MUNIT:多模态无监督图像到图像翻译网络.
UNIT假设不同风格的图像集存在共享的隐变量空间,即每一对图像$x_1,x_2$都可以在隐空间中找到同一个对应的隐变量$z$。

本文作者指出该假设过于简化,无法满足更多图像集之间的对应关系。因此进一步假设,每一张图像$x$都对应在所有领域共享的内容空间中的内容编码$c$和领域特有的风格空间中的风格编码$s$。

网络的学习过程包括图像重构和编码重构两部分。
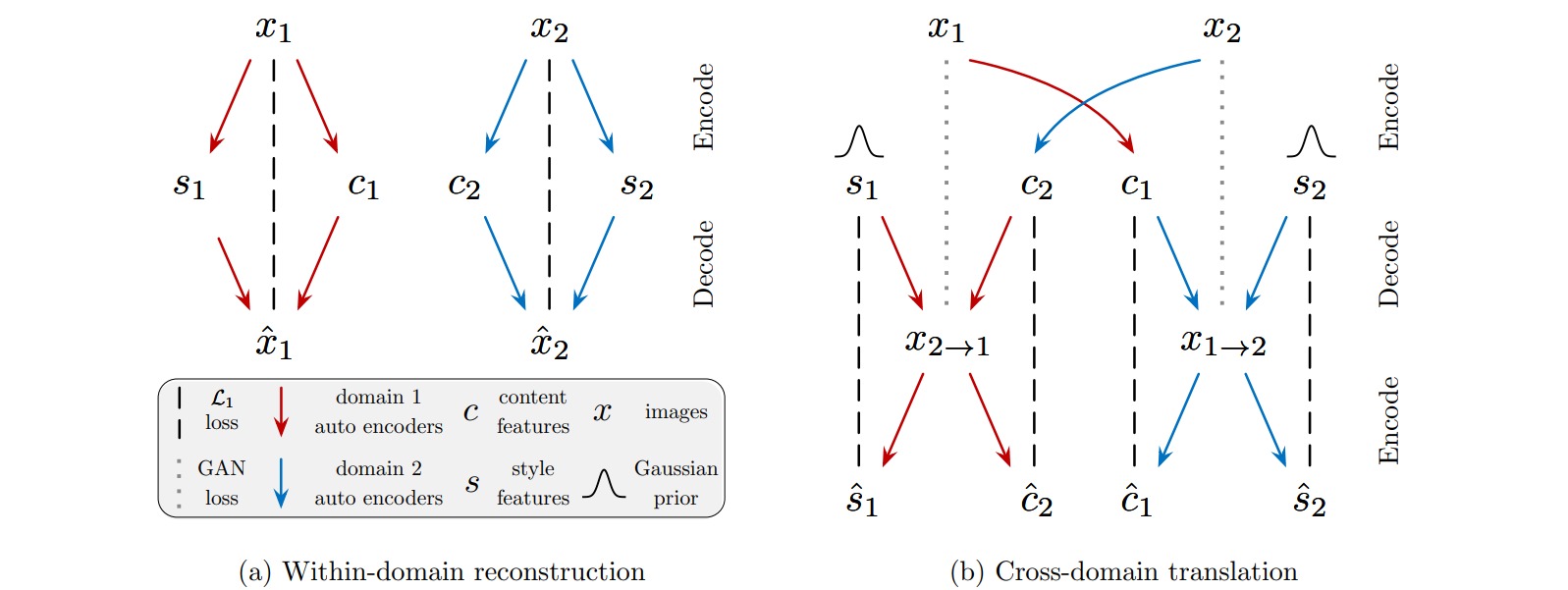
图像重构是指对图像$x_1,x_2$分别编码为$(c_1,s_1),(c_2,s_2)$,再解码为重构图像$\hat{x}_1,\hat{x}_2$,并最终构造两者的L1重构损失:
\[\begin{aligned} \mathcal{L}_{\text{recon}}^{x_1} &= \Bbb{E}_{x_1 \text{~} p(x_1)}[||x_1-G_1(E_1^c(x_1),E_1^s(x_1))||_1 ] \\ \mathcal{L}_{\text{recon}}^{x_2} &= \Bbb{E}_{x_2 \text{~} p(x_2)}[||x_2-G_2(E_2^c(x_2),E_2^s(x_2))||_1 ] \end{aligned}\]编码重构是指对图像$x_1,x_2$分别编码为$(c_1,s_1),(c_2,s_2)$,然后重组编码$(c_1,s_2),(c_2,s_1)$,并解码为迁移风格的图像$x_{1 \to 2},x_{2 \to 1}$,然后再将其分别编码为$(\hat{c}_1,\hat{s}_2),(\hat{c}_2,\hat{s}_1)$,并最终构造编码的L1重构损失:
\[\begin{aligned} \mathcal{L}_{\text{recon}}^{c_1} &= \Bbb{E}_{c_1 \text{~} p(c_1),s_2 \text{~} p(s_2)}[||c_1-E_2^c(G_2(c_1,s_2))||_1 ] \\ \mathcal{L}_{\text{recon}}^{s_2} &= \Bbb{E}_{c_1 \text{~} p(c_1),s_2 \text{~} p(s_2)}[||s_2-E_2^s(G_2(c_1,s_2))||_1 ] \\ \mathcal{L}_{\text{recon}}^{c_2} &= \Bbb{E}_{c_2 \text{~} p(c_2),s_1 \text{~} p(s_1)}[||c_2-E_1^c(G_1(c_2,s_1))||_1 ] \\ \mathcal{L}_{\text{recon}}^{s_1} &= \Bbb{E}_{c_2 \text{~} p(c_2),s_1 \text{~} p(s_1)}[||s_1-E_1^s(G_1(c_2,s_1))||_1 ] \end{aligned}\]此外,对图像$x_1,x_2$和迁移图像$x_{1 \to 2},x_{2 \to 1}$应用对抗损失:
\[\begin{aligned} \mathcal{L}_{\text{GAN}}^{x_1} &= \Bbb{E}_{x_1 \text{~} p(x_1)}[\log D_1(x_1)] + \Bbb{E}_{c_2 \text{~} p(c_2),s_1 \text{~} p(s_1)}[1-\log D_1(G_1(c_2,s_1))] \\ \mathcal{L}_{\text{GAN}}^{x_2} &= \Bbb{E}_{x_2 \text{~} p(x_2)}[\log D_2(x_2)] + \Bbb{E}_{c_1 \text{~} p(c_1),s_2 \text{~} p(s_2)}[1-\log D_2(G_2(c_1,s_2))] \end{aligned}\]网络的总损失函数如下:
\[\begin{aligned} \mathop{ \min}_{G_1,G_2,E_1,E_2} \mathop{\max}_{D_1,D_2} &\mathcal{L}_{\text{GAN}}^{x_1} + \mathcal{L}_{\text{GAN}}^{x_2} + \lambda_x(\mathcal{L}_{\text{recon}}^{x_1}+\mathcal{L}_{\text{recon}}^{x_2}) \\ & + \lambda_c(\mathcal{L}_{\text{recon}}^{c_1}+\mathcal{L}_{\text{recon}}^{c_2})+ \lambda_s(\mathcal{L}_{\text{recon}}^{s_1}+\mathcal{L}_{\text{recon}}^{s_2}) \end{aligned}\]网络的整体结构如图所示,其中生成器(解码器)采用了AdaIN方法,即通过风格编码$s$来参数化Instance归一化过程中的仿射参数$\gamma,\beta$。
\[AdaIN(z,\gamma,\beta) = \gamma (\frac{z-\mu(z)}{\sigma(z)})+\beta\]
MUNIT的完整pytorch实现可参考PyTorch-GAN。
MUNIT的编码器实现如下。其中内容编码器为全卷积形式,对应的内容编码为二维张量;风格编码器为卷积+全连接层形式,对应的风格编码为一维向量。
#################################
# Content Encoder
#################################
class ContentEncoder(nn.Module):
def __init__(self, in_channels=3, dim=64, n_residual=3, n_downsample=2):
super(ContentEncoder, self).__init__()
# Initial convolution block
layers = [
