GRUU-Net: 细胞分割的融合卷积门控循环神经网络.
在生物医学图像处理中,DL方法已经统治并取代了传统的一些分割方法。而用于分割的这些方法中,工作都是基于卷积神经网络特别是FCN、U-Net等这些网络展开,这也是基于卷积神经网络可以获得不同尺度上的聚合特征的优势所决定的。尤其是U型网络U-Net,已在这个领域中演化出十分多优秀的工作,比如U-Net++、Attention-U-Net等。
在较早的时候,DeepLab通过条件随机场(CRF)来细化结果。在本文中,作者联想到循环神经网络(RNN)也可以实现如CRF的功能。作者发现:
- CNN在捕获层次模式和提取抽象特征方面很有效,但是在分割中,对每个像素点单独分割时,则缺少全局的先验知识(这也是近年来语义分割领域一直在致力解决的问题)。
- 与CNN相反,RNN可以组合多个弱预测结果,使用多个结果先验来进行迭代更新,可以生成更加精确的结果。同时RNN的参数比CNN更少。但是目前还没有RNN用来实现多个尺度上的特征处理。
- 根据上面两点,作者提出了FRDU单元,来实现多个尺度上的CNN和RNN特征聚合。
GRUU-Net模型结构同样基于U-Net,其中主要由FRDU、GRU和Res Block组成。

⚪ GRU:Gated Recurrent Unit

GRU(Gated Recurrent Unit)是循环神经网络的一种,输入前一时刻的状态$\large h^{t-1}$和当前的输入$\large x_t$,得到下一个时刻状态$\large h_t$和输出结果$\large y_t$。由于本文模型需要结合CNN和GRU,而传统意义上的GRU是用来处理序列模型,所以需要把GRU内部的全连接层更改为卷积层。但总体结构上与GRU是一样的。
\[\begin{aligned} z_t & =\sigma\left(W_z x_t+U_z h_{t-1}+b_z\right) \\ r_t & =\sigma\left(W_r x_t+U_r h_{t-1}+b_r\right) \\ \tilde{h}_t & =\text{LReLU} \left(W_h x_t+U_h h_{t-1} \odot r_t+b_h\right) \\ h_t & =z_t \odot h_{t-1}+\left(1-z_t\right) \odot h_t \end{aligned}\]class ConvGRU(nn.Module):
def __init__(self, x_channels=64, channels=32):
super(ConvGRU, self).__init__()
self.channels = channels
self.x_channels = x_channels
self.conv_x_z = nn.Conv2d(in_channels=self.x_channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_h_z = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_x_r = nn.Conv2d(in_channels=self.x_channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_h_r = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv = nn.Conv2d(in_channels=self.x_channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_u = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
#self.conv_out = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.lReLU = nn.LeakyReLU(0.2)
def forward(self, x, h_t_1):
"""GRU卷积流程
args:
x: input
