StyleGAN:一种基于风格的生成器结构.
StyleGAN整体采用PGGAN的渐进式学习过程,从低分辨率图像开始生成,通过向网络中添加新的层逐步增加生成图像的分辨率。通过这种渐进训练能够控制图像的不同层次视觉特征,然而PGGAN没有显示地控制这些特征,因此控制所生成图像的特定特征的能力非常有限。StyleGAN在此基础上为每一个层次的生成模块引入了AdaIN,能够控制图像的不同视觉特征。

StyleGAN通过一系列改进,提高了生成图像的质量:
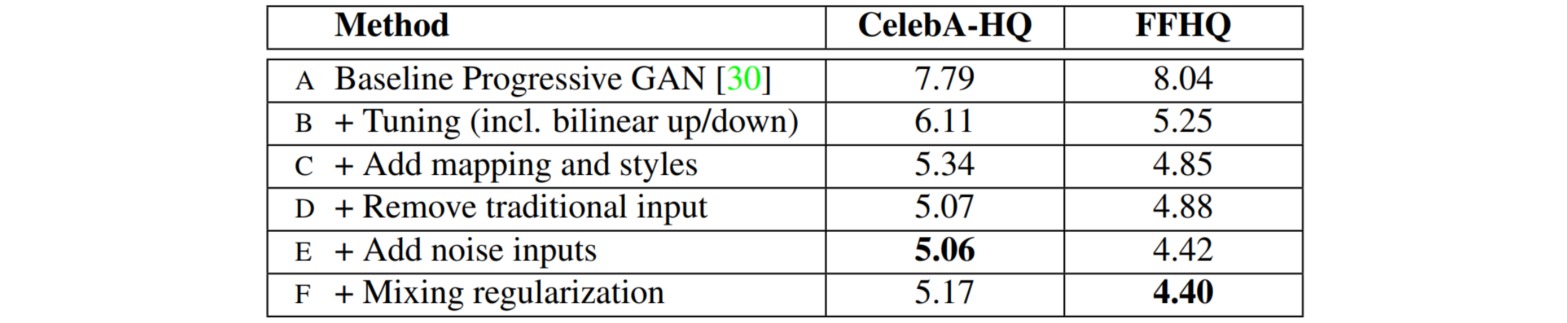
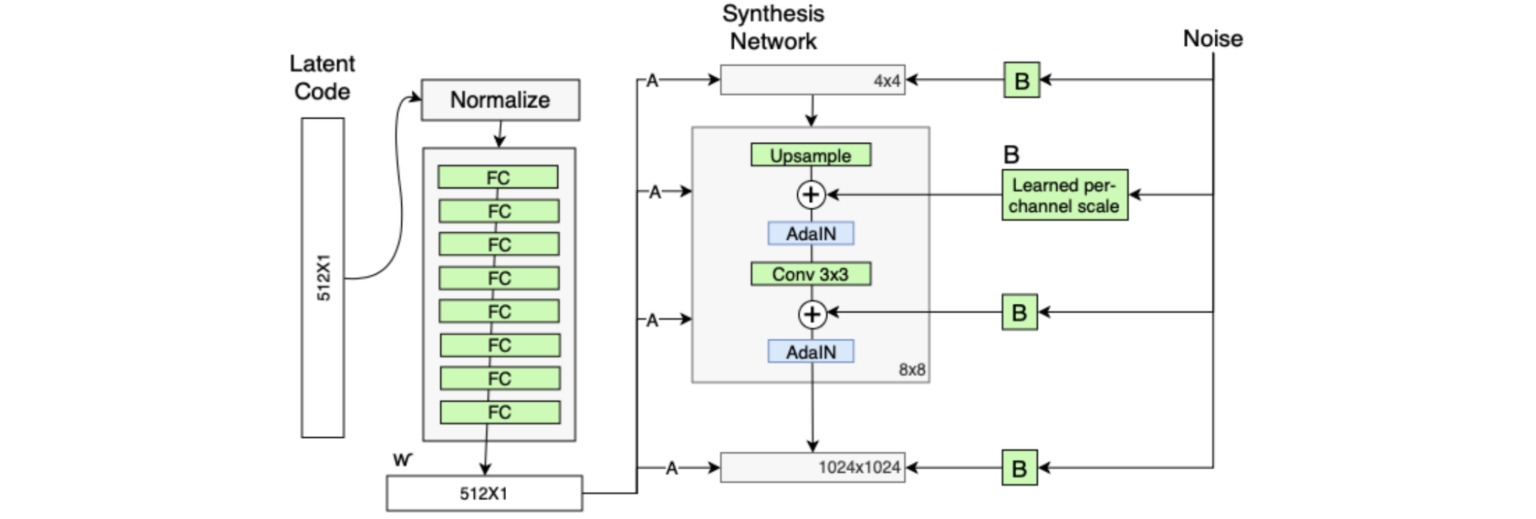
1. 增加映射和风格 Add mapping and styles
在GAN中,输入随机噪声$z$的分布被用作真实图像的隐变量分布。由于从常用的正态噪声中采样可能生成训练数据集中不曾出现的特征组合,因此有必要对特征进行解耦。