nn.ReflectionPad2d(3),
nn.Conv2d(in_channels, dim, 7),
nn.InstanceNorm2d(dim),
nn.ReLU(inplace=True),
]
# Downsampling
for _ in range(n_downsample):
layers += [
nn.Conv2d(dim, dim * 2, 4, stride=2, padding=1),
nn.InstanceNorm2d(dim * 2),
nn.ReLU(inplace=True),
]
dim *= 2
# Residual blocks
for _ in range(n_residual):
layers += [ResidualBlock(dim, norm="in")]
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
#################################
# Style Encoder
#################################
class StyleEncoder(nn.Module):
def __init__(self, in_channels=3, dim=64, n_downsample=2, style_dim=8):
super(StyleEncoder, self).__init__()
# Initial conv block
layers = [nn.ReflectionPad2d(3), nn.Conv2d(in_channels, dim, 7), nn.ReLU(inplace=True)]
# Downsampling
for _ in range(2):
layers += [nn.Conv2d(dim, dim * 2, 4, stride=2, padding=1), nn.ReLU(inplace=True)]
dim *= 2
# Downsampling with constant depth
for _ in range(n_downsample - 2):
layers += [nn.Conv2d(dim, dim, 4, stride=2, padding=1), nn.ReLU(inplace=True)]
# Average pool and output layer
layers += [nn.AdaptiveAvgPool2d(1), nn.Conv2d(dim, style_dim, 1, 1, 0)]
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
#################################
# Encoder
#################################
class Encoder(nn.Module):
def __init__(self, in_channels=3, dim=64, n_residual=3, n_downsample=2, style_dim=8):
super(Encoder, self).__init__()
self.content_encoder = ContentEncoder(in_channels, dim, n_residual, n_downsample)
self.style_encoder = StyleEncoder(in_channels, dim, n_downsample, style_dim)
def forward(self, x):
content_code = self.content_encoder(x)
style_code = self.style_encoder(x)
return content_code, style_code
# Initialize encoders
Enc1 = Encoder(dim=opt.dim, n_downsample=opt.n_downsample, n_residual=opt.n_residual, style_dim=opt.style_dim)
Enc2 = Encoder(dim=opt.dim, n_downsample=opt.n_downsample, n_residual=opt.n_residual, style_dim=opt.style_dim)
MUNIT的生成器(解码器)实现如下。
######################################
# MLP (predicts AdaIn parameters)
######################################
class MLP(nn.Module):
def __init__(self, input_dim, output_dim, dim=256, n_blk=3, activ="relu"):
super(MLP, self).__init__()
layers = [nn.Linear(input_dim, dim), nn.ReLU(inplace=True)]
for _ in range(n_blk - 2):
layers += [nn.Linear(dim, dim), nn.ReLU(inplace=True)]
layers += [nn.Linear(dim, output_dim)]
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x.view(x.size(0), -1))
#################################
# Decoder
#################################
class Decoder(nn.Module):
