-SE, GENet, GSoP, SRM, SKNet, DIA, ECA-Net, SPANet, FcaNet, EPSA, TSE, NAM
- 空间注意力(Spatial Attention):Residual Attention Network, SGE, ULSAM
- 通道+空间:(并联)scSE, BAM, SA-Net, Triplet Attention; (串联)CBAM; (融合)SCNet, Coordinate Attention, SimAM
- 其他注意力:DCANet, WE, ATAC, AFF, AW-Convolution, BA^2M, Interflow, CSRA
1. 通道注意力
⚪ Squeeze-and-Excitation Network (SENet)
SENet对输入特征沿着通道维度计算一阶统计量(全局平均池化),然后通过带有瓶颈层的全连接层学习通道之间的相关性。

⚪ Competitive Squeeze and Excitation (CMPT-SE)
CMPT-SE通过残差流和恒等流进行竞争建模,以共同决定通道注意力分布,使得恒等流能自主参与对特征的权重调控。

⚪ Gather-Excite Network (GENet)
GENet对输入特征使用通道卷积提取每个局部空间位置的统计量,然后将其进行缩放还原回原始尺寸,并通过带有瓶颈层的$1\times 1$卷积层学习通道之间的相关性。

⚪ Global Second-order Pooling (GSoP)
GSoP对输入特征沿着通道维度进行降维后,计算通道之间的协方差矩阵(二阶统计量),然后通过按行卷积和全连接层学习通道之间的相关性。

⚪ Style-based Recalibration Module (SRM)
SRM首先通过风格池化将每个特征图的通道级统计信息(均值和标准差)用作风格特征,然后通过风格集成来估计每个通道的重校准权重。

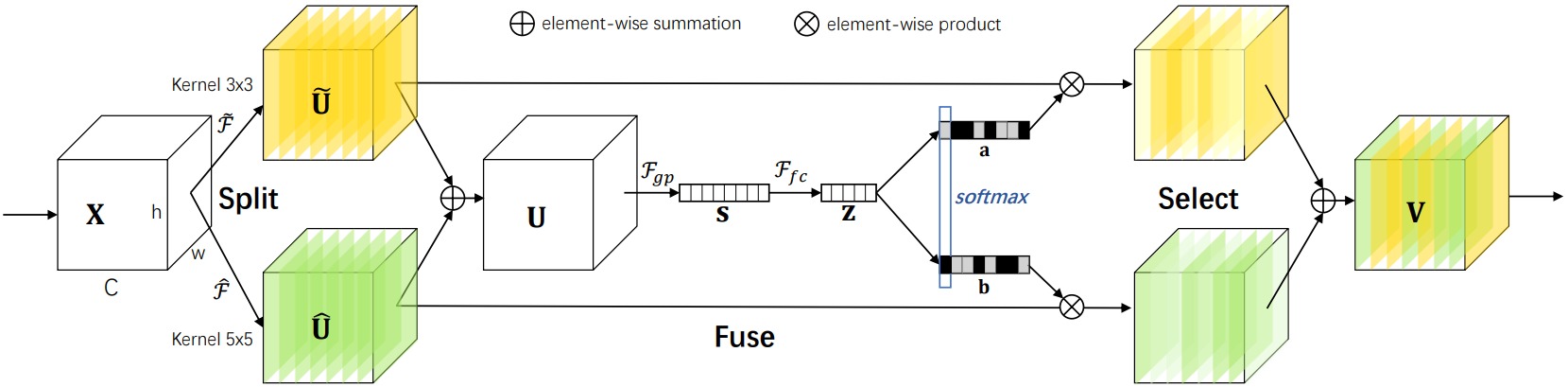
⚪ Selective Kernel Network (SKNet)
SKNet首先同时使用不同大小的卷积核作为不同的分支提取特征,然后通过通道注意力机制融合这些特征,以获得不同感受野的信息。
⚪ Dense-and-Implicit-Attention (DIA)
DIA在不同的网络层共享同一个注意力模块,以鼓励分层信息的集成。具体地通过LSTM共享模块参数并捕获长距离依赖性。

