Image-to-Image Translation.
图像到图像翻译(Image-to-Image Translation)旨在学习一个映射使得图像可以从源图像域(source domain)变换到目标图像域(target domain),同时保留图像内容(context)。
计算机视觉领域的图像到图像翻译问题有许多表现形式,如白天到黑夜的图像转换、黑白照到彩色照的转换、梵高风格化等;这些应用基本都是通过生成对抗网络实现的。
根据是否提供了一对一的学习样本对,将图像到图像翻译任务划分为有配对数据(paired data)和无配对数据(unpaired data)两种情况。
- 有配对数据(监督图像翻译)是指在训练数据集中具有一对一的数据对;即给定联合分布$p(X,Y)$,学习条件映射$f_{x \to y}=p(Y|X)$和$f_{y \to x}=p(X|Y)$。代表方法有Pix2Pix, BicycleGAN, LPTN。
- 无配对数据(无监督图像翻译)是指模型在多个独立的数据集之间训练,能够从多个数据集合中自动地发现集合之间的关联,从而学习出映射函数;即给定边缘分布$p(X)$和$p(Y)$,学习条件映射$f_{x \to y}=p(Y|X)$和$f_{y \to x}=p(X|Y)$。代表方法有CoGAN, PixelDA, CycleGAN, DiscoGAN, DualGAN, UNIT, MUNIT, TUNIT, StarGAN, StarGAN v2, GANILLA, NICE-GAN, CUT, SimDCL。
1. 有配对数据的图像到图像翻译
⚪ Pix2Pix
Pix2Pix的生成器采用UNet网络,把一种类型的图像$x$转换为另一种类型的图像$\hat{y}=G(x)$;损失函数包括对抗损失(NSGAN)和L1重构损失。
判别器设计为PatchGAN,同时接收两种类型的图像$(x,y)$,判断其是否为真实图像;损失函数为对抗损失(MMGAN)。
\[\begin{aligned} \mathop{\max}_{D} & \Bbb{E}_{(x,y) \text{~} (P_{data}(x),P_{data}(y))}[\log D(x,y)] + \Bbb{E}_{x \text{~} P_{data}(x)}[\log(1-D(x,G(x)))] \\ \mathop{ \min}_{G} & -\Bbb{E}_{x \text{~} P_{data}(x)}[\log(D(x,G(x))] + \lambda \Bbb{E}_{(x,y) \text{~} (P_{data}(x),P_{data}(y))}[||y-G(x)||_1] \end{aligned}\]
⚪ BicycleGAN
BicycleGAN的训练过程采用双向的循环过程:
- 一种过程采用变分自编码器的形式。将图像$B$通过一个编码器$E(\cdot)$编码为隐变量$z$,与图像$A$共同输入生成器重构图像$\hat{B}$。建立图像$B$和图像$\hat{B}$之间的重构损失和判别损失,并且构造隐变量$z$的KL散度。
- 另一种过程采用条件生成对抗网络的形式。将图像$A$和随机噪声$z$输入生成器构造图像$\hat{B}$,将其与图像$B$共同构造判别损失。并且使用编码器$E(\cdot)$将图像$\hat{B}$编码为隐变量$z$,构造其与输入隐变量之间的重构损失。

⚪ LPTN
LPTN将图像用拉普拉斯金字塔表示,其中不同层次中的拉普拉斯图像存储了图像中的高频内容信息,因此通过轻量的卷积网络做简单处理;网络顶层的高斯图像存储图像中的低频风格信息,通过一个相对复杂的网络进行处理。整体网络仍然是轻量型的,可以实现实时图像翻译。

2. 无配对数据的图像到图像翻译
⚪ CoGAN
CoGAN使用两个GAN网络,这两个网络通过权重共享机制学习通用的高级语义特征。两个网络的生成器(共享浅层网络)分别学习不同数据域中的数据分布,判别器(共享深层网络)则分别判断是否为对应数据域中的真实数据。目标函数如下:
