通过自适应训练样本选择弥补基于Anchor和无Anchor检测之间的差距.
本文作者试图分析问题:anchor-free和anchor-base算法的本质区别是什么?为了找出本质区别,采用了anchor-base经典算法retinanet以及anchor-free经典算法FCOS来说明。
- 对于anchor-free典型算法FCOS,希望消除回归范围regress_ranges和中心扩展比例参数center_sample_radius这两个核心超参,使其在anchor-free领域变成真正的自适应算法
- 对于anchor-base经典算法retinanet,希望借鉴fcos的正负样本分配策略思想来弥补和fcos的性能差异,同时也能够自适应,无须设置正负样本阈值
由于FCOS是基于point进行预测,可以认为就是一个anchor,为了公平对比,将retinanet的anchor也设置为1个。此时两个算法的本质区别在于正负样本的定义不同。将FCOS的训练策略移动到retinanet上面,可以发现性能依然低于fcos 0.8mAP。

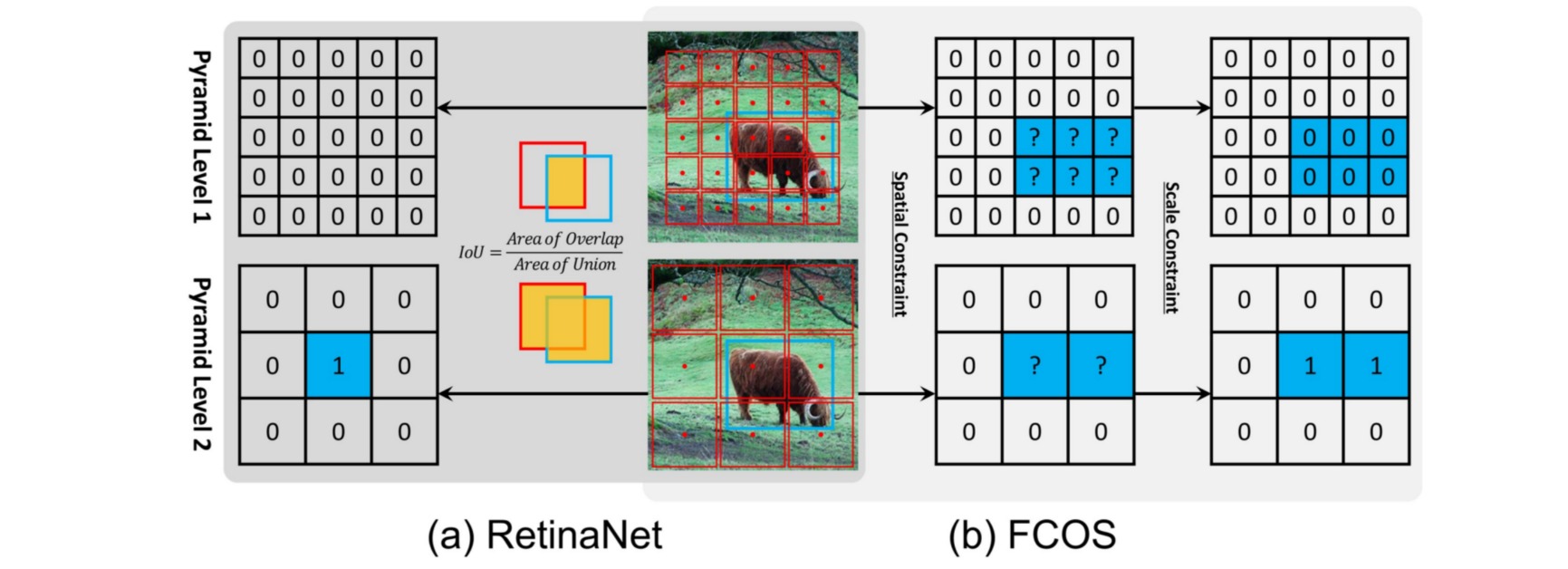
retinanet和fcos这两个算法都是多尺度预测的,故其正负样本定义策略都包括两个步骤:gt分配给哪一层负责预测;gt分配给哪一个位置anchor负责预测。
retinanet完全依靠统一的iou来决定哪一层哪一个位置anchor负责预测;而fcos显式的分为两步:先利用scale ratio来确定gt分配到哪一层,然后利用center sampling策略来确定哪些位置是正样本。
这两种操作的细微差别会导致如下情形:对于1和2两个输出预测层,retinanet采用统一阈值iou,可以确定图中蓝色1位置是正样本;而对于fcos来说,有2个蓝色1,表明fcos的定义方式会产生更多的正样本区域。这种细微差距就会导致retinanet的性能比fcos低一些。
fcos的正负样本定义规则优于retinanet,但是fcos的定义规则存在两个超参:多尺度输出回归范围regress_ranges用于限制每一层回归的数值范围;中心扩展因子center_sample_radius用于计算每个输出层哪些位置属于正样本区域。这两个超参在不同的数据集上面可能要重新调整,而且不一定好设置。本文提出了ATSS(Adaptive Training Sample Selection)方法,希望消除这两个超参,达到自适应的功能。
ATSS方法的基本流程如下:
- 计算每个gt bbox和多尺度输出层的所有anchor的iou
- 计算每个gt bbox中心和多尺度输出层的所有anchor中心的l2距离
- 对于任何一个输出层,遍历每个gt,找出topk(默认是$9$)个最小l2距离的anchor点。假设一共有l个输出层,那么对于任何一个gt bbox,都会挑选出topk×l个候选位置
- 对于每个gt bbox,计算所有候选位置iou的均值和标准差,两者相加得到该gt bbox的阈值
- 对于每个gt bbox,选择出候选位置中iou大于阈值的位置,该位置认为是正样本,负责预测该gt bbox
- 如果topk参数设置过大,可能会导致某些正样本位置不在gt bbox内部,故需要过滤掉这部分正样本,设置为背景样本
均值(所有层的候选样本算出一个均值)代表了anchor对gt衡量的普遍合适度,其值越高,代表候选样本质量普遍越高,iou也就越大;而标准差代表哪一层适合预测该gt bbox,标准差越大越能区分层和层之间的anchor质量差异。均值和标准差相加就能够很好的反应出哪一层的哪些anchor适合作为正样本。一个好的anchor设计,应该是满足高均值、高标准差的设定。topk参数设置原则应该是在不要引入大量低质量回归正样本的前提下应该尽量提高该阈值。