⚪ Efficient Channel Attention (ECA-Net)
ECA-Net通过把通道注意力模块中的全连接层替换为一维卷积层,实现了轻量级的通道注意力。

⚪ Spatial Pyramid Attention (SPANet)
SPANet在4×4、2×2和1×1三个尺度上对输入特征图进行自适应平均池化,然后将三个输出特征连接并调整为一维向量以生成通道注意力分布。

⚪ Multi-Spectral Channel Attention (FcaNet)
FcaNet首先选择应用离散余弦变换后Top-n个性能最佳的频率分量标号,然后把输入特征沿通道划分为$n$等份,对每份计算其对应的DCT频率分量,并与对应的特征分组相乘。

⚪ Efficient Pyramid Split Attention (EPSA)
EPSA首先根据拆分和拼接模块生成多尺度的特征图,通过通道注意力机制提取不同尺度特征图的注意力向量,利用Softmax重新校准不同尺度的注意力向量,并对多尺度特征图进行加权。

⚪ Tiled Squeeze-and-Excite (TSE)
TSE把通道注意力的全局平均池化替换成更小的池化核,为针对数据流设计的AI加速器中的元素乘法引入更小的缓冲区。

⚪ Normalization-based Attention Module (NAM)
NAM对输入特征应用Batch Norm,并通过Batch Norm中可学习的尺度变换参数$\gamma$构造注意力分布。

2. 空间注意力
⚪ Residual Attention Network
Residual Attention Module在卷积模块中增加侧分支提取高层特征,高层特征的激活位置能够反映感兴趣的区域;然后对高层特征进行上采样,并与卷积特征进行加权。

⚪ Spatial Group-wise Enhance (SGE)
SGE把输入特征进行分组,对每组特征在空间维度上与其全局平均池化特征做点积后进行标准化,然后通过学习两个仿射参数(缩放和偏移)实现空间注意力。

