RTMDet:设计实时目标检测器的经验性研究.
最近一段时间,开源界涌现出了大量的高精度目标检测项目,其中最突出的就是 YOLO 系列。在调研了当前 YOLO 系列的诸多改进模型后,MMDetection 核心开发者针对这些设计以及训练方式进行了经验性的总结,并进行了优化,推出了高精度、低延时的单阶段目标检测器 RTMDet (Real-time Models for Object Detection)。
RTMDet 由 tiny/s/m/l/x 一系列不同大小的模型组成,为不同的应用场景提供了不同的选择。 其中 RTMDet-x 在 52.6 mAP 的精度下达到了 300+ FPS 的推理速度。而最轻量的模型 RTMDet-tiny,在仅有 4M 参数量的情况下也能够达到 40.9 mAP,且推理速度 $< 1$ ms。

1. 数据增强
RTMDet 采用了多种数据增强的方式来增加模型的性能,主要包括单图数据增强:
- RandomResize 随机尺度变换
- RandomCrop 随机裁剪
- HSVRandomAug 颜色空间增强
- RandomFlip 随机水平翻转
以及混合类数据增强:
- Mosaic 马赛克
- MixUp 图像混合

其中 RandomResize 超参在大模型 M,L,X 和小模型 S, Tiny 上是不一样的,大模型由于参数较多,可以使用 large scale jitter 策略即参数为 $(0.1,2.0)$,而小模型采用 stand scale jitter 策略即 $(0.5, 2.0)$ 策略。
与 YOLOv5 不同的是,YOLOv5 认为在 S 和 Nano 模型上使用 MixUp 是过剩的,小模型不需要这么强的数据增强。而 RTMDet 在 S 和 Tiny 上也使用了 MixUp,这是因为 RTMDet 在最后 20 epoch 会切换为正常的 aug, 并通过训练证明这个操作是有效的。 并且 RTMDet 为混合类数据增强引入了 Cache 方案,有效地减少了图像处理的时间, 和引入了可调超参 max_cached_images ,当使用较小的 cache 时,其效果类似 repeated augmentation。
(1) 为图像混合数据增强引入 Cache
Mosaic&MixUp 涉及到多张图片的混合,它们的耗时会是普通数据增强的 $K$ 倍($K$ 为混入图片的数量)。 如在 YOLOv5 中,每次做 Mosaic 时, 4 张图片的信息都需要从硬盘中重新加载。 而 RTMDet 只需要重新载入当前的一张图片,其余参与混合增强的图片则从缓存队列中获取,通过牺牲一定内存空间的方式大幅提升了效率。 另外通过调整 cache 的大小以及 pop 的方式,也可以调整增强的强度。

cache 队列中预先储存了 N 张已加载的图像与标签数据,每一个训练 step 中只需加载一张新的图片及其标签数据并更新到 cache 队列中(cache 队列中的图像可重复,如图中出现两次 img3),同时如果 cache 队列长度超过预设长度,则随机 pop 一张图(为了 Tiny 模型训练更稳定,在 Tiny 模型中不采用随机 pop 的方式, 而是移除最先加入的图片),当需要进行混合数据增强时,只需要从 cache 中随机选择需要的图像进行拼接等处理,而不需要全部从硬盘中加载,节省了图像加载的时间。