\[\begin{aligned} \mathop{ \min}_{G_1,G_2} \mathop{\max}_{D_1,D_2} & \Bbb{E}_{x_1 \text{~} P_{data}(x_1)}[\log D_1(x_1)] + \Bbb{E}_{z_1 \text{~} P_{Z}(z_1)}[\log(1-D_1(G_1(z_1)))] \\ & + \Bbb{E}_{x_2 \text{~} P_{data}(x_2)}[\log D_2(x_2)] + \Bbb{E}_{z_2 \text{~} P_{Z}(z_2)}[\log(1-D_2(G_2(z_2)))] \end{aligned}\]
⚪ PixelDA
PixelDA的生成器接收源域图像和随机噪声,将其转换为目标域的图像;判别器判断输入的目标域图像是否真实;额外引入任务相关的网络(通常是分类器)辅助生成器学习。
\[\begin{aligned} \mathop{\max}_{D} & \Bbb{E}_{x^t \text{~} P_{data}^t(x)}[\log D(x^t)] + \Bbb{E}_{(x^s,z) \text{~} (P_{data}^s(x),P_z(z))}[\log(1-D(G(x^s,z)))] \\ \mathop{ \min}_{G} & -\Bbb{E}_{(x^s,z) \text{~} (P_{data}^s(x),P_z(z))}[\log(D(G(x^s,z))] - \Bbb{E}_{(x,y) \text{~} (P_{data}(x),P_{data}(y))}[\log T_y(x)] \end{aligned}\]
⚪ CycleGAN
CycleGAN训练了两个结构为ResNet的生成器,\(G_{X→Y}\)实现从类型$X$转换成类型$Y$,\(G_{Y→X}\)实现从类型$Y$转换成类型$X$;损失函数包括对抗损失(LSGAN)和L1循环一致性损失。
训练两个结构为PatchGAN的判别器,\(D_{X}\)判断图像是否属于类型$X$;\(D_{Y}\)判断图像是否属于类型$Y$;损失函数为对抗损失(LSGAN)。
\[\begin{aligned} \mathop{\min}_{D_X,D_Y} & \Bbb{E}_{y \text{~} P_{data}(y)}[(D_Y(y)-1)^2] + \Bbb{E}_{x \text{~} P_{data}(x)}[(D_Y(G_{X \to Y}(x)))^2] \\ &+ \Bbb{E}_{x \text{~} P_{data}(x)}[(D_X(x)-1)^2] + \Bbb{E}_{y \text{~} P_{data}(y)}[(D_X(G_{Y \to X}(y)))^2] \\ \mathop{ \min}_{G_{X \to Y},G_{Y \to X}} & \Bbb{E}_{x \text{~} P_{data}(x)}[(D_Y(G_{X \to Y}(x))-1)^2]+\Bbb{E}_{y \text{~} P_{data}(y)}[(D_X(G_{Y \to X}(y))-1)^2] \\ &+ \Bbb{E}_{x \text{~} P_{data}(x)}[||G_{Y \to X}(G_{X \to Y}(x))-x||_1] \\ &+ \Bbb{E}_{y \text{~} P_{data}(y)}[||G_{X \to Y}(G_{Y \to X}(y))-y||_1] \end{aligned}\]
⚪ DiscoGAN
DiscoGAN训练了两个结构为UNet的生成器,\(G_{X→Y}\)实现从类型$X$转换成类型$Y$,\(G_{Y→X}\)实现从类型$Y$转换成类型$X$;损失函数包括对抗损失(NSGAN)和L2循环一致性损失。
训练两个结构为PatchGAN的判别器,\(D_{X}\)判断图像是否属于类型$X$;\(D_{Y}\)判断图像是否属于类型$Y$;损失函数为对抗损失(NSGAN)。