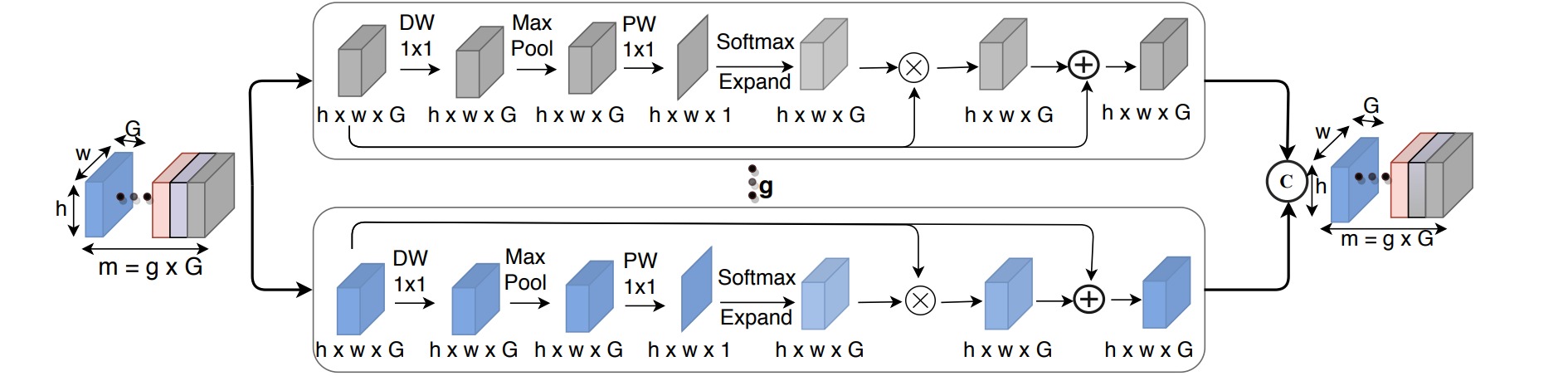
⚪ Ultra-Lightweight Subspace Attention Module (ULSAM)
ULSAM对输入特征进行分组,对每组特征通过深度可分离卷积构造空间注意力分布,进行空间上的重新校准;最后把所有特征连接作为输出特征。
3.1 并联通道+空间注意力
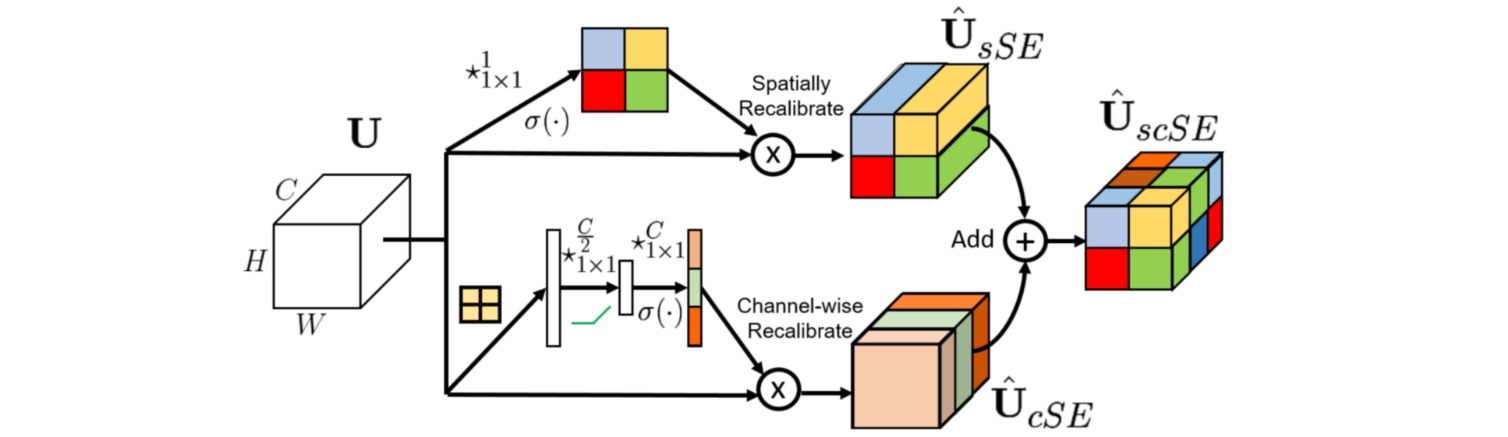
⚪ Concurrent Spatial and Channel Squeeze & Excitation (scSE)
scSE通过并联使用通道注意力和空间注意力增强特征的表达能力。通道注意力通过全局平均池化和全连接层实现;空间注意力通过$1\times 1$卷积实现。
⚪ Bottleneck Attention Module (BAM)
BAM通过并联使用通道注意力和空间注意力增强特征的表达能力。通道注意力通过全局平均池化和全连接层实现;空间注意力通过$1\times 1$卷积和空洞卷积实现。

⚪ Shuffle Attention (SA-Net)
SA-Net把输入特征沿通道维度拆分为$g$组,对每组特征再次沿通道平均拆分后应用并行的通道注意力和空间注意力,之后集成所有特征,并通过通道置换操作进行不同通道间的交互。

⚪ Triplet Attention
Triplet Attention分别沿着通道维度、高度维度和宽度维度应用注意力机制,其中输入特征可以通过维度交换构造;统计函数$Z$选用全局最大池化和全局平均池化。

3.2 串联通道+空间注意力
⚪ Convolutional Block Attention Module (CBAM)
CBAM通过串联使用通道注意力和空间注意力增强特征的表达能力,每种注意力机制构造两个一阶统计量(全局最大池化和全局平均池化)。

