scSE:全卷积网络中的并行空间和通道注意力模块.
scSE模块通过并联使用通道注意力和空间注意力增强特征的表达能力。
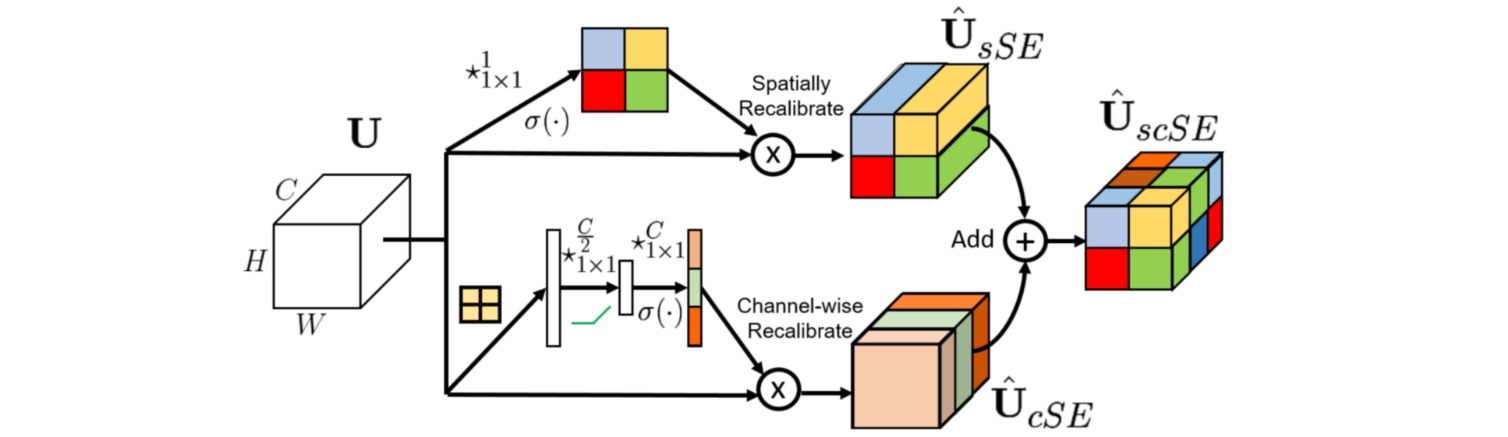
通道注意力使用全局平均池化压缩空间维度,并通过全连接层 (由$1 \times 1$卷积实现,避免空间维度的压缩和解压) 提取通道维度的信息:

class cSE(nn.Module):
def __init__(self, channel, r=2):
super(cSE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.Conv_Squeeze = nn.Conv2d(channel, channel//r, kernel_size=1)
self.relu = nn.ReLU()
self.Conv_Excitation = nn.Conv2d(channel//r, channel, kernel_size=1)
self.norm = nn.Sigmoid()
def forward(self, x):
# [b, c, h, w]
z = self.avgpool(x) # [b, c, 1, 1]
z = self.Conv_Squeeze(z) # [b, c/r, 1, 1]
z = self.relu(z)
z = self.Conv_Excitation(z) # [b, c, 1, 1]
z = self.norm(z)
return x * z.expand_as(x)
空间注意力使用$1 \times 1$卷积层压缩通道维度,并提取空间维度的信息:

class sSE(nn.Module):
def __init__(self, channel):
super(sSE, self).__init__()
self.conv = nn.Conv2d(channel, 1, kernel_size=1)
self.norm = nn.Sigmoid()
def forward(self, x):
q = self.conv(x)
q = self.norm(q)
return x * q # 广播机制
scSE模块把两个并行的注意力特征通过逐元素求和结合起来,可以即插即用到任意卷积神经网络中:
import torch
import torch.nn as nn
class scSE(nn.Module):
def __init__(self, channel):
super(scSE, self).__init__()
self.cSE = cSE(channel)
self.sSE = sSE(channel)
def forward(self, x):
x_sse = self.sSE(x)
x_cse = self.cSE(x)
return x_cse+x_sse
if __name__ == "__main__":
t = torch.ones((32, 256, 24, 24))
scse = scSE(256)
out = scse(t)
print(out.shape)