\[\begin{aligned} \mathop{\max}_{D_X,D_Y} & \Bbb{E}_{y \text{~} P_{data}(y)}[\log D_Y(y)] + \Bbb{E}_{x \text{~} P_{data}(x)}[\log(1-D_Y(G_{X \to Y}(x)))] \\ &+ \Bbb{E}_{x \text{~} P_{data}(x)}[\log D_X(x)] + \Bbb{E}_{y \text{~} P_{data}(y)}[\log(1-D_X(G_{Y \to X}(y)))] \\ \mathop{ \min}_{G_{X \to Y},G_{Y \to X}} &- \Bbb{E}_{x \text{~} P_{data}(x)}[\log(D_Y(G_{X \to Y}(x)))]-\Bbb{E}_{y \text{~} P_{data}(y)}[\log(D_X(G_{Y \to X}(y)))] \\ &+ \Bbb{E}_{x \text{~} P_{data}(x)}[||G_{Y \to X}(G_{X \to Y}(x))-x||_2^2] \\ &+ \Bbb{E}_{y \text{~} P_{data}(y)}[||G_{X \to Y}(G_{Y \to X}(y))-y||_2^2] \end{aligned}\]
⚪ DualGAN
DualGAN训练了两个结构为UNet的生成器,\(G_{X→Y}\)实现从类型$X$转换成类型$Y$,\(G_{Y→X}\)实现从类型$Y$转换成类型$X$;损失函数包括对抗损失(WGAN)和L1循环一致性损失。
训练两个结构为PatchGAN的判别器,\(D_{X}\)判断图像是否属于类型$X$;\(D_{Y}\)判断图像是否属于类型$Y$;损失函数为对抗损失(WGAN)。
\[\begin{aligned} \mathop{\max}_{||D_X||_L\leq 1,||D_Y||_L\leq 1} & \Bbb{E}_{y \text{~} P_{data}(y)}[D_Y(y)] - \Bbb{E}_{x \text{~} P_{data}(x)}[D_Y(G_{X \to Y}(x))] \\ &+ \Bbb{E}_{x \text{~} P_{data}(x)}[D_X(x)] - \Bbb{E}_{y \text{~} P_{data}(y)}[D_X(G_{Y \to X}(y))] \\ \mathop{ \min}_{G_{X \to Y},G_{Y \to X}} &- \Bbb{E}_{x \text{~} P_{data}(x)}[D_Y(G_{X \to Y}(x))]-\Bbb{E}_{y \text{~} P_{data}(y)}[D_X(G_{Y \to X}(y))] \\ &+ \Bbb{E}_{x \text{~} P_{data}(x)}[||G_{Y \to X}(G_{X \to Y}(x))-x||_1] \\ &+ \Bbb{E}_{y \text{~} P_{data}(y)}[||G_{X \to Y}(G_{Y \to X}(y))-y||_1] \end{aligned}\]
⚪ UNIT
UNIT假设不同风格的一对图像$x_1,x_2$可以在隐空间中找到同一个对应的隐变量$z$。图像集与隐空间之间的映射关系通过VAE实现,分别使用两个编码器把图像映射到隐空间,再分别使用两个生成器把隐变量重构为图像。与此同时,引入两个判别器分别判断两种类型图像的真实性。
UNIT的目标函数包括VAE损失、GAN损失和cycle consistency损失。
\[\begin{aligned} \mathop{ \min}_{G_1,G_2,E_1,E_2} \mathop{\max}_{D_1,D_2} & \mathcal{L}_{\text{VAE}_1}(E_1,G_1) + \mathcal{L}_{\text{GAN}_1}(E_1,G_1,D_1) + \mathcal{L}_{\text{CC}_1}(E_1,G_1,E_2,G_2) \\ & +\mathcal{L}_{\text{VAE}_2}(E_2,G_2) + \mathcal{L}_{\text{GAN}_2}(E_2,G_2,D_2) + \mathcal{L}_{\text{CC}_2}(E_2,G_2,E_1,G_1) \end{aligned}\]
⚪ MUNIT
MUNIT假设每一张图像$x$都对应在所有领域共享的内容空间中的内容编码$c$和领域特有的风格空间中的风格编码$s$。
