Generalized Focal Loss V2:学习密集目标检测中可靠的定位质量估计.
Generalized Focal Loss (GFL)提出了对边界框进行一般化的分布表示建模。对于非常清晰明确的目标边界,学习到的分布都很尖锐;而模糊定义不清的边界(如背包的上沿和伞的下沿)它们学习到的分布基本上会平下来,而且有的时候还经常出现双峰的情况。
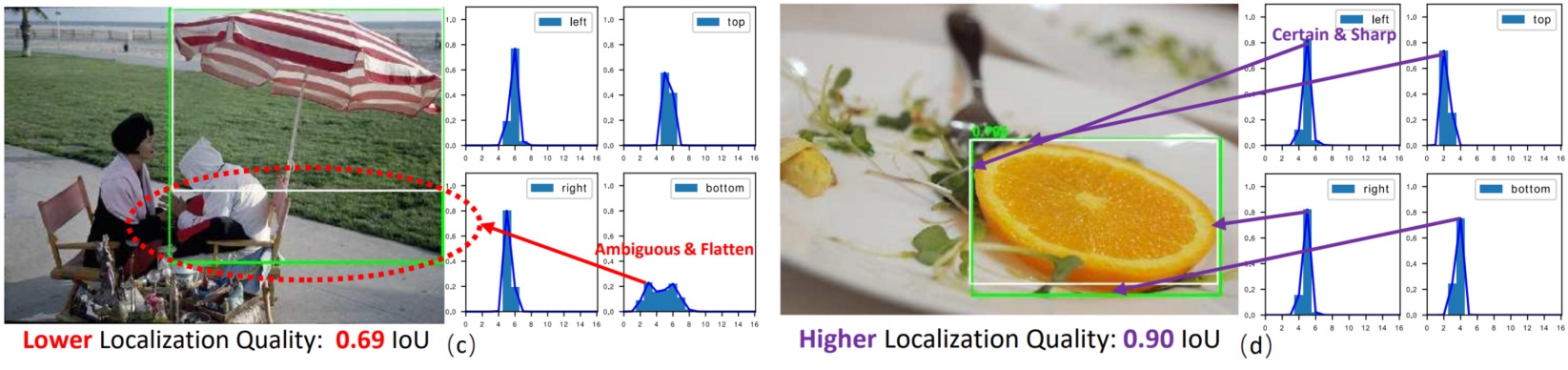
既然分布的形状和真实的定位质量非常相关,可以用能够表达分布形状的统计量去指导最终定位质量的估计。对GFLV1做一些统计分析,具体把预测框的分布的top-1值和其真实的IoU定位质量做了一个散点图:

可以看出整个散点图有一个明显地倾向于$y=x$的趋势的,也就是说,在统计意义上,观察得出的“分布的形状与真实的定位质量具有较强的相关性”这个假设是基本成立的。基于这个分析,可以采用学习到的分布的形状来帮助(协助指导)定位质量估计,从而提升检测的整体性能。
本文采用了一个非常简单的做法来刻画分布的形状,即直接取学习到的分布(分布是用离散化的多个和为$1$的回归数值表示的)的Topk数值。因为所有数值和为1,如果分布非常尖锐的话,Topk这几个数通常就会很大;反之Topk就会比较小。选择Topk还有一个重要的原因就是它可以使得特征与对象的scale尽可能无关。

Distribution-Guided Quality Predictor部分把4条边的分布的Topk concat在一起形成一个维度非常低的输入特征向量,用这个向量再接一个非常小的全连接层(通常维度为$32$、$64$),最后再变成一个Sigmoid之后的scalar乘到原来的分类表征中。
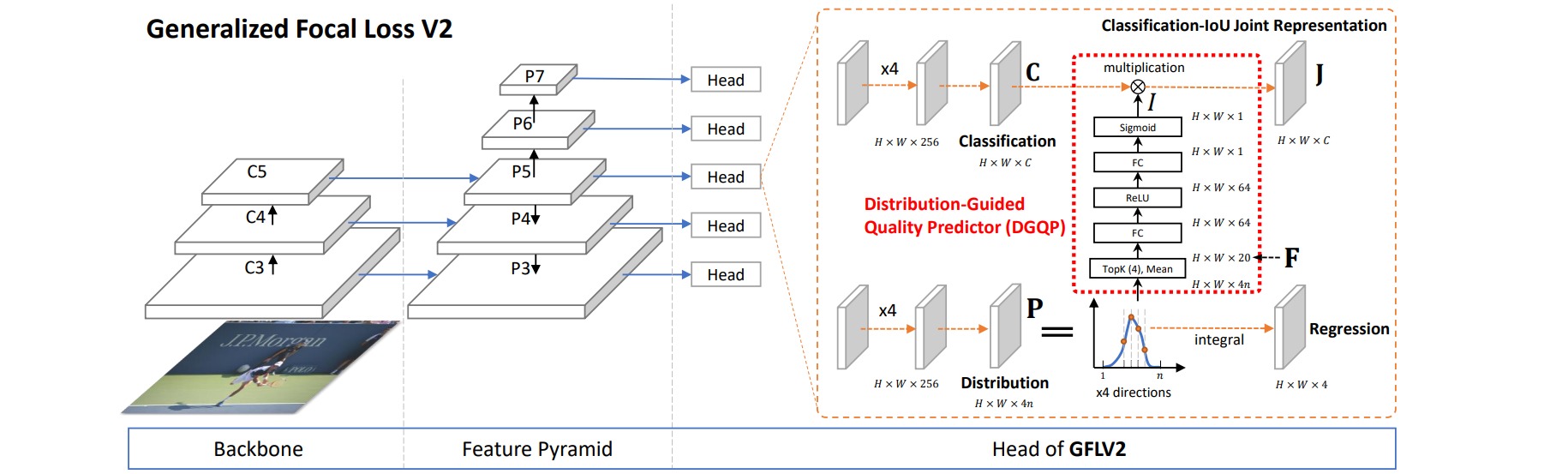
得益于输入(分布的统计量)和输出(定位质量)是非常相关的,所以网络设计也只需要非常的轻量就能够达到很不错的效果。这个模块的引入并不会对训练和测试带来额外的负担,几乎保持了网络训练和测试的效率,同时还能提1~2个AP点。

可视化GFLV2是如何利用好更好的定位质量估计来保障更精准的结果的(给出了NMS前后的所有框,并列出了NMS score排前4的框和它们的分数)。结果表明,其他算法里面也有非常准的预测框,但是它们的score通常都排到了第3第4的位置,而score排第一的框质量都比较欠佳。相反,GFLV2也有预测不太好的框,但是质量较高的框都排的非常靠前。