cache 队列的最大长度 N 为可调整参数,根据经验性的原则,当为每一张需要混合的图片提供十个缓存时,可以认为提供了足够的随机性,而 Mosaic 增强是四张图混合,因此 cache 数量默认 N=40, 同理 MixUp 的 cache 数量默认为20, tiny 模型需要更稳定的训练条件,因此其 cache 数量也为其余规格模型的一半( MixUp 为10,Mosaic 为20)。
(2) 强弱两阶段训练
Mosaic+MixUp 失真度比较高,持续用太强的数据增强对模型并不一定有益。为了使数据增强的方式更为通用,RTMDet 在前 280 epoch 使用不带旋转的 Mosaic+MixUp, 且通过混入 8 张图片来提升强度以及正样本数。后 20 epoch 使用比较小的学习率在比较弱的增强下进行微调,同时在 EMA 的作用下将参数缓慢更新至模型,能够得到比较大的提升。
2. 模型结构
RTMDet 模型整体结构和 YOLOX 几乎一致,由 CSPNeXt + CSPNeXtPAFPN + 共享卷积权重但分别计算 BN 的 SepBNHead 构成。内部核心模块也是 CSPLayer,但对其中的 Basic Block 进行了改进,提出了 CSPNeXt Block。
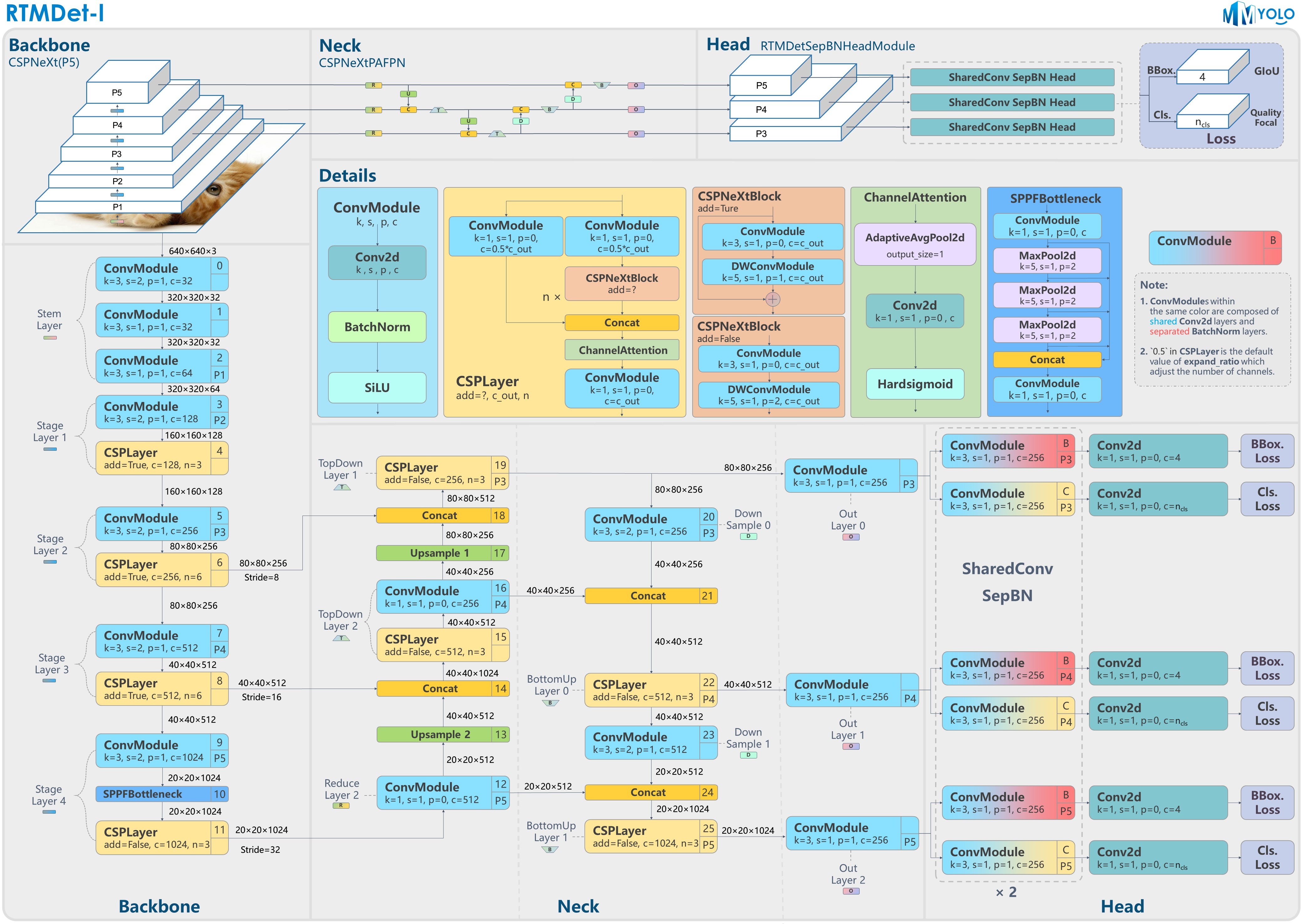
(1)backbone
CSPNeXt 整体以 CSPDarknet 为基础,共 5 层结构,包含 1 个 Stem Layer 和 4 个 Stage Layer:
- Stem Layer 是 3 层 3x3 kernel 的 ConvModule。
- Stage Layer 总体结构与已有模型类似,前 3 个 Stage Layer 由 1 个 ConvModule 和 1 个 CSPLayer 组成。第 4 个 Stage Layer 在 ConvModule 和 CSPLayer 中间增加了 SPPF 模块。
- CSPLayer 由 3 个 ConvModule + n 个 CSPNeXt Block(带残差连接) + 1 个 Channel Attention 模块组成。ConvModule 为 1 层 3x3 Conv2d + BatchNorm + SiLU 激活函数。Channel Attention 模块为 1 层 AdaptiveAvgPool2d + 1 层 1x1 Conv2d + Hardsigmoid 激活函数。
(2)CSPNeXt Block
Darknet (图 a)使用 1x1 与 3x3 卷积的 Basic Block。YOLOv6 、YOLOv7 、PPYOLO-E (图 c & d)使用了重参数化 Block。但重参数化的训练代价高,且不易量化,需要其他方式来弥补量化误差。 RTMDet 则借鉴了最近比较热门的 ConvNeXt 、RepLKNet 的做法,为 Basic Block 加入了大 kernel 的 depth-wise 卷积(图 b),并将其命名为 CSPNeXt Block。

(3)调整检测器不同 stage 间的 block 数
由于 CSPNeXt Block 内使用了 depth-wise 卷积,单个 block 内的层数增多。如果保持原有的 stage 内的 block 数,则会导致模型的推理速度大幅降低。
RTMDet 重新调整了不同 stage 间的 block 数,并调整了通道的超参,在保证了精度的情况下提升了推理速度。
(4)Backbone 与 Neck 之间的参数量和计算量的均衡