MUNIT的学习过程包括图像重构和编码重构两部分。图像重构是指对图像$x_1,x_2$分别编码为$(c_1,s_1),(c_2,s_2)$,再解码为重构图像\(\hat{x}_1,\hat{x}_2\),并最终构造两者的L1重构损失。编码重构是指对图像$x_1,x_2$分别编码为$(c_1,s_1),(c_2,s_2)$,然后重组编码$(c_1,s_2),(c_2,s_1)$,并解码为迁移风格的图像\(x_{1 \to 2},x_{2 \to 1}\),然后再将其分别编码为\((\hat{c}_1,\hat{s}_2),(\hat{c}_2,\hat{s}_1)\),并最终构造编码的L1重构损失。此外,对图像$x_1,x_2$和迁移图像\(x_{1 \to 2},x_{2 \to 1}\)应用对抗损失。
\[\begin{aligned} \mathop{ \min}_{G_1,G_2,E_1,E_2} \mathop{\max}_{D_1,D_2} &\mathcal{L}_{\text{GAN}}^{x_1} + \mathcal{L}_{\text{GAN}}^{x_2} + \lambda_x(\mathcal{L}_{\text{recon}}^{x_1}+\mathcal{L}_{\text{recon}}^{x_2}) \\ & + \lambda_c(\mathcal{L}_{\text{recon}}^{c_1}+\mathcal{L}_{\text{recon}}^{c_2})+ \lambda_s(\mathcal{L}_{\text{recon}}^{s_1}+\mathcal{L}_{\text{recon}}^{s_2}) \end{aligned}\]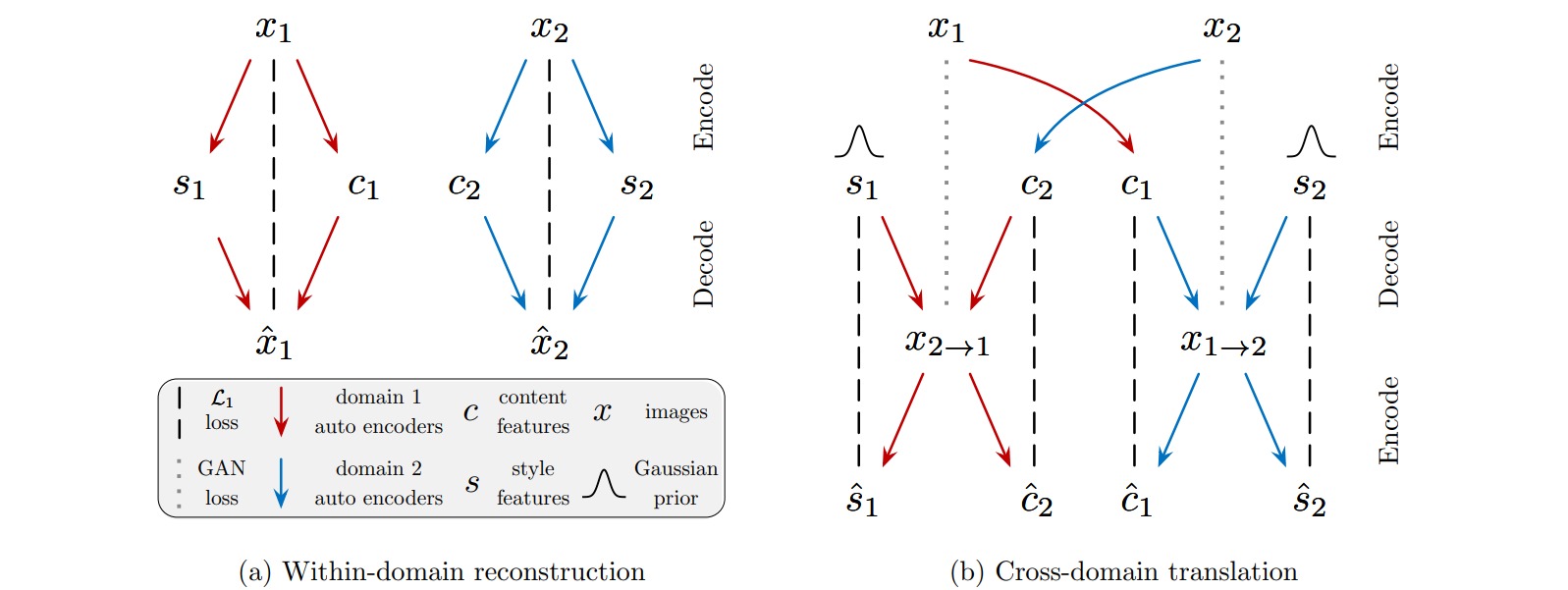
⚪ TUNIT
TUNIT实现了一个图像数据集中任意两张图像之间的翻译,该方法由编码器、生成器、判别器组成。编码器把输入图像编码为领域标签(通过IIC预训练)和风格编码(通过MoCo预训练);生成器根据输入图像和风格编码生成图像,损失函数包括L1重构损失、对抗损失和风格对比损失;判别器接收输入图像和领域标签,判定该领域中图像的真实性,损失函数为对抗损失。
\[\begin{aligned} \mathop{ \min}_{G,E} \mathop{\max}_{D} &\mathcal{L}_{\text{adv}}(D,G) + \lambda_{\text{style}}^G\mathcal{L}_{\text{style}}^G(G,E) + \lambda_{\text{rec}}\mathcal{L}_{\text{rec}}(G,E) \\ & - \lambda_{MI}\mathcal{L}_{MI}(E)+ \lambda_{\text{style}}^E\mathcal{L}_{\text{style}}^E(E) \end{aligned}\]
⚪ StarGAN
StarGAN的判别器结构为PatchGAN,用于判断图像是否为真实图像,若为真实图像则进一步预测其领域标签;目标函数包括对抗损失(NSGAN)和标签分类损失。
生成器结构为ResNet,接收一张图像和给定的领域标签,生成对应领域的图像;目标函数包括对抗损失(NSGAN)、标签分类损失和L1重构损失。
\[\begin{aligned} \mathop{\max}_{D} & \Bbb{E}_{x \text{~} P_{data}(x)}[\log D(x)] + \Bbb{E}_{x \text{~} P_{data}(x)}[1-\log D(G(x, y^t))] \\ &+ \Bbb{E}_{(x,y) \text{~} (P_{data}(x),P_{data}(Y))}[\log D_{y}(x)] \\ \mathop{ \min}_{G} &- \Bbb{E}_{x \text{~} P_{data}(x)}[D(G(x, y^t))]-\Bbb{E}_{x \text{~} P_{data}(x)}[\log D_{y^t}(G(x, y^t))] \\ &+ \Bbb{E}_{x \text{~} P_{data}(x)}[||x-G(G(x, y^t),y^s)||_1] \end{aligned}\]
⚪ StarGAN v2
