对齐语言-图像预训练.
本文构建了句子中的短语与图像中的对象之间的细粒度对应关系,提出一种对齐语言-图像预训练方法GLIP(Grounded Language-Image Pre-training)。该方法统一了目标检测与短语对齐任务,把目标检测模型的检测框目标分类得分替换为短语对齐得分,通过大量图像-文本数据扩展视觉概念,能够零样本或少样本迁移到不同下游检测任务中。

在通常的目标检测模型中,模型从图像中提取一系列边界框特征$O\in R^{N\times d}$,再把这些特征通过映射头$W\in R^{c\times d}$映射为类别得分,并进一步构造类别得分(通常是交叉熵):
\[O=Enc_I(Img),S_{cls} = OW^T,L_{cls} = loss(S_{cls};T)\]本文不再把目标检测看作对边界框特征的分类任务,而是把检测看作一个短语对齐(grounding)任务。把检测类别通过'. '连接构造提示:
进一步计算边界框特征$O\in R^{N\times d}$与短语中的单词特征$P\in R^{M\times d}$之间的对齐得分:
\[O=Enc_I(Img), P=Enc_L(Prompt),S_{ground}=OP^T\]在上述过程中,图像特征与文本特征是由单独的编码器分别编码的,之后融合计算对齐分数。本文进一步引入了图像和文本编码器的深度融合。使用DyHead作为图像编码器,BERT作为文本编码器,则构造深度融合编码器:
\[\begin{aligned} & O_{\mathrm{t2i}}^{i},P_{\mathrm{i2t}}^{i}=\text{X-MHA}(O^{i},P^{i}),i\in\{0,1,..,L-1\}\\ &O^{i+1}=\text{DyHeadModule}(O^{i}+O_{t2i}^{i}),O=O^{L}\\ &P^{i+1}=\text{BERTLayer}(P^{i}+P_{i2t}^{i}),P=P^{L} \end{aligned}\]其中$O^0,P^0$分别来自主干视觉网络与预训练语言模型(BERT),通过额外增加$L$个DyHead模块与BERT层实现多模态特征的融合。融合过程是由跨模态多头注意力模块(X-MHA)实现的,每个头通过关注另一个模态来计算该模态的上下文向量:
\[\begin{aligned} &O^{(q)}=O W^{(q,I)},P^{(q)}=P W^{(q,L)},A tt n=O^{(q)}(P^{(q)})^{\top}/\sqrt{d}\\ &P^{(v)}=P W^{(v,L)},\ O_{t2i}=\mathrm{SoftMax}(A tt n)P^{(v)}W^{(o u t,I)}\\ &O^{(v)}=O W^{(v,I)},\ P_{i2t}=\mathrm{SoftMax}(A t t n^{\top})O^{(v)}W^{(o u t,L)} \end{aligned}\]
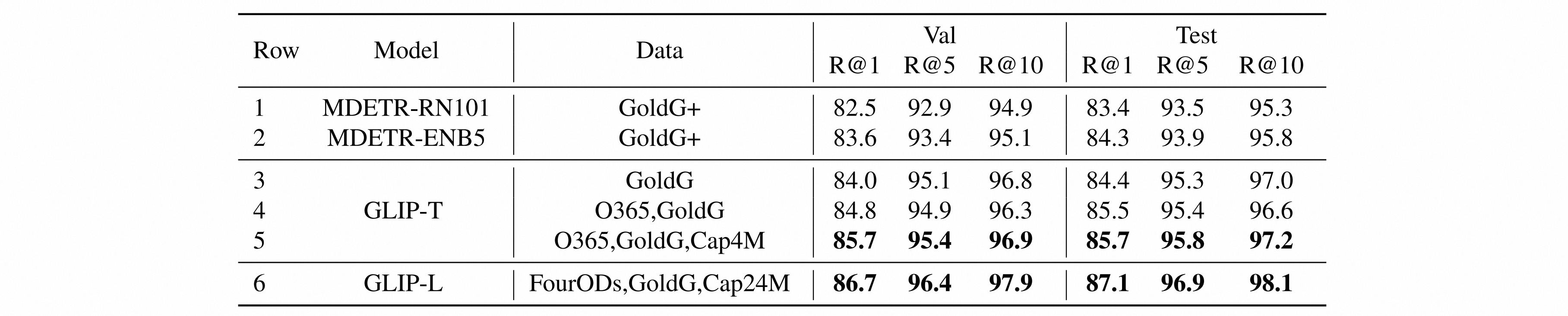
作者训练了五个GLIP的变体以进行结构消融。预训练数据包括检测数据集、短语对齐数据集GoldG与图像描述数据集。测试数据集包括$80$类的检测数据集COCO,超过$1000$类的检测数据集LVIS,短语对齐数据集Flickr30K。

由于Objects365涵盖了COCO中的所有类别,因此模型零样本迁移到COCO后性能超过了监督训练的目标检测模型。

数据集LVIS上的检测结果表示,通过引入文本信息扩展了数据的语义丰富性,能够显著地帮助模型识别长尾物体。

数据集Flickr30K上的结果表示,检测数据的添加有助于短语对齐任务,再次说明两个任务之间具有协同性。
为了评估模型在开集目标检测任务中的迁移性能,作者构造了一个Object Detection in the Wild (ODinW)数据集,该数据集由$13$个不同领域的检测任务数据组成。
在微调模型时作者改变了特定任务的标注数据的数量,从zero-shot(没有提供数据)到X-shot(每个类别提供至少X个标签),再到使用训练集中的所有数据。结果表明,GLIP具有数据高效性,能在显著减少特定任务数据的情况下达到相同的性能。

作者进一步分析了GLIP变体在5个不同数据集上的zero-shot性能。发现引入短语对齐数据对某些测试新概念的任务带来了显着改善,例如在Pothole和EgoHands上,没有短语对齐数据的模型(A&B)表现非常糟糕。

GLIP的输出严重依赖于语言输入,因此作者提出了一种有效的任务迁移的方法:对于任何新的类别,用户可以在文本提示中使用表达性描述,通过添加属性或语言上下文注入领域知识,帮助GLIP迁移。



