ConvNeXt V2: 使用MAE协同设计和扩展卷积网络.
本文作者把视觉领域的自监督预训练技术和卷积网络的结构设计结合起来,设计了一种适用于卷积神经网络的掩蔽预训练方法FCMAE,并基于此设计了适用于掩蔽预训练的卷积网络ConvNeXt V2。
1. 全卷积掩蔽自编码器 Fully Convolutional Masked AutoEncoder
掩蔽自编码器 (MAE)是一种流行的视觉自监督学习方法,该方法针对视觉Transformer设计了一种自监督学习框架,通过随机遮挡输入的部分子区域并预测这些区域,实现了视觉信息的表征学习。
然而这种掩蔽自训练方法不适合直接应用到卷积神经网络中。MAE只把可见的图像块输入视觉Transformer,而卷积网络采用密集的滑动窗口。为了将卷积层用于稀疏的图像数据,在预训练阶段采用子流形稀疏卷积,这使得模型只能在可见的数据点上操作;在微调阶段,稀疏卷积层可以转换回标准卷积,而不需要额外的处理。
基于稀疏卷积设计的全卷积掩蔽自编码器(Fully Convolutional Masked AutoEncoder, FCMAE)采用编码器-解码器结构。编码器采用分层结构,逐渐把被掩蔽的输入图像转换为掩码特征;解码器采用单个卷积块,输出预测被掩蔽的图像部分。损失函数采用被掩蔽图像部分与对应真实图像块的均方误差。编码器和解码器均采用ConvNeXt网络。

在实验时作者设置$0.6$的随即掩码策略,即从原始输入图像中随机去除 $60\%$的$32\times 32$图像块,数据增强采用随机裁剪。实验在ImageNet-1K数据集上进行$800$轮预训练,然后进行$100$轮微调。结果表明,使用稀疏卷积能够有效提高掩蔽特征表示学习的质量。
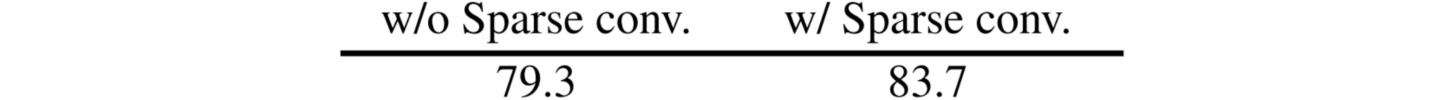
将FCMAE与监督学习进行比较,有监督训练$100$轮的精度是$82.7\%$,有监督训练$300$轮的精度是$83.8\%$,FCMAE的结果是$83.7\%$。实验结果说明FCMAE预训练提供了比随机基准更好的初始化 ($82.7→83.7$),但仍然不如监督训练的最佳性能。
2. ConvNeXt V2
为了进一步提高卷积网络的自监督学习性能,作者设计了新的卷积网络结构。对于训练中使用的ConvNeXt网络,经过掩蔽预训练后出现特征collapse现象,即有许多未激活的或饱和的特征映射,特征通道之间冗余性较大。

为了进一步分析特征collapse现象,作者计算了不同卷积层中特征$X$的不同通道之间的成对余弦距离:
\[\frac{1}{C^2} \sum_i^C \sum_j^C \frac{1-\cos(X_i,X_j)}{2}\]余弦距离越大,表明特征的多样性越强;反之特征的冗余性越强。结果表明,FCMAE预训练的ConvNeXt模型表现出明显的特征collapse趋势。

为了缓解特征collapse问题,作者设计了全局响应归一化 (Global Response Normalization, GRN),用于提高特征通道的对比度和多样性。
GRN通过一个全局聚合函数$G(\cdot)$把输入特征聚合成一个通道维度的向量:
\[G(X) := X \in \Bbb{R}^{H\times W\times C} \to \Bbb{R}^{ C}\]然后通过一个特征归一化函数$N(\cdot)$把通道的统计信息进行归一化,计算其相对于所有其他通道的相对重要性:
\[N(||X_i||) := ||X_i|| \in \Bbb{R} \to \Bbb{R}\]全局聚合函数$G(\cdot)$和特征归一化函数$N(\cdot)$的选择如下:

然后使用计算出的特征归一化分数校准原始输入特征:
\[X_i = X_i * N(G(X)_i)\in \Bbb{R}^{H\times W}\]并进一步引入两个可学习参数$\gamma,\beta$,以及输入的残差连接:
\[X_i = \gamma * X_i * N(G(X)_i) + \beta + X_i\]基于GRN,作者改进了ConvNeXt模块,即在每个模块最后一个$1\times 1$卷积层之前使用GRN:

结果表明,FCMAE和ConvNeXt V2配合的结果显著优于有监督训练结果。