def __init__(self, out_channels=3, dim=64, n_residual=3, n_upsample=2, style_dim=8):
super(Decoder, self).__init__()
layers = []
dim = dim * 2 ** n_upsample
# Residual blocks
for _ in range(n_residual):
layers += [ResidualBlock(dim, norm="adain")]
# Upsampling
for _ in range(n_upsample):
layers += [
nn.Upsample(scale_factor=2),
nn.Conv2d(dim, dim // 2, 5, stride=1, padding=2),
LayerNorm(dim // 2),
nn.ReLU(inplace=True),
]
dim = dim // 2
# Output layer
layers += [nn.ReflectionPad2d(3), nn.Conv2d(dim, out_channels, 7), nn.Tanh()]
self.model = nn.Sequential(*layers)
# Initiate mlp (predicts AdaIN parameters)
num_adain_params = self.get_num_adain_params()
self.mlp = MLP(style_dim, num_adain_params)
def get_num_adain_params(self):
"""Return the number of AdaIN parameters needed by the model"""
num_adain_params = 0
for m in self.modules():
if m.__class__.__name__ == "AdaptiveInstanceNorm2d":
num_adain_params += 2 * m.num_features
return num_adain_params
def assign_adain_params(self, adain_params):
"""Assign the adain_params to the AdaIN layers in model"""
for m in self.modules():
if m.__class__.__name__ == "AdaptiveInstanceNorm2d":
# Extract mean and std predictions
mean = adain_params[:, : m.num_features]
std = adain_params[:, m.num_features : 2 * m.num_features]
# Update bias and weight
m.bias = mean.contiguous().view(-1)
m.weight = std.contiguous().view(-1)
# Move pointer
if adain_params.size(1) > 2 * m.num_features:
adain_params = adain_params[:, 2 * m.num_features :]
def forward(self, content_code, style_code):
# Update AdaIN parameters by MLP prediction based off style code
self.assign_adain_params(self.mlp(style_code))
img = self.model(content_code)
return img
# Initialize generators
Dec1 = Decoder(dim=opt.dim, n_upsample=opt.n_downsample, n_residual=opt.n_residual, style_dim=opt.style_dim)
Dec2 = Decoder(dim=opt.dim, n_upsample=opt.n_downsample, n_residual=opt.n_residual, style_dim=opt.style_dim)
其中用于融合风格编码和内容编码的AdaIN方法实现如下:
norm_layer = AdaptiveInstanceNorm2d
class AdaptiveInstanceNorm2d(nn.Module):
"""Reference: https://github.com/NVlabs/MUNIT/blob/master/networks.py"""
def __init__(self, num_features, eps=1e-5, momentum=0.1):
super(AdaptiveInstanceNorm2d, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
# weight and bias are dynamically assigned
self.weight = None
self.bias = None
# just dummy buffers, not used
self.register_buffer("running_mean", torch.zeros(num_features))
self.register_buffer("running_var", torch.ones(num_features))
def forward(self, x):
assert (
self.weight is not None and self.bias is not None
), "Please assign weight and bias before calling AdaIN!"
