Sparse R-CNN:基于可学习提议的端到端目标检测.
目标检测方法的稀疏性定义为最后的分类和回归分支面对的候选roi是密集还是稀疏的。one-stage算法将密集anchor认为是候选roi,故其属于dense做法,而faster rcnn由于有RPN来提取稀疏的roi,故属于dense-to-sparse类算法。本文直接定义$N$个稀疏的可学习的roi,然后直接通过fast rcnn进行端到端训练,故称为Sparse RCNN。

fast rcnn整体测试流程:
- 对原始图片使用SS或者RPN算法得到约2k候选roi
- 将任意大小的图片输入CNN,得到输出特征图
- 在特征图中找到每一个roi对应的特征框,通过RoI pool将每个特征框池化到统一大小
- 统一大小的特征框经过全连接层得到固定大小的特征向量,分别进行softmax分类和bbox回归
Sparse RCNN通过网络联合直接学出来roi,不需要专门的RPN网络,不需要后处理和nms,并且省略了正负样本定义+正负样本采样过程。大概训练流程是:
- 通过嵌入指定的$N$个可学习候选框Proposal Boxes来提供roi坐标
- 通过嵌入指定的$N$个可学习实例级别特征Proposal Features来提供更多的物体相关信息,例如姿态和形状等等
- 将任意大小的图片输入CNN,得到输出特征图
- 在特征图中找到每一个roi对应的特征框,通过RoI pool将每个特征框池化到统一大小
- roi所提特征和Proposal Features计算交叉注意力,增强前景特征
- 统一大小的特征框经过全连接层得到固定大小的特征向量,输出$N$个无序集合,每个集合元素包括分类和bbox坐标信息
- 采用cascade rcnn级联思想,对输出的bbox进行refine,得到refine后的bbox坐标
- 每个级联阶段的输出信息都利用匈牙利双边匹配+分类回归loss进行训练
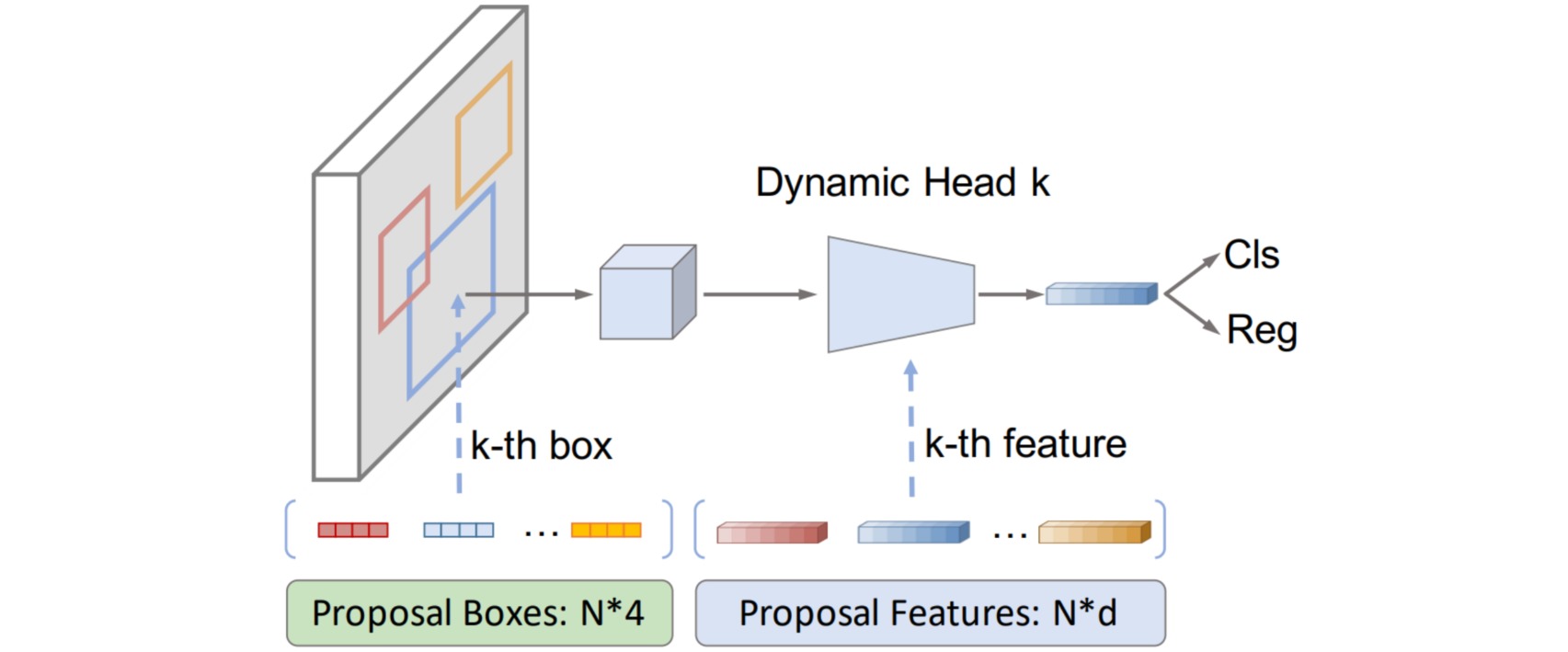
1. Proposal Boxes
可学习Proposal Boxes维度是$(N,4)$,用于代替RPN层,$N$是每张图片中最多的物体总数(coco数据集中最多大概是$63$个物体),$N$的取值对性能有一定影响,本文考虑计算效率设置的是$300$。
其中4维含义表示roi框,表示方式有很多种,作者采用了图片尺度的归一化$c_xc_ywh$值,范围是$0-1$。具体实现上通过Embedding层实现:
#self.num_proposals为超参,默认是300,内部权重是(300,4)
self.init_proposal_boxes = nn.Embedding(self.num_proposals, 4)
nn.init.constant_(self.init_proposal_boxes.weight[:, :2], 0.5)
nn.init.constant_(self.init_proposal_boxes.weight[:, 2:], 1.0)
# 为啥用nn.Embedding,在本文中其实和以下语句是同一个意思
self.init_proposal_boxes = nn.Parameter(torch.Tensor(self.num_proposals, 4))
注意self.init_proposal_boxes不包括batch信息,也就是说这个$(N,4)$矩阵存储的不是当前一张图片信息,而是整个数据集相关的统计roi信息(非常类似注意力机制中的Keys作用),然后通过后续可学习层能够提取出本图片中真正的$N$个roi区域。
可学习Proposal Boxes主要用于提供粗糙roi表征,否则RCNN算法无法切割出roi特征图(two-stage算法必须要提供roi给rcnn部分进行refine)。 RPN输出的roi主要目的是提供丰富的候选框,保证召回率即可,roi不需要很准确,故作者觉得采用一个合理的和数据集相关的统计信息就可以提供足够的候选框,从而采用可学习的proposal boxes代替RPN是完全合理的。
