RepPoints:目标检测中的点集表示.
矩形bbox表示方法非常多,常用的可以是xywh代表中心点和宽高,也可以x1y1x2y2,代表左上和右下点坐标。这些bbox表示方式过于粗糙(bbox内部所有点都表征该bbox),无法表示不同物体形状和姿态,采用这种方式进行特征提取会带来大量噪声和无关背景,最终导致性能下降。
针对这种情况,作者提出了采用语义关键点来表征bbox。设每个bbox最多需要$9$个语义点,这$9$个关键点是物体独有语义点,会分布在目标的语义位置。假设对数据采用了$9$个语义点的标注方法,那么在网络训练过程中,可以采用CenterNet做法,head分成$2$个分支输出,第一个分支输出是中心点回归热图,第二个分支输出$18$个通道的$9$个语义点坐标。

$9$个语义点的表示方法看起来会比xywh和x1y1x2y2更加靠谱,但是因为不同物体$9$个语义点标注方式很难确定,而且标注工作量太大了的原因,直接标注是肯定不行的。本文的核心亮点就在于仅仅需要原始bbox标注的监督就可以自动学习出$9$个语义点坐标。为了能够对$9$个语义点坐标进行弱bbox监督训练,作者提出了转换函数$T$即将预测的$9$个语义点通过某个可微函数转换得到bbox,然后对预测bbox进行Loss监督即可。
1. 网络结构
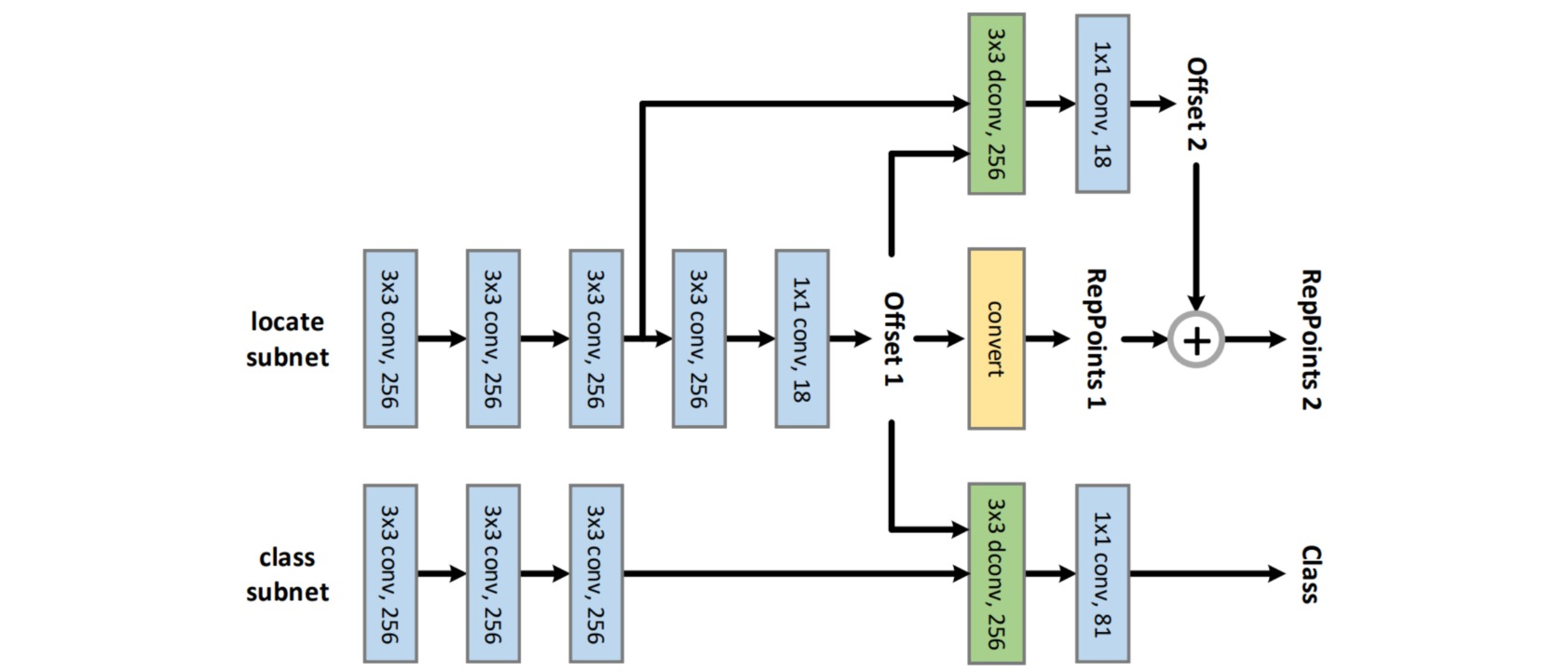
整体算法流程如图所示,是采用多阶段refine方式。其核心思想是:对特征图上面任何一点都学习出$9$个语义关键点坐标offset,同时将offset解码和转换得到原始bbox,即可进行bbox监督了;然后将预测输出offset作为可变形卷积的offset输入进行特征重采样捕获几何位置得到新的特征图;最后对该特征图进行分类和下一步offset精细refine即可,第二步refine分支输出的是相对于第一阶段offset $9$个点的偏移值。

FPN模块输出是5个不同大小的特征图,都需要经过同一个head网络进行分类和回归。head模块输出3个分支:分类分支、初始表征点回归分支和refine表征点回归分支。
- 对FPN输出的某个特征图,分成分类特征图和回归特征图两条分支,然后分别经过3个卷积进行特征提取
- 对pts_feat进行3x3+1x1的卷积,输出通道为$18$的offset,即特征图上每个点都回归$9$个语义点的xy坐标
- 初始pts_out_init分支梯度乘上系数$0.1$,目的是希望降低该分支的梯度权重
- 利用offset预测值,减掉每个特征图上kernel所对应的$9$个点base坐标作为dcn的offset输入值
- 应用dcn对分类分支和refine回归分支进行特征自适应,得到新的特征图,然后经过两个1x1卷积得到最终输出,分类分支cls_out输出通道是num_class,而refine回归分支pts_out_refine是$18$
- refine加上初始预测就可以得到refine后的输出$9$个点坐标
2. 训练细节
(1)正负样本定义
在得到cls_out, pts_out_init, pts_out_refine输出后,需要对每个特征图位置的三个输出分支都定义正负样本。
⚪ pts_out_init的标签分配
对于回归问题而言,其仅仅是对正样本进行训练即可。pts_out_init分支采用的正负样本分配配置为PointAssigner,其核心操作是:遍历每个gt bbox,将该gt bbox映射到特定特征图层,其中心点所处位置即为正样本,其余位置全部忽略。
① 计算gt bbox宽高落在哪个尺度,公式为:
\[s(B) = \lfloor \log_2(\sqrt{w_Bh_B}/4) \rfloor\]gt_bboxes_lvl = ((torch.log2(gt_bboxes_wh[:, 0] / scale) +
torch.log2(gt_bboxes_wh[:, 1] / scale)) / 2).int()
points_lvl = torch.log2(points_stride).int()
lvl_min, lvl_max = points_lvl.min(), points_lvl.max()
gt_bboxes_lvl = torch.clamp(gt_bboxes_lvl, min=lvl_min, max=lvl_max)