StyleGAN引入映射网络(mapping network)对隐空间$z$进行特征解耦,映射网络通过八层全连接层实现,网络输出$w$与输入$z$具有相同的尺寸($512$)。

通过加入映射网络,把输入噪声向量$z$编码为中间向量$w$,使得该控制向量的不同维度元素能够控制不同的视觉特征。
向量$w$通过一个可学习的仿射变换(一个全连接层)变为每一个AdaIN层的仿射参数$\gamma,\beta$,从而参与影响生成器的生成过程。

2. 移除传统输入 Remove traditional input
StyleGAN中生成图像的特征是通过映射网络和生成器中的AdaIN实现的,因此生成器的初始输入可以被忽略,并用常量值替代。
使用常量值输入可以降低由于初始输入取值不当而导致生成图像异常的概率,并且有助于减少特征纠缠,使得网络的特征只从映射网络的输入$w$中学习。

3. 增加噪声输入 Add noise input
生成图像中的许多小特征是随机的,比如人脸图像中雀斑、发髻线的准确位置、皱纹。通过向网络中引入随机噪声能够使得生成图像更逼真,具有多样性。StyleGAN向AdaIN模块的输入特征的每个通道添加一个缩放过的噪声,控制噪声仅影响图像中的细节变化(主要特征风格仍从映射网络学习)。
4. 混合正则化 Mixing regularization
StyleGAN通过混合正则化增强了网络对生成图像的风格控制能力。具体地,在训练时随机构造两个噪声向量$z_1,z_2$,通过映射网络编码为中间向量$w_1,w_2$。用第一个中间向量$w_1$作为生成器的一些层级的特征输入,用另一个中间向量$w_2$作为生成器的其他层级的特征输入。
通过混合正则化,生成器能够以一种连贯的方式来组合多个图像风格。下图给出了分别使用中间向量$w_1$和$w_2$生成的图像A和B以及混合两个中间向量生成的组合图像。
- Coarse styles from source B:低分辨率(4x4 - 8x8)的网络部分使用B的向量$w_2$,其余使用A的向量$w_1$, 可以看到组合图像的身份特征随B,但是肤色等细节随A;
- Middle styles from source B:中等分辨率(16x16 - 32x32)的网络部分使用B的向量$w_2$,此时生成图像不再具有B的身份特性,发型、姿态等都发生改变,但是肤色等细节依然随A;
- Fine from B:高分辨率(64x64 - 1024x1024)的网络部分使用B的向量$w_2$,此时主体身份特征随A,肤色等细节随B。

通过分析组合图像,作者发现StyleGAN能够控制三种不同的视觉特征:
- 粗糙的:分辨率不超过8x8,影响姿势、一般发型、面部形状等主体特征;
- 中等的:分辨率为16x16 - 32x32,影响面部特征、发型、眼睛的睁闭等;
- 高质的:分辨率为64x64 - 1024x1024,影响更精细的颜色(眼睛、头发和皮肤)和微观特征。
5. 微调 Tune
StyleGAN采用了一种中间向量$w$的截断技巧,防止生成器生成具有低概率密度的图像(通常视觉效果比较差)。通过下式迫使$w$保持接近“平均”的中间向量\(\overline{w} = \Bbb{E}_{z \text{~} P(z)}[f(x)]\):
\[w' = \overline{w} + \psi(w-\overline{w})\]压缩倍数$\psi$定义了图像与“平均”图像的差异量(以及输出的多样性)。$\psi$的绝对值越小,则生成图像越接近平均图像。

对模型进行训练之后,通过选择多个随机的输入噪声$z$,用映射网络生成它们的中间向量$w$,并计算这些向量的平均值$\overline{w}$。当生成新的图像时,不直接使用映射网络的输出$w$,而是使用$\overline{w}$。
此外,StyleGAN把图像的采样过程从最近邻采样调整为为双线性采样;并针对不同的数据集调整了网络的训练持续时间和损失函数,比如CelebA-HQ数据集中使用WGAN-GP作为损失函数,而FFHQ数据集则使用NSGAN损失函数。