proposal boxes初始化设置对最终结果影响很小:
- center初始化表示都定位到图片中心,wh全部设置为$0.1$,也就是全部初始化为$(0.5,0.5,0.1,0.1)$
- Image初始化表示所有roi都初始化为图像大小即$(0.5,0.5,1,1)$
- Grid初始化表示roi按照类似anchor一样密集排列在原图上
- Random初始化表示采用高斯分布随机初始化

2. Proposal Features
可学习Proposal Features维度是$(N,256)$,$N$是每张图片中最多的物体总数,$256$是超参表示每个roi实例独有的嵌入信息,其实现和Proposal Boxes一致。
#(300,256)
self.init_proposal_features = nn.Embedding(self.num_proposals, self.hidden_dim)
仅仅靠4d的proposal boxes提供的roi太过粗糙,无法表征例如物体姿态和形状,为了提高精度很有必要额外输入一个高维度的proposal feature,其目的是希望通过可学习维度嵌入提供$N$个实例的独特统计信息。
3. Dynamic Instance Interaction
rcnn head利用输入的proposal boxes在特征图上切割,然后采用RoI Align层统一输出大小,最后通过2个fc层进行分类和bbox回归。
rcnn head输入除了proposal boxes切割的输出特征图,还包括额外的proposal feature,故作者插入了一个新的模块:动态实例级可交互模块。该模块主要作用是将roi特征和proposal feature进行实例级的可交互计算,从而突出对前景贡献最大的若干个的输出值,从而最终影响物体的位置和分类预测;如果确实是背景,则相当于没有高输出值。

暂时不考虑batch,假设RoI Align输出shape是$(300,7,7,256)$,$300$是proposal个数,$7\times 7$是切割后统一输出特征图大小,$256$是表示每个特征空间位置的表征向量,而proposal feature的shape是$(300,256)$。采用空间注意力机制,把$(300,7,7,256)$的roi特征和$(300,256,1)$的proposal feature进行矩阵乘法,输出是$(300,7\times 7,1)$,其表示将$256$维度的proposal feature向量和空间$7\times 7$的每个roi特征$256$维度向量计算相似性,得到相似性权重,该权重可以表征空间$7\times 7$个位置中哪些位置才是应该关心的,并该权重作用到原始的$(300,7,7,256)$上。
def forward(self, pro_features, roi_features):
'''
pro_features: (1, N * nr_boxes, self.d_model)
roi_features: (49, N * nr_boxes, self.d_model)
'''
features = roi_features.permute(1, 0, 2) # (bxN,49,256)
# self.dynamic_layer就是fc层
# (1, b * N, 256)-->(1, bxN, 2x64x256)-->(bxN,1,2x64x512)
parameters = self.dynamic_layer(pro_features).permute(1, 0, 2)