h_t_1: 上一层的隐含层输出值
shape:
x: [in_channels, channels, width, lenth]
"""
z_t = F.sigmoid(self.conv_x_z(x) + self.conv_h_z(h_t_1))
r_t = F.sigmoid((self.conv_x_r(x) + self.conv_h_r(h_t_1)))
h_hat_t = self.lReLU(self.conv(x) + self.conv_u(torch.mul(r_t, h_t_1)))
h_t = torch.mul((1 - z_t), h_t_1) + torch.mul(z_t, h_hat_t)
# 由于该模型中不需要输出y,这里注释掉
#y = self.conv_out(h_t)
return h_t
⚪ FRDU:Full-Resolution Dense Units

FRDU接受了上一个ConvGRU的输出状态$\large h_{t-1}$和上一个FRDU的输出结果$\large o_{t-1}$,需要注意的是,上一个状态$\large h_{t-1}$和$\large o_{t-1}$形状是不同的(主要体现在网络中),ConvGRU在网络的顶层,其大小与输入的形状相同,而$\large o_{t-1}$则在不断的下采样。因此$\large h_{t-1}$需要进行一个下采样来符合$\large o_{t-1}$。
\[o_t=\text { ConvNorm }\left(\text { downsample }\left(h_{t-1}\right)+o_{t-1}\right)\]在特征融合之后,作者设计了一个Dense Block来实现特征处理,对于Dense Block,作者在U型网络的不同层次上设计了不同的Dense layer数量。随后,就有:
\[\begin{aligned} & o_t=\operatorname{Dense}\left(o_t\right) \\ & x_t=\operatorname{ConvNorm}\left(o_t\right) \\ & h_t=\operatorname{ConvGRU}\left(h_{t-1},x_t\right) \end{aligned}\]class FRDU(nn.Module):
def __init__(self, in_channels, channels, factor=2):
super(FRDU, self).__init__()
self.maxpool = nn.MaxPool2d(2)
self.factor = factor
self.convNorm1 = nn.Sequential(
nn.Conv2d(in_channels+32, channels, 1),
nn.BatchNorm2d(channels)
)
self.convNorm2 = nn.Sequential(
nn.Conv2d(channels, channels, 1),
nn.BatchNorm2d(channels)
)
self.denseLayer = DenseNet(k = 3, in_features=channels, out_features=channels, bn_size=2)
self.ConvGRU = ConvGRU(x_channels=channels)
def forward(self, o_t_1, h_t_1):
"""
o_t_t: Ot-1输入
h_t_1: GRU的输出h_t_1
"""
h_t_ori = h_t_1
h_t_1 = F.interpolate(h_t_1 , scale_factor=1/self.factor ,mode='bilinear')
o_t_1 = self.convNorm1(torch.cat([o_t_1, h_t_1], 1))
o_t = self.denseLayer(o_t_1)
x_t = self.convNorm2(o_t)
x_t = F.interpolate(x_t , scale_factor=self.factor ,mode='bilinear')
