软锚框-点目标检测.
anchor-free检测器展现出了精度、速度均超越anchor-based检测器的巨大潜力。作者认为阻碍anchor-free检测器中的anchor-point检测器达到SOTA性能的主要原因是无效的训练。
目前针对anchor-point检测器的训练策略有两个被忽视的问题:
- 注意力偏差(attention bias):由于训练过程中anchor-point特征不对齐的影响,具有良好视野的目标往往会获得更多的注意力,这导致了其他目标容易被忽略。
- 特征选择(feature selection):启发式地对目标进行特征level分配或者每个目标仅限于一个level,这都会导致特征利用不足。
这些问题启发作者提出了一个新颖的训练策略Soft Anchor-Point Detector(SAPD),该策略包含两个soften优化技巧:soft-weighted anchor points和soft-selected pyramid levels。首先设计了一个和检测器联合训练的元选择(meta-selection)网络,它的作用是为每个目标实例预测各个特征金字塔levels的软选择权重(soft selection weights)。然后对于正样本anchor point,会根据anchor point到对应目标中心点的距离以及它所属的特征金字塔level的软选择权重两个因素来调整该anchor point对整个网络损失的影响权重。

1. anchor-point detector
anchor-point检测器的backbone部分通常使用特征金字塔网络,每个金字塔level后接一个检测head的全卷积结构。特征金字塔的级别表示为$P_l$,其分辨率为输入图像尺寸$W×H$的$1/s_l$,其中$s_l=2^l$是特征图stride,$l$的典型范围为$3$~$7$。检测head包含分类子网络和定位子网络,分类子网络在每个anchor-point位置处预测目标属于$K$个类别的概率,定位子网络为每个positive anchor-point预测类别无关的目标bbox。
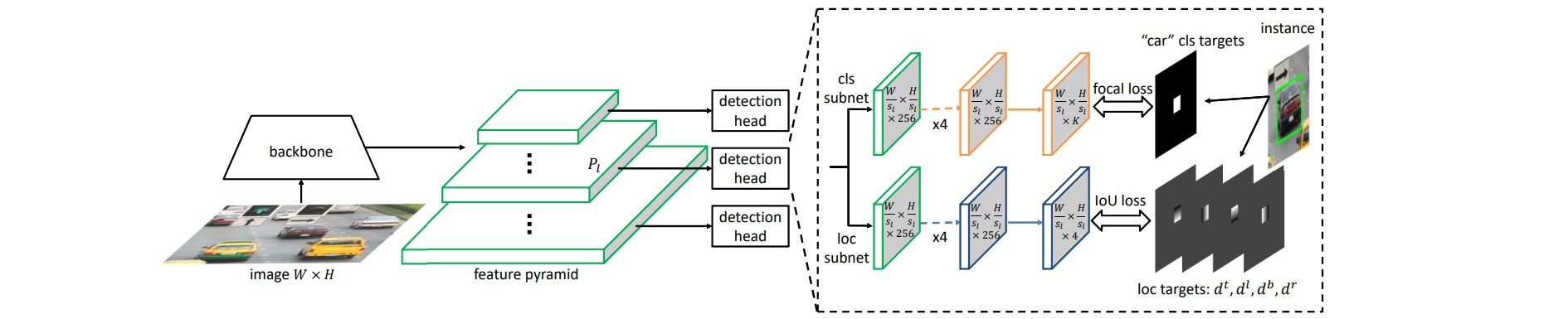
一个anchor point $p_{l_{i,j}}$ 是金字塔特征图$P_l$上位置$(i,j)$处的像素点(对应图像空间位置$(X_{l_{i,j}},Y_{l_{i,j}})$),anchor point $p_{l_{i,j}}$ 是positive的:当且仅当目标的GT box 被分配到特征层级$P_{l}$上,且图像空间位置$(X_{l_{i,j}},Y_{l_{i,j}})$在GT box内。否则这个anchor point就是negative的。
2. Soft-Weighted Anchor Points
在自然图像中,可能会出现遮挡、背景混乱等干扰,原始的anchor-point 检测器在处理这些具有挑战性的场景时存在注意力偏差问题,即具有清晰明亮视角的目标会生成过高的得分区域,从而抑制了周围的其他目标的得分区域。
下图可视化了一个attention bias的例子, 这张图包含了5个足球运动员,分类输出的得分图score map如图b所示。在热图中,靠前的两个运动员生成了两个高得分的很大的主导区域,而这两个大的主导区域倾向于向其他运动员对应的热图区域扩展。在更坏的情况下,主导区域(优势区域)甚至可能会覆盖代表性不足的区域,这导致了检测器仅将注意力集中在靠前的实例上,从而抑制了背景区域实例的检测。