StarGAN v2由生成器、映射网络、风格编码器和判别器构成。生成器接收输入图像和风格编码,生成对应风格的图像;映射网络输入随机噪声,生成不同图像域的不同风格编码;风格编码器提取输入图像在不同图像域中的风格编码;判别器判断图像是否为某图像域中的真实图像。
损失函数包括对抗损失、风格编码的L1重构损失、通过最大化两个风格编码对应的生成图像的差异构造多样性敏感损失、使用输入图像的风格编码将生成图像重新映射到原图像域构造的循环一致性损失。
\[\begin{aligned} \mathop{ \min}_{F,E,G} \mathop{\max}_{D} & \mathcal{L}_{\text{adv}}(F,G,D) + \lambda_{\text{sty}} \mathcal{L}_{\text{sty}}(F,E,G) \\ & -\lambda_{\text{ds}}\mathcal{L}_{\text{ds}}(F,G) + \lambda_{\text{cyc}}\mathcal{L}_{\text{cyc}}(F,E,G) \end{aligned}\]
⚪ GANILLA
GANNILLA是一种从自然图像到儿童读物插画的图像翻译模型,其主体结构与CycleGAN, DualGAN, DiscoGAN等类似,作者重新设计了生成器的网络结构,能够在保留输入图像内容的同时迁移风格。GANNILLA的生成器采用非对称结构,使用带有拼接连接的残差层,并使用上采样算子代替转置卷积层。

⚪ NICE-GAN
NICE-GAN通过把判别器的一部分重用为编码器,实现紧凑的网络结构设计。具体地,把判别器$D$拆分成编码器$E^D$和分类器$C^D$;训练流程与CycleGAN类似,训练两个生成器和两个判别器;生成器损失函数包括对抗损失(LSGAN)、L1循环一致性损失和L1重构损失;判别器的损失函数为对抗损失(LSGAN)。
\[\begin{aligned} \mathop{\min}_{D_X=E_X\circ C_X,D_Y=E_Y\circ C_Y} & \Bbb{E}_{y \text{~} P_{data}(y)}[(D_Y(y)-1)^2] + \Bbb{E}_{x \text{~} P_{data}(x)}[(D_Y(G_{X \to Y}(E_X(x))))^2] \\ &+ \Bbb{E}_{x \text{~} P_{data}(x)}[(D_X(x)-1)^2] + \Bbb{E}_{y \text{~} P_{data}(y)}[(D_X(G_{Y \to X}(E_Y(y))))^2] \\ \mathop{ \min}_{G_{X \to Y},G_{Y \to X}} & \Bbb{E}_{x \text{~} P_{data}(x)}[(D_Y(G_{X \to Y}(E_X(x)))-1)^2]+\Bbb{E}_{y \text{~} P_{data}(y)}[(D_X(G_{Y \to X}(E_Y(y)))-1)^2] \\ &+ \Bbb{E}_{x \text{~} P_{data}(x)}[||G_{Y \to X}(E_Y(G_{X \to Y}(E_X(x))))-x||_1] \\ &+ \Bbb{E}_{y \text{~} P_{data}(y)}[||G_{X \to Y}(E_X(G_{Y \to X}(E_Y(y))))-y||_1] \\ &+ \Bbb{E}_{x \text{~} P_{data}(x)}[||G_{Y \to X}(E_X(x))-x||_1] \\ &+ \Bbb{E}_{y \text{~} P_{data}(y)}[||G_{X \to Y}(E_Y(y))-y||_1] \end{aligned}\]
⚪ CUT
CUT使用对比学习构造生成器的损失函数。把输入图像$x$和生成图像$\hat{y}$通过生成器的编码部分提取特征,然后使用多层感知机$H_l$对特征进行变换。此时特征的每个像素位置对应原始图像的一个图像块;则两个图像相同位置的图像块对应的特征向量为正样本对,其余位置的特征向量为负样本。基于此可以构造对比损失:
\[\mathcal{L}(v,v^+,v^-) = -\log [\frac{\exp(v \cdot v^+/ \tau)}{\exp(v \cdot v^+/ \tau)+ \sum_{n=1}^N \exp(v \cdot v^-_n/ \tau)}]\]