h_t = self.ConvGRU(x_t, h_t_ori)
return o_t, h_t
⚪ GRUU-Net
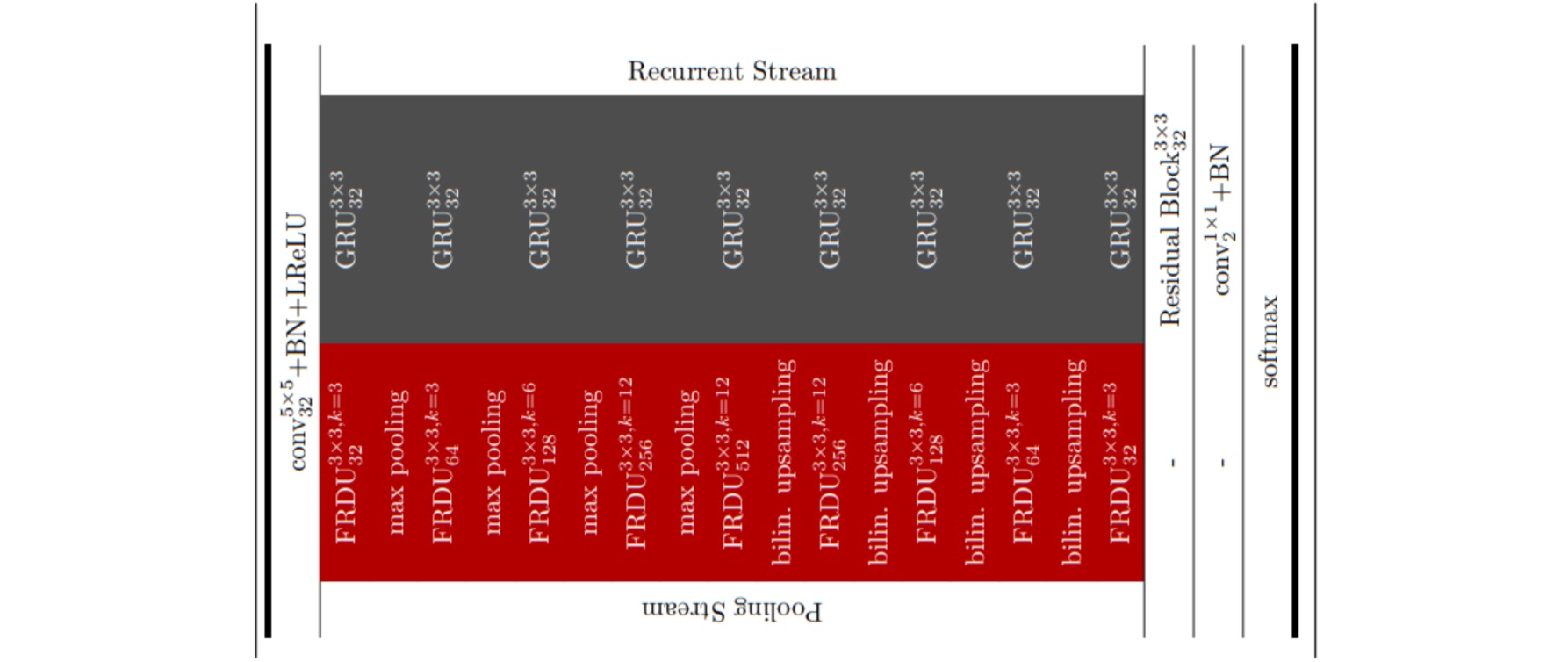
GRUU-Net的输入通过一个$5×5$的Conv来实现,每一次FRDU都接受上一层的maxPool结果,而最上层的GRU的输入输出形状都和原始输入相同,其中通道数固定为32。实际上,GRU已经添加在FRDU模块中。
其余结构类似于U-Net,编码端进行下采样,解码端进行上采样。这里上采样通过双线性插值来实现。最后一个ConvGRU的输出,用一个Res Block来处理结果,通过1×1卷积来实现分割。
class GRUU_Net(nn.Module):
def __init__(self, num_classes=2):
super(GRUU_Net, self).__init__()
self.input = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2)
)
self.FRDU_1 = FRDU(32, 64,factor=2)
self.FRDU_2 = FRDU(64, 128,factor=4)
self.FRDU_3 = FRDU(128, 256,factor=8)
self.FRDU_4 = FRDU(256, 512,factor=16)
self.FRDU_5 = FRDU(512, 512,factor=32)
self.FRDU_6 = FRDU(512, 256,factor=16)
self.FRDU_7 = FRDU(256, 128,factor=8)
self.FRDU_8 = FRDU(128, 64,factor=4)
self.FRDU_9 = FRDU(64, 32,factor=2)
self.Resblock = nn.Sequential(
nn.Conv2d(32, 32, 3, padding=1),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2)
)
self.cls_seg = nn.Conv2d(32, num_classes, 3, padding=1)
def forward(self, x):
x = self.input(x)
#FRDU1:
o_t, h_t = self.FRDU_1(o_t_1 = nn.MaxPool2d(2)(x), h_t_1 = x)
o_t, h_t = self.FRDU_2(o_t_1 = nn.MaxPool2d(2)(o_t), h_t_1 = h_t)
o_t, h_t = self.FRDU_3(o_t_1 = nn.MaxPool2d(2)(o_t), h_t_1 = h_t)
o_t, h_t = self.FRDU_4(o_t_1 = nn.MaxPool2d(2)(o_t), h_t_1 = h_t)
o_t, h_t = self.FRDU_5(o_t_1 = nn.MaxPool2d(2)(o_t), h_t_1 = h_t)
o_t, h_t = self.FRDU_6(o_t_1 = F.interpolate(o_t, scale_factor=2, mode="bilinear"), h_t_1 = h_t)
o_t, h_t = self.FRDU_7(o_t_1 = F.interpolate(o_t, scale_factor=2, mode="bilinear"), h_t_1 = h_t)
o_t, h_t = self.FRDU_8(o_t_1 = F.interpolate(o_t, scale_factor=2, mode="bilinear"), h_t_1 = h_t)
o_t, h_t = self.FRDU_9(o_t_1 = F.interpolate(o_t, scale_factor=2, mode="bilinear"), h_t_1 = h_t)
h_t = self.Resblock(h_t) + h_t
out = self.cls_seg(h_t)
return out