3.3 融合通道+空间注意力
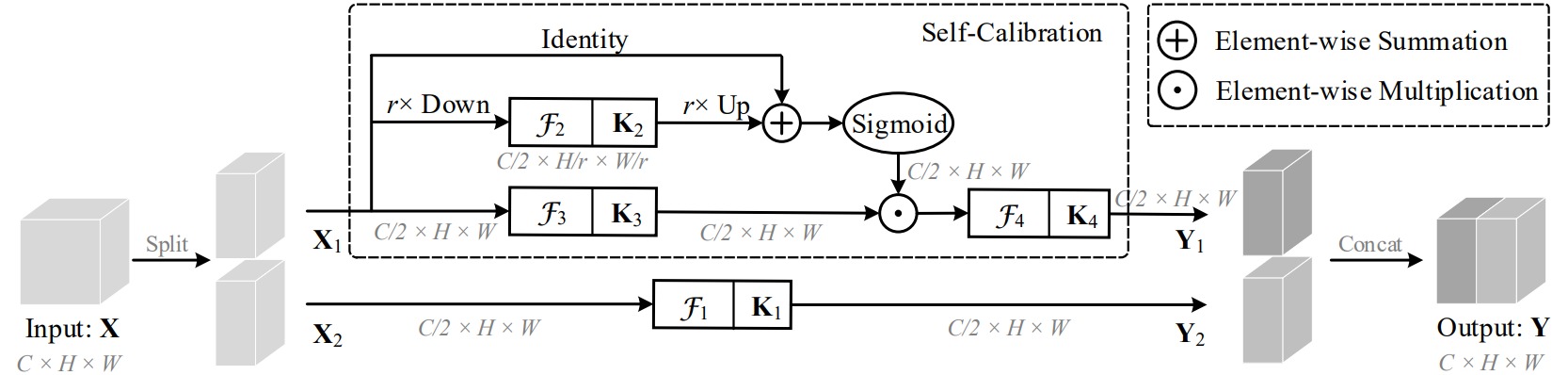
⚪ Self-Calibrated Convolution (SCNet)
SCNet把输入特征沿通道维度拆分成两部分,一部分直接应用标准的卷积操作;另一部分在两个不同的尺度空间中进行卷积特征转换:原始特征空间和下采样后具有较小分辨率的隐空间。
⚪ Coordinate Attention
坐标注意力能够同时建模通道之间的相关性和特征的位置信息。通过沿水平或垂直方向进行平均池化,以捕捉精确的互补位置信息。

⚪ Simple, Parameter-Free Attention Module (SimAM)
SimAM根据视觉神经学中的空间抑制效应为每个神经元生成一个重要性权重。定义神经元的能量函数$E$测量一个目标神经元与其他神经元之间的线性可分性,能量越低,神经元与周围神经元的区别越大,重要性越高。因此神经元的重要性可以通过$1/E$得到。