RTMDet 选择不引入额外的连接,而是改变 Backbone 与 Neck 间参数量的配比。该配比是通过手动调整 Backbone 和 Neck 的 expand_ratio 参数来实现的,其数值在 Backbone 和 Neck 中都为 0.5。expand_ratio 实际上是改变 CSPLayer 中各层通道数的参数。
实验发现,当 Neck 在整个模型中的参数量占比更高时,延时更低,且对精度的影响很小。
(5)Head
传统的 YOLO 系列都使用同一 Head 进行分类和回归。RTMDet 参考了 NAS-FPN 中的做法,使用了 SepBNHead,在不同层之间共享卷积权重,但是独立计算 BN 的统计量。
3. 正负样本匹配策略
正负样本匹配策略或者称为标签匹配策略(Label Assignment)是目标检测模型训练中最核心的问题之一, 更好的标签匹配策略往往能够使得网络更好学习到物体的特征以提高检测能力。
早期的样本标签匹配策略一般都是基于空间以及尺度信息的先验来决定样本的选取。 典型案例如下:
- FCOS 中先限定网格中心点在 GT 内筛选后然后再通过不同特征层限制尺寸来决定正负样本
- RetinaNet 则是通过 Anchor 与 GT 的最大 IOU 匹配来划分正负样本
- YOLOV5 的正负样本则是通过样本的宽高比先筛选一部分, 然后通过位置信息选取 GT 中心落在的 Grid 以及临近的两个作为正样本
但是上述方法都是属于基于先验的静态匹配策略, 就是样本的选取方式是根据人的经验规定的,不会随着网络的优化而进行自动优化选取到更好的样本, 近些年涌现了许多优秀的动态标签匹配策略:
- OTA 提出使用 Sinkhorn 迭代求解匹配中的最优传输问题
- YOLOX 中使用 OTA 的近似算法 SimOTA , TOOD 将分类分数以及 IOU 相乘计算 Cost 矩阵进行标签匹配等等
这些算法将 预测的 Bboxes 与 GT 的 IOU 和 分类分数 或者是对应 分类 Loss 和 回归 Loss 拿来计算 Matching Cost 矩阵再通过 top-k 的方式动态决定样本选取以及样本个数。通过这种方式, 在网络优化的过程中会自动选取对分类或者回归更加敏感有效的位置的样本, 它不再只依赖先验的静态的信息, 而是使用当前的预测结果去动态寻找最优的匹配, 只要模型的预测越准确, 匹配算法求得的结果也会更优秀。但是在网络训练的初期, 网络的分类以及回归是随机初始化, 这个时候还是需要 先验 来约束, 以达到 冷启动 的效果。
RTMDet 作者也是采用了动态的 SimOTA 做法,不过其对动态的正负样本分配策略进行了改进。 之前的动态匹配策略往往使用与 Loss 完全一致的代价函数作为匹配的依据,但经过实验发现这并不一定是最优的。 使用更多 Soften 的 Cost 以及先验,能够提升性能。
(1)bbox编解码
RTMDet 的编码器将 gt bboxes 的左上角与右下角坐标 $(x_1, y_1, x_2, y_2)$ 编码为 中心点距离四边的距离 (top, bottom, left, right),并且解码至原图像上。
(2)匹配策略
RTMDet 提出了 Dynamic Soft Label Assigner 来实现标签的动态匹配策略, 该方法主要包括使用位置先验信息损失、样本回归损失、样本分类损失,同时对三个损失进行了 Soft 处理进行参数调优, 以达到最佳的动态匹配效果。
位置先验信息损失(Soft_Center_Prior):
