DCANet:学习卷积神经网络中的连接注意力.
卷积神经网络中的注意力机制通常只考虑当前的特征。本文作者设计了深度连接注意力网络(Deep Connected Attention Network ,DCANet),将相邻的注意力模块连接起来,使信息在注意力模块之间流动。
作者分别对SENet和DCANet的特征激活进行可视化,结果表明DCANet能够渐进地锁定感兴趣的目标区域。此外,对两种注意力分布进行直方图统计,表明SENet的注意力值分布在$0.5$附近,从而缺乏判别性;而DCANet的分布相对均匀。

注意力机制通常是由提取模块、转换模块和融合模块组成的。提取模块从输入特征中提取统计量(如全局平均池化),转换模块通过非线性函数构造注意力分布(如带瓶颈层的全连接层),融合模块将注意力分布与输入特征进行集成。
DCANet把前一个注意力模块中转换模块的输出$T_{n-1}$乘以提取模块的输出$E_{n-1}$后(用注意力分布对统计特征进行加权),连接到当前注意力模块中提取模块的输出$E_{n}$:$f(\alpha E_{n} , \beta T_{n-1}E_{n-1} )$。
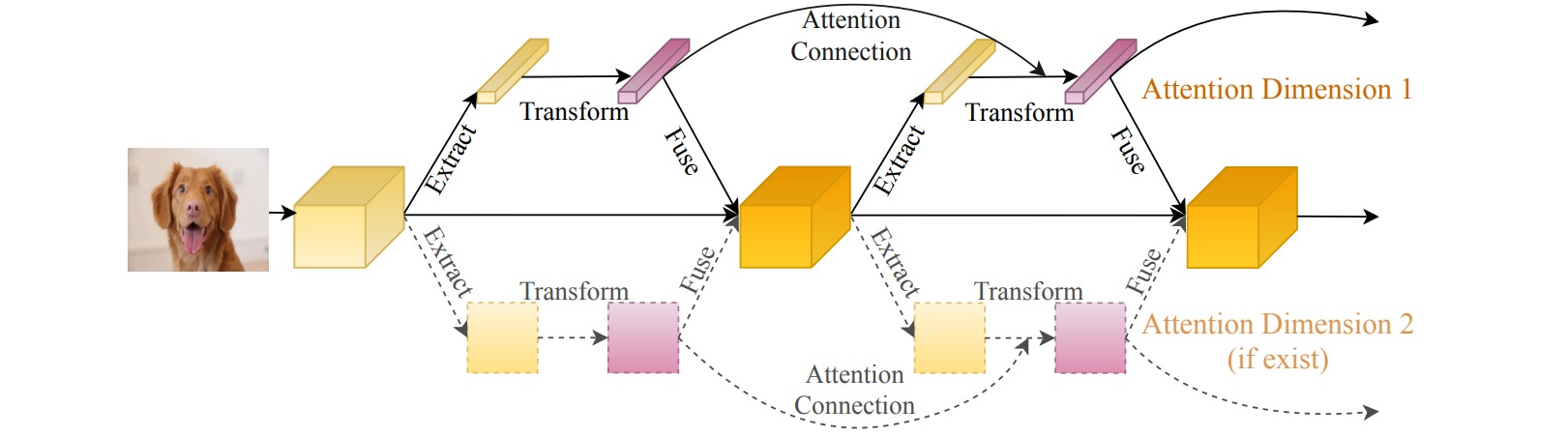
模型不同阶段生成的特征图通道数可能不同,因此需要进行通道匹配,通过全连接层实现。此外注意力模块可能具有不同的维度(通道或空间),可以构造不同维度相互独立的连接,以降低计算开销,并使每个维度都可以关注其内在属性。
import torch
import torch.nn as nn
class DCANet(nn.Module):
def __init__(self,pre_channel, channel, reduction = 16):
super(DCANet, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace = True),
nn.Linear(channel // reduction, channel),
nn.Sigmoid()
)
if pre_channel != channel:
self.att_fc = nn.Sequential(
nn.Linear(pre_channel, channel),
nn.LayerNorm(channel),
nn.ReLU(inplace=True)
)
self.conv = nn.Sequential(
nn.Conv2d(2, 1, kernel_size=1),
nn.LayerNorm(channel),
nn.ReLU(inplace=True)
)
def forward(self, x):
# {0:out_x, 1:out_att}
b, c, _, _ = x[0].size()
gap = self.avg_pool(x[0]).view(b, c)
if x[1] is None:
all_att = self.fc(gap)
else:
pre_att = self.att_fc(x[1]) if hasattr(self, 'att_fc') else x[1]
all_att = torch.cat((gap.view(b, 1, 1, c), pre_att.view(b, 1, 1, c)), dim=1)
all_att = self.conv(all_att).view(b, c)
all_att = self.fc(all_att)
return {0: x[0] * all_att.view(b, c, 1, 1), 1: gap*all_att}

