PGGAN: 渐进生成高质量、多样性的图像.
本文提出了训练生成对抗网络的渐进生成(Progressive Growing)方法,通过逐渐地增大生成图像的分辨率获得更高质量的生成图像。此外作者还讨论了一种增加生成图像多样性的方法:小批量标准偏差(minibatch standard deviation)。
1. Progressive Growing
渐进式的学习过程是从低分辨率图像开始生成,通过向网络中添加新的层逐步增加生成图像的分辨率。该种方法主观上允许模型首先学习图像分布的整体结构特征(低分辨率),然后逐步学习图像的细节部分(高分辨率)。

从低分辨率转换为高分辨率时,由于新加入的网络层是随机初始化的,为防止它们对已经训练过的网络层产生副作用,作者引入了渐进的学习过程(fade in)。通过线性变化($0 \to 1$)的权重$\alpha$避免网络突然崩溃。

下面给出PGGAN在生成$1024$分辨率图像时所采用的的网络结构。
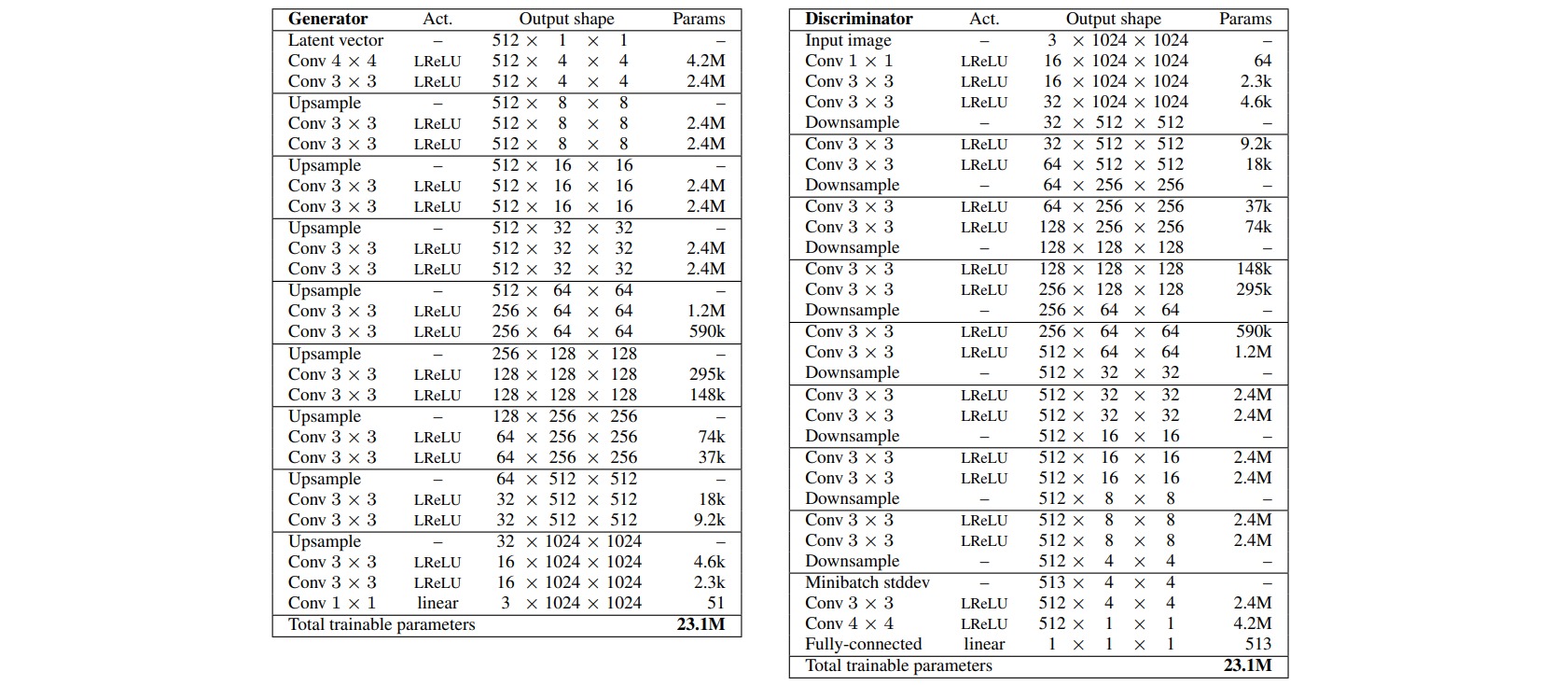
以两阶段渐进生成($4 \times 4 \to 8 \times 8$)为例,PGGAN的实现过程如下:
class Generator(nn.Module):
def __init__(self, latent_dim=512):
super(Generator, self).__init__()
self.latent_dim = latent_dim
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear',align_corners=False)
self.mlp = nn.Linear(latent_dim, latent_dim*4*4)
self.b1, self.b1_rgb, _ = self._get_block(latent_dim, 512)
self.b2, self.b2_rgb, self.p2 = self._get_block(512, 256)
def _get_block(in_channels, out_channels):
block = nn.Sequential([
nn.ConvTransposed2d(in_channels, out_channels, 3, 1, 1),
nn.InstanceNorm2d(out_channels),
nn.LeakyReLU(0.1),
nn.ConvTransposed2d(out_channels, out_channels, 3, 1, 1),
nn.InstanceNorm2d(out_channels),
nn.LeakyReLU(0.1),
])
to_rgb = nn.Sequential([
nn.Conv2d(out_channels, 3, 1, 1, 0),
nn.Tanh(),
])
project = nn.Conv2d(in_channels, out_channels, 1, 1, 0) # 调整通道数
return block, to_rgb, project
def forward(self, inputs):
current_layer, alpha, x = inputs
x = self.self.mlp(x)
x = x.view(-1, self.latent_dim, 4, 4)
x = self.b1(x)
x_lr = self.b1_rgb(x)
x_hr = self.b1_rgb(x)
if current_layer >= 1:
x = self.upsample(x)
x_lr = self.b2_rgb(self.p2(x))
x = self.b2(x)
x_hr = self.b2_rgb(x)
x = x_hr * alpha + x_lr * (1 - alpha)
return x
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.b2_rgb, self.b2 = self._get_block(256, 512)