\[C_{center} = \alpha^{|x_{pred}-x_{gt}|-\beta}\]# 计算gt与anchor point的中心距离并转换到特征图尺度
distance = (valid_prior[:, None, :2] - gt_center[None, :, :]
).pow(2).sum(-1).sqrt() / strides[:, None]
# 以10为底计算位置的软化损失,限定在gt的6个单元格以内
soft_center_prior = torch.pow(10, distance - 3)
样本回归损失(IOU_Cost):
\[C_{reg} = -\log(IOU)\]# 计算回归 bboxes 和 gts 的 iou
pairwise_ious = self.iou_calculator(valid_decoded_bbox, gt_bboxes)
# 将 iou 使用 log 进行 soft , iou 越小 cost 更小
iou_cost = -torch.log(pairwise_ious + EPS) * 3
样本分类损失(Soft_Cls_Cost):
\[C_{cls} = CE(P,Y_{soft}) *(Y_{soft}-P)^2\]# 生成分类标签
gt_onehot_label = (
F.one_hot(gt_labels.to(torch.int64),
pred_scores.shape[-1]).float().unsqueeze(0).repeat(
num_valid, 1, 1))
valid_pred_scores = valid_pred_scores.unsqueeze(1).repeat(1, num_gt, 1)
# 不单单将分类标签为01,而是换成与 gt 的 iou
soft_label = gt_onehot_label * pairwise_ious[..., None]
# 使用 quality focal loss 计算分类损失 cost ,与实际的分类损失计算保持一致
scale_factor = soft_label - valid_pred_scores.sigmoid()
soft_cls_cost = F.binary_cross_entropy_with_logits(
valid_pred_scores, soft_label,
reduction='none') * scale_factor.abs().pow(2.0)
soft_cls_cost = soft_cls_cost.sum(dim=-1)
通过计算上述三个损失的和得到最终的 cost_matrix 后, 再使用 SimOTA 决定每一个 GT 匹配的样本的个数并决定最终的样本。具体操作如下所示:
- 首先通过自适应计算每一个 gt 要选取的样本数量: 取每一个 gt 与所有 bboxes 前 13 大的 iou, 得到它们的和取整后作为这个 gt 的 样本数目 , 最少为 1 个, 记为 dynamic_ks。
- 对于每一个 gt , 将其 cost_matrix 矩阵前 dynamic_ks 小的位置作为该 gt 的正样本。
- 对于某一个 bbox, 如果被匹配到多个 gt 就将与这些 gts 的 cost_marix 中最小的那个作为其 label。