4. 其他注意力
⚪ Deep Connected Attention Network (DCANet)
DCANet把相邻的注意力模块连接起来,使信息在注意力模块之间流动。实现过程是把前一个注意力模块中转换模块的输出$T_{n-1}$乘以提取模块的输出$E_{n-1}$后(用注意力分布对统计特征进行加权),连接到当前注意力模块中提取模块的输出$E_{n}$。
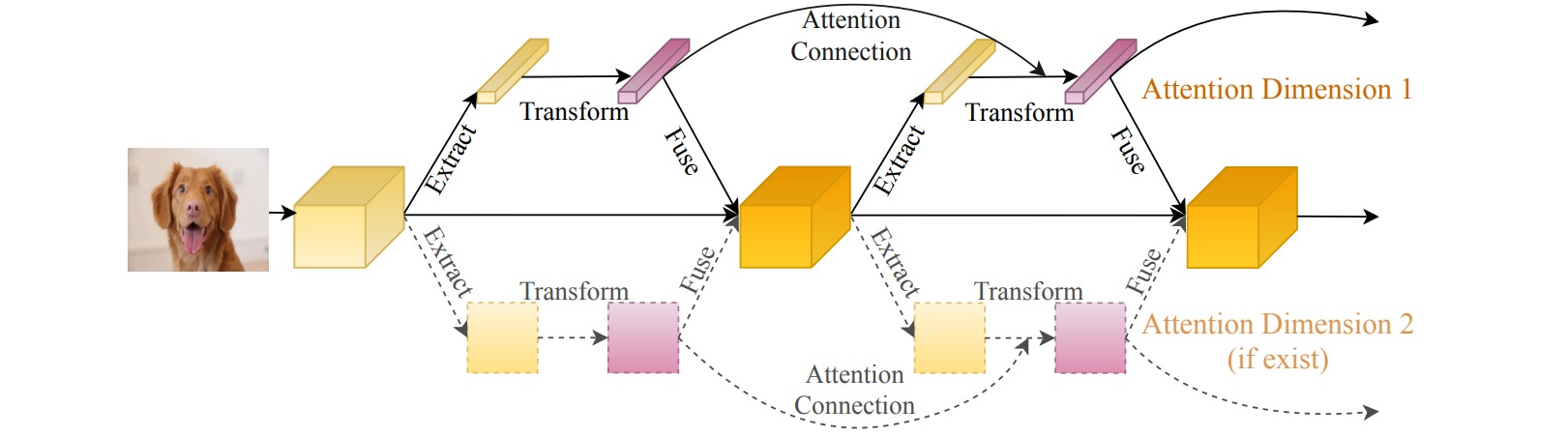
⚪ Weight Excitation (WE)
WE对卷积核的不同权重赋予注意力机制,通过SENet模块调整卷积核每个权重通道的重要性,通过激活函数调整卷积核每个权重幅值的重要性。

⚪ Attentional Activation (ATAC)
ATAC是一种同时用于非线性激活和逐元素特征细化的局部通道注意力模块,该模块局部地聚合了逐点跨通道特征上下文信息。

⚪ Attentional Feature Fusion (AFF)
AFF把来自不同层或不同分支的特征通过注意力机制进行组合。

⚪ AW-Convolution
AW-conv通过生成与卷积核尺寸相同的注意力图并作用于卷积核,实现了多通道、多区域的注意力机制。

⚪ Batch Aware Attention Module (BA^2M)
在图像分类任务中,由于图像内容的复杂性不同,在计算损失的时候不同图像应该具有不同的重要性。BA^2M在批量训练中为每个样本$x_i$根据注意力机制赋予一个重要性权重$w_i$,从而调整其在损失计算中的重要性:
\[\begin{aligned} L &= -\frac{1}{N} \sum_i^N \log (\frac{e^{w_i\cdot f_{y_i}}}{\sum_j^K e^{w_i\cdot f_j}}) \end{aligned}\]
⚪ Interflow
Interflow根据深度把卷积网络划分为几个阶段,并利用每个阶段的特征映射进行预测。把这些预测分支输入到一个注意力模块中学习这些预测分支的权值,并将其聚合得到最终的输出。

⚪ Class-Specific Residual Attention (CSRA)
CSRA通过空间注意力分数为每个类别生成类别相关的特征,然后将其与类别无关的平均池化特征相结合,以提高多标签分类的准确率。

