使用图像级监督检测两万个类别.
限制现阶段目标检测器性能的主要原因是其可获得的训练数据量规模太小。LVIS 120K的图片,包含了1000+类,OpenImages 1.8M的图片,包含了500+类。而图像分类的数据量就相对来说大得多同时更加容易收集。

作者提出了目标检测训练方法Detic,直接使用ImageNet21K的分类图像数据集和目标检测数据集一起,对检测模型进行联合训练。Detic易于实现,在大部分的检测backbone上都可以接入使用。Detic的主要特点:
- 针对现阶段目标检测弱监督训练的问题使用了更简单易用的替换方案。
- 提出一个新的损失函数,使用图像级别的监督信号提升目标检测器的性能。
- 训练出来的目标检测器可以无需微调,直接迁移到新的数据集和检测词汇表上。
常规的弱监督目标检测方法是一种基于预测的label-box分配机制,由RPN获取proposal,然后将每个图像层面类别分配到待定的proposal中,由于缺少区域级别的监督信号,这样的做法很容易产生误差。
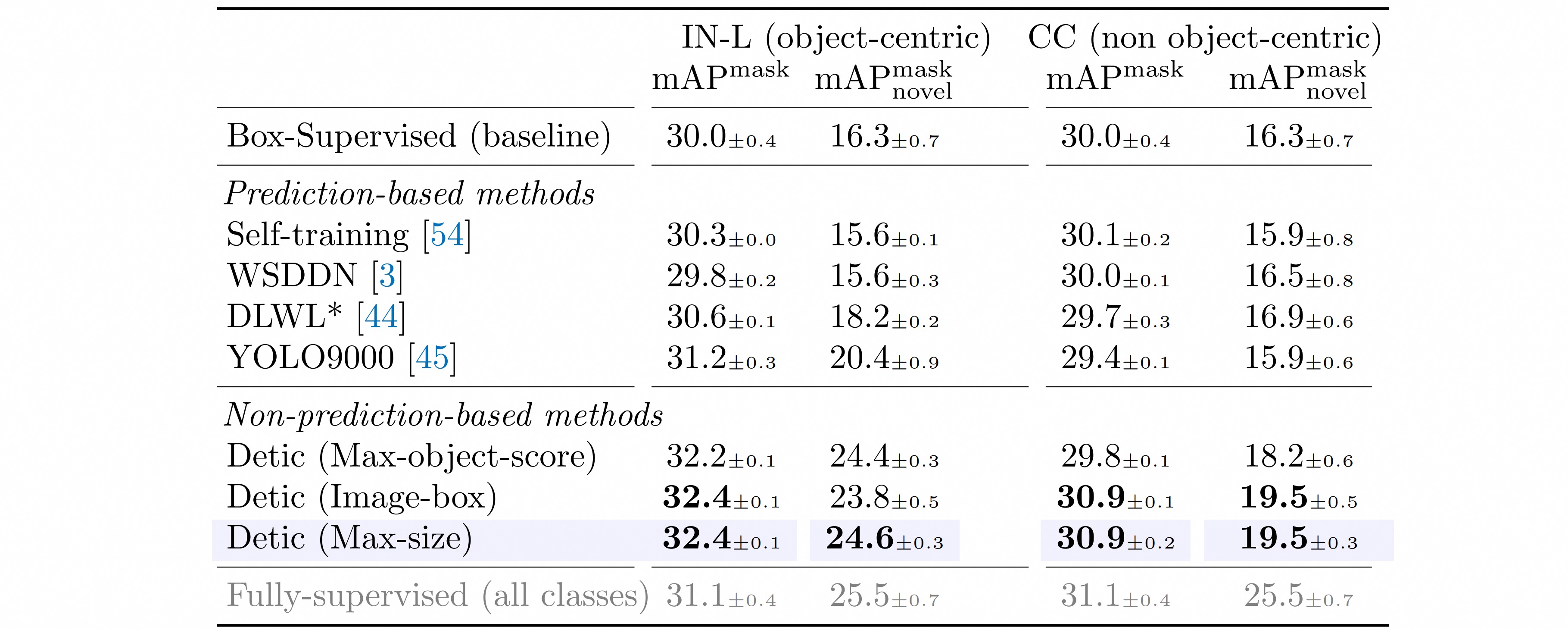
而Detic的做法是选取最大面积的proposal(通常情况下这个proposal几乎包括了整张图片),然后这个proposal对应的label就是整个图像层面的类别。

训练集中包含目标检测数据和ImageNet21K的分类图像数据。如果是检测数据,则直接进行正常的两阶段目标检测流程,Reg Head回归bbox,Classification Head分类。如果是ImageNet21K图像数据,则使用检测器检测Max-size的图像区域并截取,然后送入Classification Head进行分类。通过共享Classification Head实现更多的ImageNet21K中的object concept知识的迁移。
\[L(\mathbf{I})= \begin{cases} L_{\mathrm{rpn}}+L_{\mathrm{reg}}+L_{\mathrm{cls}}, & \mathrm{if~I\in\mathcal{D}}^{\mathrm{det}} \\ \lambda L_{\mathrm{max-size}}, & \mathrm{if~I\in\mathcal{D}}^{\mathrm{cls}} \end{cases}\]作者提出了以下损失函数来让目标检测器可以使用图像级别的标签进行训练:
\[L_{\mathrm{max-size}}=B C E({\bf W f}_{j},c),j=\arg\mathrm{max}_{j}(\mathrm{size}({\bf b}_{j}))\]其中$f$代表proposal对应的RoI feature,c是最大的proposal对应的类别,也就是是该图片对应的类别,$W$是分类器的权重。
Box-Supervised表示只使用传统的目标检测数据进行训练的目标检测器。剩余的训练方法就是其余的使用图像级别的数据来做弱监督训练的目标检测器。从中可以看出使用Detic方法训练出来的目标检测器在各项指标上都获得了最佳成绩。