这个问题是由于特征不对齐导致了靠近目标边界的位置会得到不必要的高分所导致的。接近边界的anchor points得不到与实例良好对齐的特征:它们的特征往往会受到实例外围的背景信息所干扰,因为它们的感受野包含了太多的背景信息,导致了特征表达能力减弱。因此不应该给予那些接近实例中心的anhor points和接近实例边界的anchor points 相同的权重。
为了解决注意力偏差问题,作者提出了一个soft-weighting方案,基本思想是为每一个anchor point $p_{l_{i,j}}$ 赋以权重 $w_{l_{i,j}}$。对于每一个positive anchor point,该权重大小取决于其图像空间位置到对应实例中心的距离,距离越大,权重就越低。因此,远离目标(实例)中心的anchor point被抑制,注意力会更集中于接近目标中心的anchor point。对于negative anchor points,所有的权重都被设置为1,维持不变。
3. Soft-Selected Pyramid Levels
与anchor-based检测器不同的是,anchor-free方法在为目标实例选择特征金字塔级别时不受anchor匹配的约束。换句话说,在anchor-free检测器的训练过程中,可以为每个实例分配任意一个/多个金字塔级别。同时选择正确的特征级别会带来很大的增益。
通过研究特征金字塔的属性来解决特征选择的问题,实际上,来自不同特征金字塔级别的特征图(尤其是相邻级别的)彼此之间有些相似。下图可视化了所有金字塔级别的响应,事实证明如果在某个特征金字塔级别中某个区域被激活,则在相邻级别的相同区域也可能以相似的方式被激活。但是这种相似性随着金字塔级别差的增大而减弱,这意味着多个金字塔级别的特征可以共同为某个目标的检测做出贡献,但不同级别的特征的贡献应该有所不同。

基于上述分析,在选择特征金字塔级别时应该遵循两个原则。
- 金字塔级别的选择应该遵循特征响应的模式,而不是以某些启发式的方法进行。与目标相关的损失可以很好的反应一个金字塔级别是否适合用来检测某些目标。
- 对于某个目标的检测,应该允许多个级别的特征共同参与到训练和测试中,同时每个级别的贡献应有所不同。
对于每个目标实例,应该重新加权各个金字塔级别。换句话说,对每个特征金字塔级别,都根据特征响应来为其分配不同的权重,这是一种soft的选择方式。这也可以看做是将一个目标实例的一部分分配给某个级别。本文训练一个meta-selection网络来预测各个金字塔级别的权重用于软特征选择。网络的输入是从所有金字塔级别上提取的实例相关的特征响应,具体实现方案是使用RoIAlign层对每个级别的特征进行映射,然后再串联起来,其中RoI是目标实例的GT box。接着concated的特征输入到meta-selection网络中,输出概率分布向量,该概率分布就作为软特征选择的各级别权重。

这个轻量级meta-selection网络只包含3个的3×3卷积层(无padding、relu激活)和一个带有softmax的全连接层。这个网络和整个检测器联合训练,训练时使用交叉熵损失函数,GT是一个one-hot向量,它指示哪个特征金字塔级别的损失最小。