⭐ 参考文献
- Attention Mechanisms in Computer Vision: A Survey:(arXiv1709)一篇卷积神经网络中的注意力机制综述。
- An Attentive Survey of Attention Models:(arXiv1904)包括NLP/CV/推荐系统等方面的注意力机制。
- Residual Attention Network for Image Classification:(arXiv1704)图像分类的残差注意力网络。
- Squeeze-and-Excitation Networks:(arXiv1709)SENet:卷积神经网络的通道注意力机制。
- Concurrent Spatial and Channel Squeeze & Excitation in Fully Convolutional Networks:(arXiv1803)scSE:全卷积网络中的并行空间和通道注意力模块。
- Competitive Inner-Imaging Squeeze and Excitation for Residual Network:(arXiv1807)残差网络的竞争性内部图像通道注意力机制。
- BAM: Bottleneck Attention Module:(arXiv1807)BAM:瓶颈注意力模块。
- CBAM: Convolutional Block Attention Module:(arXiv1807)CBAM:卷积块注意力模块。
- Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks:(arXiv1810)GENet:在通道注意力中利用特征上下文。
- Global Second-order Pooling Convolutional Networks:(arXiv1811)GSoP-Net:全局二阶池化卷积网络。
- SRM: A Style-based Recalibration Module for Convolutional Neural Networks:(arXiv1903)SRM:一种基于风格的卷积神经网络重校准模块。
- Selective Kernel Networks:(arXiv1903)SKNet:通过注意力机制实现卷积核尺寸选择。
- DIANet: Dense-and-Implicit Attention Network:(arXiv1905)DIANet:密集的隐式注意力网络。
- Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks:(arXiv1905)通过空间分组增强模块提高卷积网络的语义特征学习能力。
- ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks:(arXiv1910)ECA-Net:卷积神经网络的高效通道注意力机制。
- Improving Convolutional Networks with Self-Calibrated Convolutions:(CVPR2020)SCNet:通过自校正卷积改进卷积神经网络。
- Weight Excitation: Built-in Attention Mechanisms in Convolutional Neural Networks:(AAAI2020)权重激励:卷积神经网络中的内部注意力机制。
- Spanet: Spatial Pyramid Attention Network for Enhanced Image Recognition:(ICME2020)SPANet:图像识别的空间金字塔注意力网络。
- ULSAM: Ultra-Lightweight Subspace Attention Module for Compact Convolutional Neural Networks:(arXiv2006)ULSAM:超轻量级子空间注意力机制。
- DCANet: Learning Connected Attentions for Convolutional Neural Networks:(arXiv2007)DCANet:学习卷积神经网络中的连接注意力。
- Attention as Activation:(arXiv2007)使用注意力机制作为激活函数。
- Attentional Feature Fusion:(arXiv2009)AFF:特征通道注意力融合。
- Rotate to Attend: Convolutional Triplet Attention Module:(arXiv2010)通过旋转特征构造卷积三元注意力模块。
- FcaNet: Frequency Channel Attention Networks:(arXiv2012)FcaNet:频域通道注意力网络。
- An Attention Module for Convolutional Neural Networks:(arXiv2012)AW-conv:一个卷积神经网络的注意力模块。
- SA-Net: Shuffle Attention for Deep Convolutional Neural Networks:(arXiv2102)SANet:通过特征分组和通道置换实现轻量型置换注意力。
- Coordinate Attention for Efficient Mobile Network Design:(arXiv2103)为轻量型网络设计的坐标注意力机制。
- BA^2M: A Batch Aware Attention Module for Image Classification:(arXiv2103)BA^2M:图像分类的批量注意力模块。
- EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network:(arXiv2105)EPSANet:卷积神经网络的高效金字塔拆分注意力模块。
- Interflow: Aggregating Multi-layer Feature Mappings with Attention Mechanism:(arXiv2106)Interflow:通过注意力机制汇聚多层特征映射。
- Tiled Squeeze-and-Excite: Channel Attention With Local Spatial Context:(arXiv2107)TSE:通过局部空间上下文构造通道注意力。
- Residual Attention: A Simple but Effective Method for Multi-Label Recognition:(arXiv2108)为多标签分类设计的简单有效的残差注意力。
- NAM: Normalization-based Attention Module:(arXiv2111)NAM:基于归一化的注意力模块。
- SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks:(ICML2021)SimAM:为卷积神经网络设计的简单无参数注意力模块。