self.b1_rgb, self.b1 = self._get_block(512, 512)
self.downsample = nn.MaxPool2d(2)
self.tail = nn.Sequential([
nn.Conv2d(512, 512, 4, 1, 0),
nn.Flatten(),
nn.Linear(512, 1)
nn.Sigmoid(),
])
def _get_block(in_channels, out_channels):
from_rgb = nn.Sequential([
nn.Conv2d(3, in_channels, 3, 1, 1),
nn.LeakyReLU(),
])
block = nn.Sequential([
nn.Conv2d(in_channels, out_channels, 3, 1, 1),
nn.InstanceNorm2d(out_channels),
nn.LeakyReLU(0.1),
nn.Conv2d(out_channels, out_channels, 3, 1, 1),
nn.InstanceNorm2d(out_channels),
nn.LeakyReLU(0.1),
])
return from_rgb, block
def forward(self, inputs):
current_layer, alpha, x = inputs
x_lr = self.downsample(x)
if current_layer >= 1:
if current_layer == 1:
x = self.b2_rgb(x)
x = self.b2(x)
x = self.downsample(x)
if current_layer == 1:
x_lr = self.b1_rgb(x_lr)
x = x_hr * alpha + x_lr * (1 - alpha)
if current_layer == 0:
x = self.b1_rgb(x)
x = self.b1(x)
x = self.tail(x)
return x
2. Minibatch Standard Deviation
为了增加生成图像的多样性,作者提出了小批量标准偏差(minibatch standard deviation)方法,该方法受Minibatch discrimination启发,通过在判别器的隐层特征中额外构造不同样本之间的数据分布特征,来显式地判断生成的图像距离是否足够的 ‘接近’。
对于判别器中的特征张量$f \in \Bbb{R}^{N \times C \times H \times W}$,计算不同数据之间的标准偏差$\sigma \in \Bbb{R}^{1 \times C \times H \times W}$,对其平均后构造一个常数$s \in \Bbb{R}$,并将其复制为张量$S \in \Bbb{R}^{N \times 1 \times H \times W}$,作为额外的特征增加到原始特征中。
def minibatch_std(x):
batch_statistics = (
torch.std(x, dim=0).mean().repeat(x.shape[0], 1, x.shape[2], x.shape[3])
)
# we take the std for each example (across all channels, and pixels) then we repeat it
# for a single channel and concatenate it with the image. In this way the discriminator
# will get information about the variation in the batch/image
return torch.cat([x, batch_statistics], dim=1)