在网络训练初期,因参数初始化,回归和分类的损失值 Cost 往往较大, 这时候 IOU 比较小, 选取的样本较少,主要起作用的是 Soft_center_prior 也就是位置信息,优先选取位置距离 GT 比较近的样本作为正样本,这也符合人们的理解,在网络前期给少量并且有足够质量的样本,以达到冷启动。
当网络进行训练一段时间过后,分类分支和回归分支都进行了一定的优化后,这时 IOU 变大, 选取的样本也逐渐增多,这时网络也有能力学习到更多的样本,同时因为 IOU_Cost 以及 Soft_Cls_Cost 变小,网络也会动态的找到更有利优化分类以及回归的样本点。
(3)损失函数设计
参与 Loss 计算的共有两个值:loss_cls 和 loss_bbox,其中loss_cls采用QualityFocalLoss,loss_bbox采用GIoULoss;权重比例是:loss_cls : loss_bbox = 1 : 2。
QualityFocalLoss将离散标签的 focal loss 泛化到连续标签上,将 bboxes 与 gt 的 IoU 作为分类分数的标签,使得分类分数为表征回归质量的分数。
\[{QFL}(\sigma) = -|y-\sigma|^\beta((1-y)\log(1-\sigma)+y\log(\sigma))\]GIoU Loss 用于计算两个框重叠区域的关系,重叠区域越大,损失越小,反之越大。而且 GIoU 是在 $[0,2]$ 之间,因为其值被限制在了一个较小的范围内,所以网络不会出现剧烈的波动,证明了其具有比较好的稳定性。
(4)推理过程

- 特征图输入:预测的图片输入大小为 640 x 640, 通道数为 3 ,经过 CSPNeXt, CSPNeXtPAFPN 层的 8 倍、16 倍、32 倍下采样得到 80 x 80, 40 x 40, 20 x 20 三个尺寸的特征图。以 rtmdet-l 模型为例,此时三层通道数都为 256,经过 bbox_head 层得到两个分支,分别为 rtm_cls 类别预测分支,将通道数从 256 变为 80,80 对应所有类别数量; rtm_reg 边框回归分支将通道数从 256 变为 4,4 代表框的坐标。
- 初始化网格:根据特征图尺寸初始化三个网格,大小分别为 6400 (80 x 80)、1600 (40 x 40)、400 (20 x 20),表示当前特征层的网格点数量,最后一个维度是 2,为网格点的横纵坐标。
- 维度变换:经过 _predict_by_feat_single 函数,将从 head 提取的单一图像的特征转换为 bbox 结果输入,之后分别遍历三个特征层,分别对 class 类别预测分支、bbox 回归分支进行处理。以第一层为例,对 bbox 预测分支 [ 4,80,80 ] 维度变换为 [ 6400,4 ],对类别预测分支 [ 80,80,80 ] 变化为 [ 6400,80 ],并对其做归一化,确保类别置信度在 0 - 1 之间。
- 阈值过滤:先使用一个 nms_pre 操作,先过滤大部分置信度比较低的预测结果(比如 score_thr 阈值设置为 0.05,则去除当前预测置信度低于 0.05 的结果),然后得到 bbox 坐标、所在网格的坐标、置信度、标签的信息。经过三个特征层遍历之后,分别整合这三个层得到的的四个信息放入列表中。
- 还原到原图尺度:最后将网络的预测结果映射到整图当中,得到 bbox 在整图中的坐标值。
- NMS:进行 nms 操作,最终预测得到的返回值为经过后处理的每张图片的检测结果,包含分类置信度、框的labels、框的四个坐标。