Grounding DINO:结合DINO与GLIP用于开集目标检测.
开集目标检测是一种实现通用目标检测的方法,能够检测任意指定的目标。实现开集目标检测的关键是引入语言以泛化到未曾见过的目标。目前大多数开集检测器都是通过把语言信息引入闭集检测器来构造的,具体地,通过构造区域特征(neck或head的输出)与语言特征的对比损失,可以把区域特征嵌入到具有语言感知的语义空间中,从而泛化到新类别中。比如GLIP将目标检测重新定义为一个短语定位(phrase grounding)任务,并引入了目标区域和语言之间的对比训练。

为了更紧密地学习图像与语言之间的多模态特征,有必要在网络的每个阶段都引入对比特征学习过程。然而基于卷积神经网络的目标检测模型中,图像特征与语言特征的对齐是比较困难的。而SOTA的目标检测模型DINO采用Transformer结构,与语言模型的结构具有一致性,因此能够自然地实现两个模态的特征交互。本文把GLIP训练方式引入中DINO,构造了开集目标检测方法Grounding DINO。Grounding DINO通过在Transformer的多个阶段中引入多模态融合手段,在没有任何COCO训练数据的情况下达到52.5的mAP。
1. Grounding DINO
给定输入(图像,文本)对,Grounding DINO输出多个(目标检测框,短语)对。Grounding DINO采用双编码器、单解码器结构,包括用于提取图像特征的图像主干网络、用于提取文本特征的文本主干网络、用于融合图像和文本特征的特征增强模块、用于查询初始化的语言引导的查询选择模块和用于边界框预测的跨模态解码器。
对于输入的每个(图像,文本)对,首先分别使用图像主干网络和文本主干网络提取图像特征和文本特征;两个特征被送入特征增强模块,用于跨模态特征融合;获得跨模态文本和图像特征后,使用语言引导的查询选择模块从图像特征中选择跨模态的目标查询;这些跨模态查询被送到跨模态解码器中,用于预测目标框并提取相应的短语。

(1)特征提取与增强模块
图像主干网络采用Swin Transformer,文本主干网络采用BERT。特征增强模块是由多个特征增强层堆叠而成的。每个特征增强层的结构如上图2处所示,使用可变形自注意力增强图像特征,使用自注意力增强文本特征,并增加图像到文本的交叉注意力以及文本到图像的交叉注意力来进行特征融合。
(2)语言引导的查询选择模块
该模块旨在从图像特征中选择与输入文本更相关的特征作为后续解码器的查询向量。该模块输出$num$个查询索引,可以根据选择的索引提取对应的图像特征对查询向量进行初始化。该模块的实现过程如下:

查询向量的初始化是通过混合查询选择(mixed query selection)来实现的。每个查询包括两个部分:内容(context)部分与位置(positional)部分。其中位置部分由上述编码器的输出初始化;内容部分在训练期间设置为可学习参数。
(3)跨模态解码器
跨模态解码器用于结合图像与文本特征。每个查询向量依次通过自注意力层、图像交叉注意力层(用于组合图像特征)、文本交叉注意力层(用于组合文本特征)和全连接层,结构如图3部分所示。
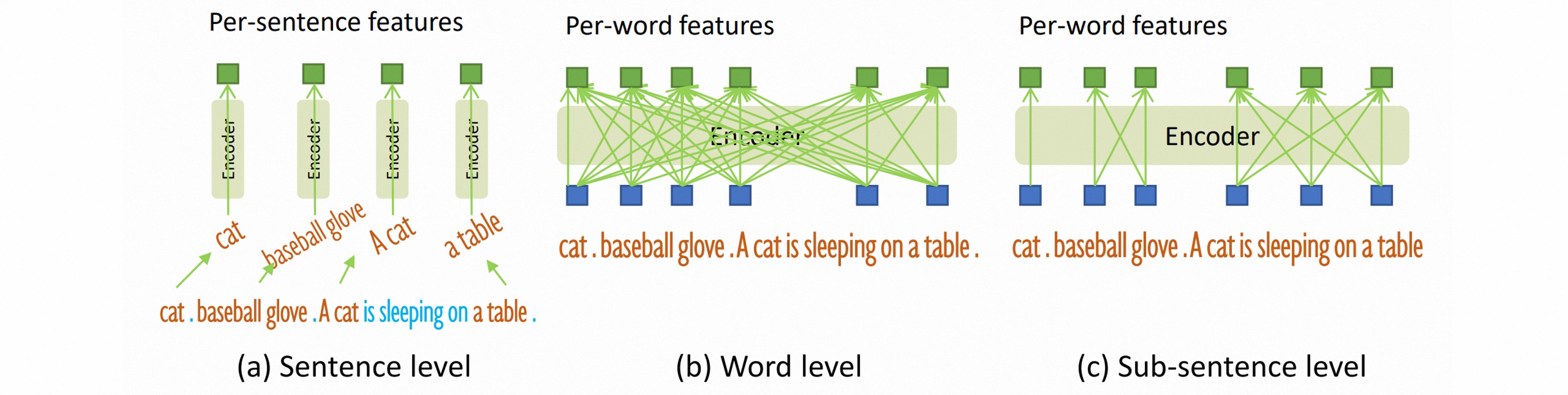
(4)子句级的文本特征
在之前的工作中,文本提示主要有两种形式。
- 第一种是句子级(sentence level)表示,即把表示整个句子编码为一个特征,如果句子中包含多个短语,则分别提取这些短语,并丢弃其他单词,用以消除单词之间的影响,但是也丢失了句子中的细粒度信息;
- 第二种是词级(word level)表示,即把每个单词编码为一个特征,这种编码在类别之间引入了不必要的依赖关系,而输入文本通常是以任意顺序连接的多个类别,本身并不具备这种关系。
本文采用一种子句级(sub-sentence level)表示,引入注意力掩码避免不相关的短语之间的交互,消除不同类别名称之间的影响,同时保留了每个单词的细粒度特征。
(5)损失函数
边界框回归损失采用L1损失+GIoU损失,分类损失采用对比损失,即首先计算每个查询特征与文本特征的点积作为预测每个文本的logit,然后构造Focal损失。
2. 实验分析
作者训练了两个变种模型:
- Grounding DINO-T:DINO-T+Swin-T
- Grounding DINO-L:DINO-L+Swin-L
语言模型采用BERT-base。作者在三个数据集COCO, LVIS, ODinW上检测了模型的开集检测性能。
(1)零样本迁移
作者在大规模数据集上预训练模型,并直接在新数据集上评估模型。在COCO数据集上零样本迁移性能达到52.5 AP,微调后达到62.6 AP。这种强力的零样本表现可能是因为预训练数据集O365几乎包含COCO的所有类别。

在具有$1000$类别的长尾分布数据集LVIS上,模型在尾部类别上的表现较差,这可能是因为设置长度$900$的查询向量限制了对长尾目标的检测能力。

在真实场景中的ODinW数据集上,模型依旧具有最好的零样本迁移表现,表明模型具有良好的通用性和可扩展性。

(2)参考表达式理解任务
参考表达式理解任务(Referring Expression Comprehension,REC)是指输入描述性文本,模型检测文本对应的具体目标。在RefCOCO数据集上,模型在零样本迁移下的性能表现不佳,只有在训练集中涵盖RefCOCO后,性能才有显著的改善。这表明模型仍然更需要关注细粒度的检测特征。

(3)消融实验
消融实验表明编码器融合是最重要的设计,文本提示的词级表示对结果影响最小。