b, c, h, w = x.size()
running_mean = self.running_mean.repeat(b)
running_var = self.running_var.repeat(b)
# Apply instance norm
x_reshaped = x.contiguous().view(1, b * c, h, w)
out = F.batch_norm(
x_reshaped, running_mean, running_var, self.weight, self.bias, True, self.momentum, self.eps
)
return out.view(b, c, h, w)
def __repr__(self):
return self.__class__.__name__ + "(" + str(self.num_features) + ")"
MUNIT的判别器实现如下:
class MultiDiscriminator(nn.Module):
def __init__(self, in_channels=3):
super(MultiDiscriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalize=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
# Extracts three discriminator models
self.models = nn.ModuleList()
for i in range(3):
self.models.add_module(
"disc_%d" % i,
nn.Sequential(
*discriminator_block(in_channels, 64, normalize=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.Conv2d(512, 1, 3, padding=1)
),
)
self.downsample = nn.AvgPool2d(in_channels, stride=2, padding=[1, 1], count_include_pad=False)
def forward(self, x):
outputs = []
for m in self.models:
outputs.append(m(x))
x = self.downsample(x)
return outputs
# Initialize discriminators
D1 = MultiDiscriminator()
D2 = MultiDiscriminator()
MUNIT的损失函数计算和参数更新过程如下:
criterion_GAN = torch.nn.BCELoss()
criterion_recon = torch.nn.L1Loss()
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(Enc1.parameters(), Dec1.parameters(), Enc2.parameters(), Dec2.parameters()),
lr=opt.lr,
betas=(opt.b1, opt.b2),
)
optimizer_D1 = torch.optim.Adam(D1.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D2 = torch.optim.Adam(D2.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
for epoch in range(opt.n_epochs):
for i, (X1, X2) in enumerate(zip(dataloader_A, dataloader_B)):
# Adversarial ground truths
valid = torch.ones(X1.shape[0], *patch).requires_grad_(False)
fake = torch.zeros(X1.shape[0], *patch).requires_grad_(False)
# ----------------------------------
# forward propogation
# ----------------------------------
# Get shared latent representation
c_code_1, s_code_1 = Enc1(X1)
c_code_2, s_code_2 = Enc2(X2)
# Reconstruct images
X11 = Dec1(c_code_1, s_code_1)
X22 = Dec2(c_code_2, s_code_2)
# Translate images
X21 = Dec1(c_code_2, s_code_1)
X12 = Dec2(c_code_1, s_code_2)
# Cycle translation
c_code_21, s_code_21 = Enc1(X21)
c_code_12, s_code_12 = Enc2(X12)
# -----------------------
# Train Discriminator 1
# -----------------------
optimizer_D1.zero_grad()
loss_D1 = criterion_GAN(X1, valid) + criterion_GAN(X21.detach(), fake)
loss_D1.backward()
optimizer_D1.step()
# -----------------------
# Train Discriminator 2
# -----------------------
optimizer_D2.zero_grad()
loss_D2 = criterion_GAN(X2, valid) + criterion_GAN(X12.detach(), fake)
loss_D2.backward()
optimizer_D2.step()
# -------------------------------
# Train Generator and Encoder
# -------------------------------
optimizer_G.zero_grad()
# Losses
loss_GAN_1 = lambda_gan * criterion_GAN(X21, valid)
loss_GAN_2 = lambda_gan * criterion_GAN(X12, valid)
loss_ID_1 = lambda_id * criterion_recon(X11, X1)
loss_ID_2 = lambda_id * criterion_recon(X22, X2)
loss_s_1 = lambda_style * criterion_recon(s_code_21, style_1)
loss_s_2 = lambda_style * criterion_recon(s_code_12, style_2)
loss_c_1 = lambda_cont * criterion_recon(c_code_12, c_code_1.detach())
loss_c_2 = lambda_cont * criterion_recon(c_code_21, c_code_2.detach())
# Total loss
loss_G = (
loss_GAN_1
+ loss_GAN_2
+ loss_ID_1
+ loss_ID_2
+ loss_s_1
+ loss_s_2
+ loss_c_1
+ loss_c_2
)
loss_G.backward()
optimizer_G.step()