⚪ SimDCL
SimDCL使用两个CUT构成对偶结构。损失函数包括对抗损失、对比损失、恒等损失(目标域图像$Y$经过生成器\(G_{X→Y}\)后图像风格应该保持不变)和相似度损失(同一数据模态的样本$X_1,X_2$的特征应用多层感知机$H_{X1},H_{X2}$后应相同)。

⚪ 参考文献
- Coupled Generative Adversarial Networks:(arXiv1606)CoGAN:耦合生成对抗网络。
- Image-to-Image Translation with Conditional Adversarial Networks:(arXiv1611)Pix2Pix:通过UNet和PatchGAN实现图像转换。
- Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks:(arXiv1612)PixelDA:通过GAN实现像素级领域自适应。
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks:(arXiv1703)CycleGAN:使用循环一致损失实现无配对数据的图像转换。
- Learning to Discover Cross-Domain Relations with Generative Adversarial Networks:(arXiv1703)DiscoGAN:使用GAN学习发现跨领域关系。
- Unsupervised Image-to-Image Translation Networks:(arXiv1703)UNIT:无监督图像到图像翻译网络。
- DualGAN: Unsupervised Dual Learning for Image-to-Image Translation:(arXiv1704)DualGAN:图像转换的无监督对偶学习。
- Toward Multimodal Image-to-Image Translation:(arXiv1711)BicycleGAN:多模态图像翻译。
- StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation:(arXiv1711)StarGAN:统一的多领域图像翻译框架。
- Multimodal Unsupervised Image-to-Image Translation:(arXiv1804)MUNIT:多模态无监督图像到图像翻译网络。
- StarGAN v2: Diverse Image Synthesis for Multiple Domains:(arXiv1912)StarGAN v2:多领域多样性图像合成。
- GANILLA: Generative Adversarial Networks for Image to Illustration Translation:(arXiv2002)GANILLA:把图像转换为儿童绘本风格。
- Reusing Discriminators for Encoding: Towards Unsupervised Image-to-Image Translation:(arXiv2003)NICE-GAN: 把判别器重用为编码器的图像翻译模型。
- Rethinking the Truly Unsupervised Image-to-Image Translation:(arXiv2006)TUNIT:完全无监督图像到图像翻译。
- Contrastive Learning for Unpaired Image-to-Image Translation:(arXiv2006)CUT:无配对数据图像到图像翻译中的对比学习。
- Dual Contrastive Learning for Unsupervised Image-to-Image Translation:(arXiv2104)SimDCL:无监督图像到图像翻译的对偶对比学习。
- High-Resolution Photorealistic Image Translation in Real-Time: A Laplacian Pyramid Translation Network:(arXiv2105)LPTN:高分辨率真实感实时图像翻译。