② 遍历每个gt bbox,找到其所属的特征图层;为了通用性,先计算特征图上任何一点距离gt bbox中心点坐标的距离;然后利用topk算法选择出前pos_num个距离gt bbox最近的特征图点,这pos_num个都算正样本。
points_gt_dist = ((lvl_points - gt_point) / gt_wh).norm(dim=1)
min_dist, min_dist_index = torch.topk(
points_gt_dist, self.pos_num, largest=False)
min_dist_points_index = points_index[min_dist_index]
③ 还需要特别考虑的是:假设topk的k为1,也就是仅仅gt bbox落在特征图的位置为正样本,假设有两个gt bbox的中心点重合且映射到同一个输出层,那么会出现后遍历的gt bbox覆盖前面gt bbox;对于这类样本的处理办法是其距离哪个gt bbox中心最近就负责预测谁。
less_than_recorded_index = min_dist < assigned_gt_dist[
min_dist_points_index]
min_dist_points_index = min_dist_points_index[
less_than_recorded_index]
assigned_gt_dist[min_dist_points_index] = min_dist[
less_than_recorded_index]
⚪ pts_out_refine的标签分配
第二阶段offset回归采用MaxIoUAssigner,输入是经过第一个阶段预测的offset解码还原后的初始bbox和gt bbox,然后基于最大iou原则定义正负样本。
⚪ cls_out的标签分配
分类分支采用的第二阶段offset回归里面的MaxIoUAssigner准则。
(2)边界框编解码
为了能够对预测的$9$个语义点坐标进行loss监督,需要将$9$个语义点坐标转化得到bbox,作者提出三种做法,性能非常类似:minmax、partial_minmax和moment。
- minmax:对$9$个offset沿xy方向的最大和最小构成bbox
- partial_minmax:仅仅选择前$4$个点进行minmax操作
- moment:通过这$9$个点先求均值得到xy方向的均值即为gt bbox的中心坐标;对$9$个点求标准差操作然后通过可学习的transfer参数进行指数还原:
# 均值和方差就是gt bbox的中心点
pts_y_mean = pts_y.mean(dim=1, keepdim=True)
pts_x_mean = pts_x.mean(dim=1, keepdim=True)
pts_y_std = torch.std(pts_y - pts_y_mean, dim=1, keepdim=True)
pts_x_std = torch.std(pts_x - pts_x_mean, dim=1, keepdim=True)
# self.moment_transfer也进行梯度增强操作
moment_transfer = (self.moment_transfer * self.moment_mul) + (
self.moment_transfer.detach() * (1 - self.moment_mul))
moment_width_transfer = moment_transfer[0]
moment_height_transfer = moment_transfer[1]
# 解码代码
half_width = pts_x_std * torch.exp(moment_width_transfer)
half_height = pts_y_std * torch.exp(moment_height_transfer)
bbox = torch.cat([
pts_x_mean - half_width, pts_y_mean - half_height,
pts_x_mean + half_width, pts_y_mean + half_height
],dim=1)