# 切分数据
# (bxN,1,2x64x512)-->(bxN,1,64x512)-->(bxN,256,64)
param1 = parameters[:, :, :self.num_params].view(-1, self.hidden_dim, self.dim_dynamic)
# (bxN,1,2x64x512)-->(bxN,1,64x512)-->(bxN,64,256)
param2 = parameters[:, :, self.num_params:].view(-1, self.dim_dynamic, self.hidden_dim)
# 实例级别(bxN)交叉注意力计算,计算roi特征和Proposal Features的空间注意力
# (bxN,49,256) x (bxN,256,64)-->(bxN,49,64) # 每个位置输出都是64维度
features = torch.bmm(features, param1)
...
# 实例级别交互,再算一遍,从而保存维度不变
# (bxN,49,64) x (bxN,64,256)-->(bxN,49,256)
# 得到49个格子上不同的空间权重
features = torch.bmm(features, param2)
...
# (bxN,49x256)
features = features.flatten(1)
# fc层变成(bxN,256)输出
features = self.out_layer(features)
...
4. 级联refine
为了进一步提高性能,作者还提出了cascade rcnn类似的refine回归思想,就是迭代运行n个stage,每个stage都是一个rcnn模块,参数是不共享的,下一个stage接受的是上一个stage输出的refine后的roi:
def forward(self, features, init_bboxes, init_features):
inter_class_logits = []
inter_pred_bboxes = []
# 多尺度输出特征图
bs = len(features[0])
# 可学习roi (b,N,4) 其中所有batch维度初始化时候都是相同的
bboxes = init_bboxes # 可学习的proposal boxes
# 可学习特征(N,256)-->(N,b,256)
init_features = init_features[None].repeat(1, bs, 1)
proposal_features = init_features.clone()
# 迭代n次rcnn head
for rcnn_head in self.head_series:
# features是FPN输出特征,bboxes初始化时候是可学习的bbox,后面是预测的bbox
# proposal_features每次都会同一个输入,self.box_pooler是roialign层
class_logits, pred_bboxes, proposal_features = rcnn_head(features, bboxes,
proposal_features,self.box_pooler)
# 中继监督
if self.return_intermediate:
inter_class_logits.append(class_logits)
inter_pred_bboxes.append(pred_bboxes)
# 不断更新roi,类似cascade rcnn思想
# 需要截断,和cascade rcnn一样
bboxes = pred_bboxes.detach()
if self.return_intermediate:
return torch.stack(inter_class_logits), torch.stack(inter_pred_bboxes)



