训练生成对抗网络的改进技巧.
1. GAN在训练时遇到的问题
GAN由判别器$D$和生成器$G$组成,其目标函数为:
\[\begin{aligned} \mathop{ \min}_{G} \mathop{\max}_{D} L(G,D) & = \Bbb{E}_{x \text{~} P_{data}(x)}[\log D(x)] + \Bbb{E}_{z \text{~} P_{Z}(z)}[\log(1-D(G(z)))] \\ & = \Bbb{E}_{x \text{~} P_{data}(x)}[\log D(x)] + \Bbb{E}_{x \text{~} P_{G}(x)}[\log(1-D(x))] \end{aligned}\]GAN在训练时进行两人非合作博弈(non-cooperative)。在基于梯度下降的优化过程中,判别器和生成器独立地优化各自的损失,在博弈中没有考虑到另一方。同时更新两个模型的梯度不能保证收敛。
通常梯度下降算法只有在目标函数为凸函数时才能保证实现纳什均衡。下面给出一个非凸函数的例子。
假设一个模型的目标函数为最小化$f(x) = xy$,另一个模型的目标函数为最大化$g(y)=xy$。前一个模型的梯度为$\nabla_xf(x)=y$,因此当$y$增大时$x$的取值应该减小;后一个模型的梯度为$\nabla_yg(y)=x$,因此当$x$减小时$y$的取值应该减小。
不难发现上述两个更新过程互相矛盾,因此每次梯度更新都会引起巨大的振荡,并且这种不稳定性随着更新次数的增加而增大。

2. 改进GAN的训练过程
(1) 特征匹配 feature matching
特征匹配旨在检测生成器的输出是否与真实样本的预期统计值相匹配。引入如下损失函数:
\[| \Bbb{E}_{x \text{~} P_{data}(x)}[f(x)] - \Bbb{E}_{z \text{~} P_{Z}(z)} [f(G(z))] |_2^2\]其中$f(x)$可以指带特征的任意统计量,比如均值或中位数。
(2) 小批量判别 minibatch discrimination
小批量判别旨在使得判别器了解一批样本中所有数据点之间的关系,而不是独立地处理每一个样本,从而增加生成图像的多样性。
在处理一批样本时,近似计算每对样本之间的近似程度$c(x_i,x_j)$,并通过对每个样本与同一批次中其他所有样本的近似程度求和来计算该样本的总体平均近似程度:
\[o(x_i) = \sum_j c(x_i,x_j)\]其中近似程度$c(x_i,x_j)$是通过图像$x_i,x_j$在判别器中某一层特征$f(x_i),f(x_j)$计算得到的。将特征展开为特征向量$f \in \Bbb{R}^{A}$,通过与一个可学习的张量$T \in \Bbb{R}^{A \times B \times C}$相乘后得到矩阵$M \in \Bbb{R}^{B \times C}$。然后近似程度$c(x_i,x_j)$计算为:
\[c(x_i,x_j) = \exp(-||M_i-M_j||_{L_1})\]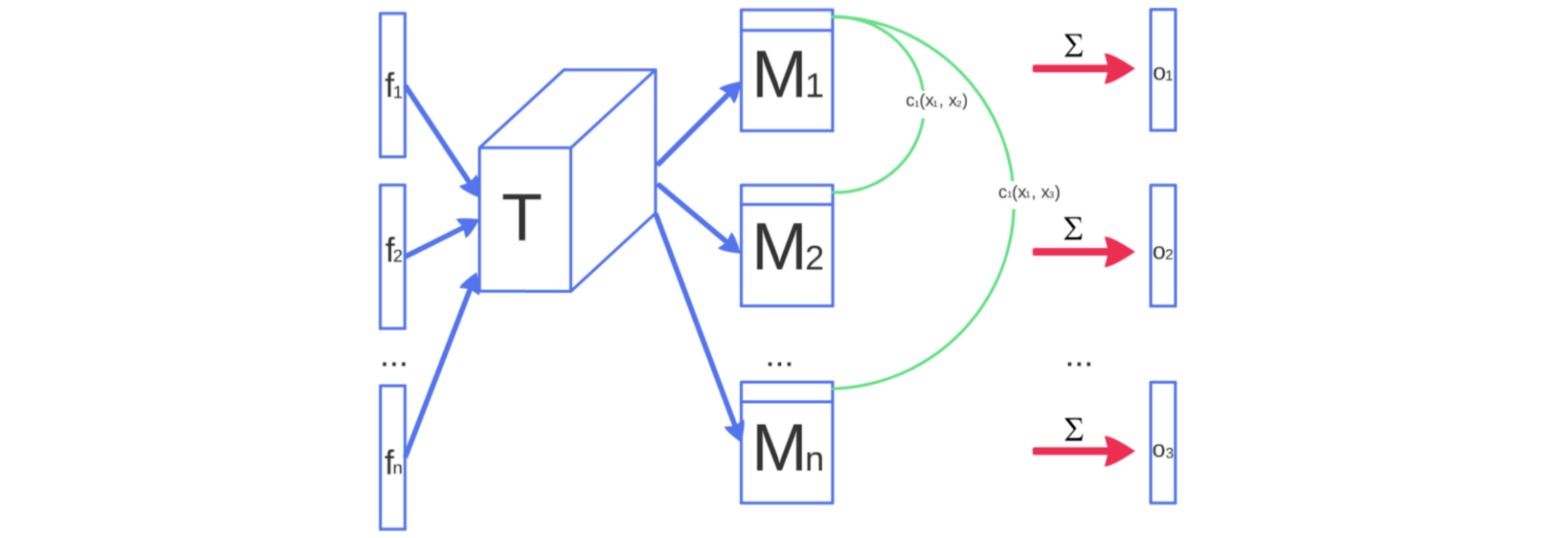
$o(x_i)$被显式地添加到判别器对应的特征中(通过concatenate)。
(3) 历史平滑 historical averaging
历史平滑是指对生成器和判别器的参数都增加以下损失项:
\[|\Theta - \frac{1}{t}\sum_{i=1}^t \Theta_i|^2\]这个损失项强迫模型参数$\Theta$接近过去训练过程中的历史平均参数,当参数发生剧烈变化时会惩罚训练速度。
(4) 标签平滑 label smoothing
标签平滑是指判别器的标签不设置为$0$和$1$,而是设置为$0.1$和$0.9$之类的软标签,以此降低模型的脆弱性。
(5) 虚拟批归一化 virtual batch normalization
虚拟批归一化是指在进行批归一化时不使用每一个批次的统计量,而是使用一个固定批次(称为参考批次,reference batch)的统计量进行归一化。
参考批次在训练开始时选定,在之后的训练过程中不再改变。


